r语言实现关联分析--关联规则挖掘(Apriori算法) (r语言预测学习笔记)
r语言实现关联分析–关联规则挖掘
关联分析:
引子:
我们一般把一件事情发生,对另一间事情也会产生影响的关系叫做关联。而关联分析就是在大量数据中发现项集之间有趣的关联和相关联系(形如“由于某些事件的发生而引起另外一些事件的发生”)。 我们的生活中有许多关联,一个典型例子是购物篮分析。该过程通过发现顾客放入其购物篮中的不同商品之间的联系,分析顾客的购买习惯。通过了解哪些商品频繁地被顾客同时购买,这种关联的发现可以帮助零售商制定营销策略。其他的应用还包括价目表设计、商品促销、商品的排放和基于购买模式的顾客划分。
关联分析的基本概念:
关联规则是指形如 x→y 的形式,x 和 y 分别成为关联规则的 前项 和 后项。关联规则挖掘的数据是事务数据集,它包含事务ID和项的子集两个属性。(类似下面的数据框)

根据上面的数据介绍一些关联分析涉及到的基本概念
项集:包含0个或多个项的集合,例如{A、B},含有k个项就是k-项集。
关联规则:形如A→B的关联,其中A∩B非空。
支持度计数:包含特定项集的个数,由示例可知 σ(A→B)=2 表示同时包含AB的项集数为2.
支持度:包含特定项集的个数占总项集数的比值。
频繁项集:满足最小支持度的所有项集
置信度:用条件概率表示,c(A→B)=p(A|B) A发生的条件下B发生的概率.
期望置信度:在没有任何条件影响的情况下,事件A出现的概率
提升度:关联规则A→B下 A事件发生对B事件产生的影响程度
关联分析有两个目标:
1.发现频繁项集(频繁项集是满足最小支持度要求的项集,它给出经常在一起出现的元素项)
2.发现关联规则(关联规则意味着元素项之间“如果…那么…”的关系)
常用的关联规则挖掘算法有Aprior算法
Apriori算法是一种最有影响的挖掘布尔关联规则频繁项集的算法。其核心是基于两阶段频集思想的递推算法。Apriori算法可挖掘出关联规则
Apriori算法
Apriori定律1:如果某个项集是频繁的,那么它的所有子集也是频繁的
Apriori定律2:如果某个项集是非频繁的,那么它的所有超集也是非频繁的
Apriori定律3:基于此,Apriori算法从单元素项集开始,通过组合满足最小支持度的项集来形成更大的集合
两个步骤:1.通过迭代找出事务数据集中所有频繁项集,即支持度不低于设定阈值的项集。 2.利用频繁项集构造出满足用户最小置信度的关联准则,利用支持度对候选项集进行剪枝。
此处以示例事务数据集演示手动计算过程,设置最小支持度阈值minsup=0.3.从生成c1开始,到不能找到任何频繁k项集为止,过程如下所示。

在第一次扫描(1st scan)中,minsup=2,{D}不符合要求,因此剪掉,生成频繁1项集L1,L1自动链接生成候选2项集c2。L1中各项集只有一个项,因此两两组合。后面的操作与第一步操作类似。
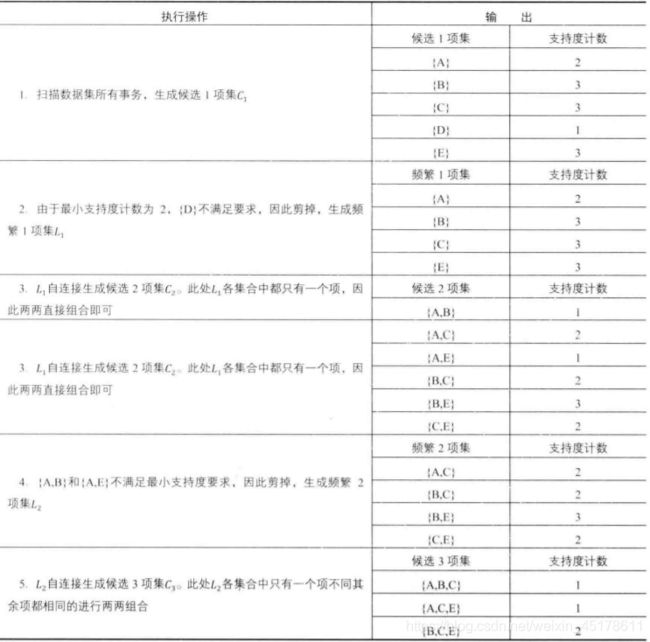

最终得到的频繁项集 L3={B、C、E} 它的任何2项子集都是频繁的。
此时便达到了关联分析的第一个目标:发现频繁项集。接着要寻找(构造)关联规则
关联规则:对每个频繁项集L,产生L的非空真子集,对L的每个非空真子集S,若都能满足置信度大于等于给定的最小置信度的情况下,即C(S→CS)≧min-conf,(CS表示S在L中的补集),那么就是强关联规则。。
对于L3,它的非空自己为{B},{C},{E},{B,C},{B,E},{C,E},假设置信度min-conf=0.5,则获得的关联规则及置信度如下

可见,置信度都大于最小置信水平,说明得到的关联规则都是强关联规则。
Apriori算法流程图:

r语言实现Apriori算法
r语言中,arules包主要用于挖掘频繁项集和关联规则,该包中的apriori函数可以实现这个算法。
下面是函数定义及参数说明
函数定义:
apriori(data,parameter=NULL,appearance=NULL,control=NULL)




数据预处理(离散化数据):
这里使用AirPassengers数据集,将对应的乘客数据转化为环比值,
L<-NROW(AirPassengers)
ap.chain<-AirPassengers[2:L]/AirPassengers[1:(L-1)]
plot(ap.chain,pch=20)
lines(ap.chain)
abline(h=1.0,lty=2,col='red')

可以看出环比值围绕着1.0上下波动,并由一定的周期性
再进行离散化处理,将环比值按分布区间等分成4份。代码如下:
> ap.chain.dez<-cut(ap.chain,breaks=4,include.lowest=T)
> ap.chain.lab<-cut(ap.chain,breaks=4,include.lowest=T,labels=c("A","B","C","D"))
> out<-data.frame(dez=ap.chain.dez,lab=ap.chain.lab,chain=ap.chain)
> head(out)
dez lab chain
1 (1.02,1.14] C 1.0535714
2 (1.02,1.14] C 1.1186441
3 (0.913,1.02] B 0.9772727
4 (0.913,1.02] B 0.9379845
5 (1.02,1.14] C 1.1157025
6 (1.02,1.14] C 1.0962963
对下一周期预测时,需考虑近十期的环比情况,因此按十个月的窗口周期,重新构建数据集,使用
Apriori算法提取规则:
#构建数据集
>winSize=10
>conMatrix=t(mapply(function(i)ap.chain.lab[i:(i+winSize-1)],
1:(NROW(ap.chain)-winSize+1)))
#由于数据都是按时间先后顺序整理的,因此用前百分之八十提取规则,后百分之二十验证规则
>partVal<-round(dim(conMatrix)[1]*0.8,0)
>trainData<-data.frame(conMatrix[1:partVal,])
>validData<-conMatrix[(partVal+1):dim(conMatrix)[1],]
#使用Apriori提取规则
>library(arules)
>apriori.obj<-apriori(trainData,parameter=list(supp=0.1,conf=0.5,target="rules"),appearance=list(rhs=c("X10=A","X10=B","X10=C","X10=D"),default="lhs"))
>inspect(apriori.obj)
lhs rhs support confidence coverage lift count
[1] {X9=D} => {X10=B} 0.1028037 0.6111111 0.1682243 1.868254 11
[2] {X4=A} => {X10=B} 0.1308411 0.6086957 0.2149533 1.860870 14
[3] {X5=A} => {X10=B} 0.1401869 0.6521739 0.2149533 1.993789 15
[4] {X7=A} => {X10=C} 0.1121495 0.5217391 0.2149533 1.800842 12
[5] {X9=A} => {X10=A} 0.1214953 0.5652174 0.2149533 2.629490 13
[6] {X4=B,X9=A} => {X10=A} 0.1028037 0.9166667 0.1121495 4.264493 11
> inspect(apriori.obj[which.max(quality(apriori.obj)$lift)])
lhs rhs support confidence coverage lift count
[1] {X4=B,X9=A} => {X10=A} 0.1028037 0.9166667 0.1121495 4.264493 11
由代码所示,insepct函数可查看计算得出的结果,包含三个属性,分别是支持度,置信度和提升度,其中支持度最高的一条规则是 {X4=B,X9=A} => {X10=A} ,我们通过验证集validData进行验证
> rulesData=as(apriori.obj,"data.frame")
> rulesData[which.max(rulesData$lift),]
rules support confidence coverage lift count
6 {X4=B,X9=A} => {X10=A} 0.1028037 0.9166667 0.1121495 4.264493 11
> tmp<-validData[validData[,4]=='B' & validData[,9]=='A',10]
> hitRate<-paste(NROW(tmp=='A')/NROW(tmp)*100,"%",sep="")
> hitRate
[1] "100%"
可以看出此条规则对未来20个月的预测全部命中。例如若要预测1960年11月的环比值,根据规则,当同年5月环比值1.02位于【0.913,1.02】区间,并且同年十月环比值0.91位于【0.8,0.913】区间时,则可以有效预测11月份环比值介于0.8~0.913之间。
缺:关联分析可视化