机器学习入门系列03,Error的来源:偏差和方差(bias 和 variance)
Gitbook整理地址:https://yoferzhang.gitbooks.io/machinelearningstudy/content/20170327ML03BiasAndVariance.html
回顾
第二篇中神奇宝贝的例子:
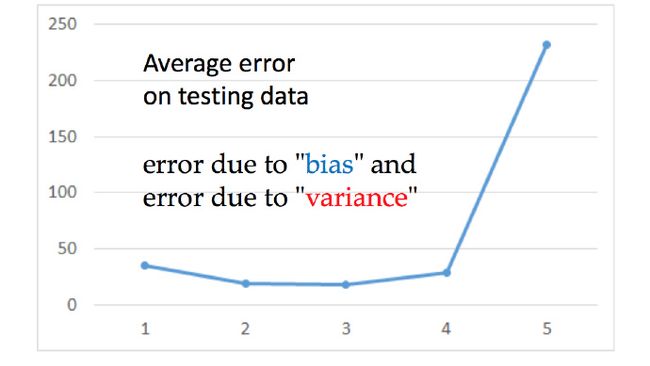
可以看出越复杂的model 再测试集上的性能并不是越好
这篇要讨论的就是 error 来自什么地方?
error主要的来源有两个,bias(偏差) 和 variance(方差)
估测
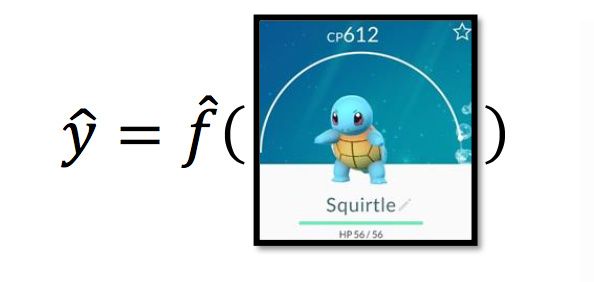
假设上图为神奇宝贝cp值的真正方程,当然这只有Niantic(制作《Pokemon Go》的游戏公司)知道。从训练集中可以找到真实方程 f̂ 的近似方程 f∗ 。
估测bias 和 variance
估测变量 x 的平均值
- 假设 x 的平均值为 μ ,方差为 σ2
估测平均值怎么做呢?
- 首先拿到N个样品点: x1,x2,…,xN
- 计算平均值得到 m , m=1N∑nxn≠μ

但是如果计算很多组的m ,然后求m的期望
这个估计呢是无偏估计(unbiased)。
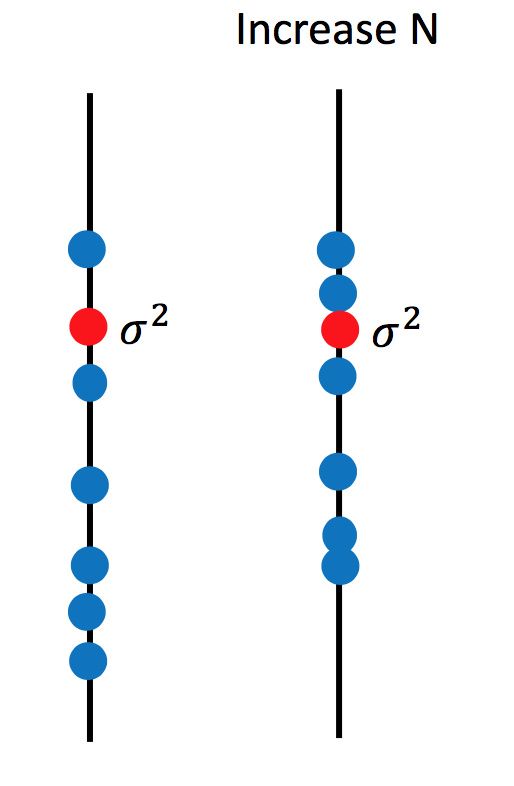
然后m分布对于 μ 的离散程度(方差):
这主要取决于N,下图可看出N越小越离散

估测变量 x 的方差
首先用刚才的方法估测m,
然后再做下面计算:
就可以用 s2 来估测 σ2
这个估计是有偏估计(biased),
求 s2 的期望值:
用靶心来说明一下bias和variance的影响
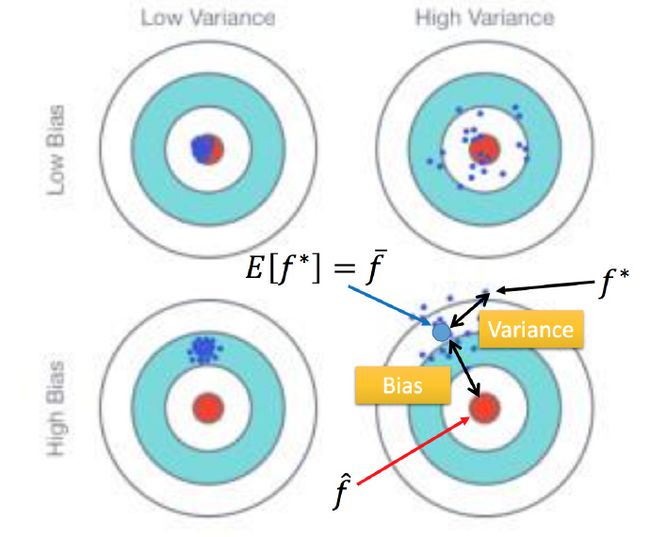
靶心为真正的方程 f̂ ,深蓝色点为 f∗ ,是实验求得的方程。求 f∗ 的期望值 f¯=E[f∗] ,即图中浅蓝色的点。
f¯ 和 f̂ 之间的距离就是误差 bias,而 f¯ 和 f∗ 之间的距离就是误差 variance。4幅图的对比观察两个误差的影响。
bias就是射击时瞄准的误差,本来应该是瞄准靶心,但bias就造成瞄准准心的误差;而variance就是虽然瞄准在 f¯ ,但是射不准,总是射在 f¯ 的周围。
为什么会有很多的 f∗ ?
讨论系列02中的案例:这里假设是在平行宇宙中,抓了不同的神奇宝贝
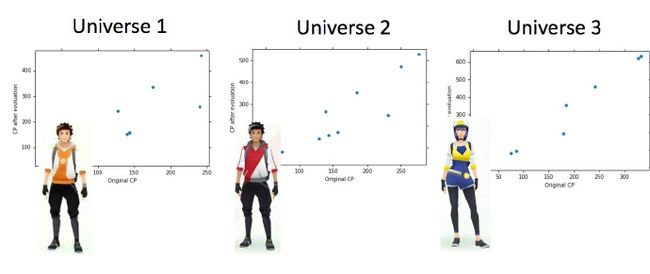
用同一个model,在不同的训练集中找到的 f∗ 就是不一样的

这就像在靶心上射击,进行了很多组(一组多次)。现在需要知道它的散布是怎样的,将100个宇宙中的model画出来
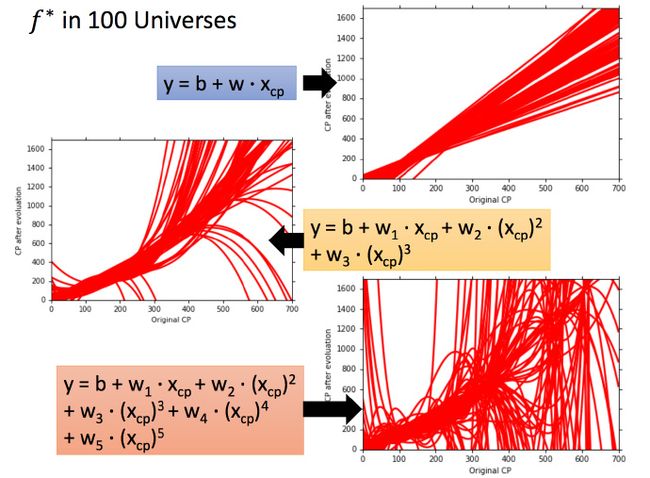
不同的数据集之前什么都有可能发生—||
考虑不同model的variance
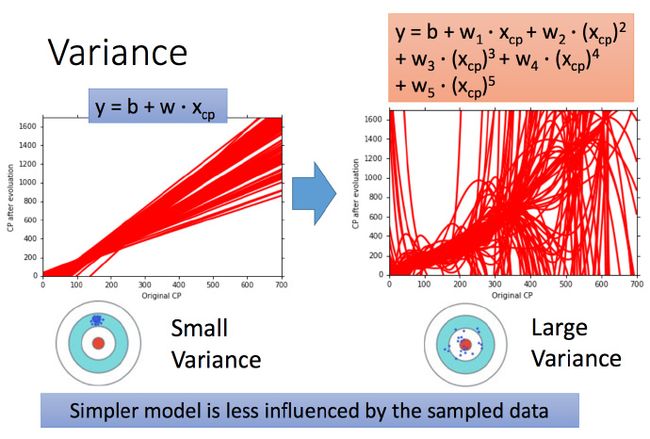
一次model的variance就比较小的,也就是是比较集中,离散程度较小。而5次model 的 variance就比较大,同理散布比较广,离散程度较大。
所以用比较简单的model,variance是比较小的(就像射击的时候每次的时候,每次射击的设置都集中在一个比较小的区域内)。如果用了复杂的model,variance就很大,散布比较开。
这也是因为简单的model受到不同训练集的影响是比较小的。
考虑不同model的 bias
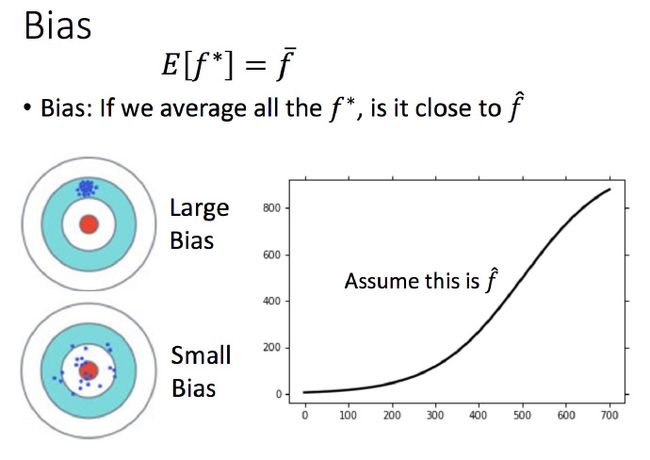
这里没办法知道真正的 f̂ ,所以假设图中的那条黑色曲线为真正的 f̂
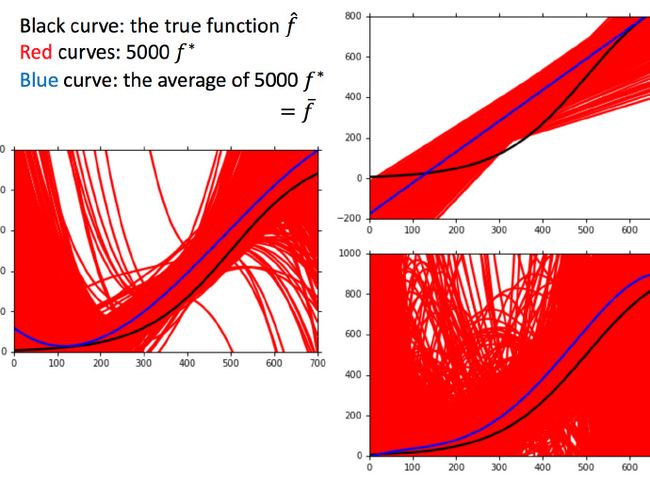
结果可视化,一次平均的 f¯ 没有5次的好,虽然5次的整体结果离散程度很高。
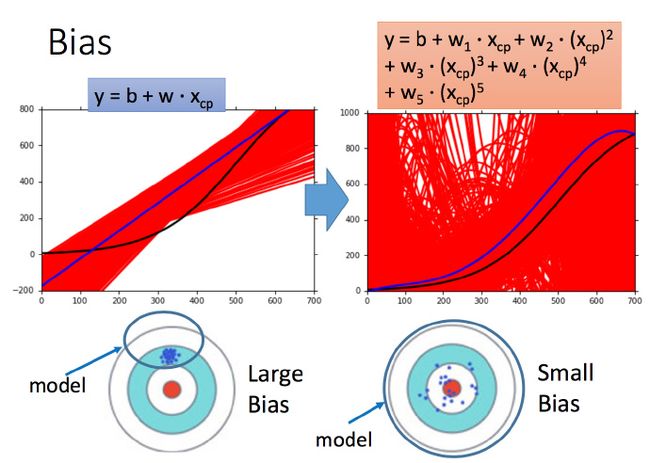
一次model的bias比较大,而复杂的5次model,bias就比较小。
直观的解释:简单的model函数集的space比较小,所以可能space里面就没有包含靶心,肯定射不中。而复杂的model函数集的space比较大,可能就包含的靶心,只是没有办法找到确切的靶心在哪,但足够多的,就可能得到真正的 f¯ 。
bias v.s. variance
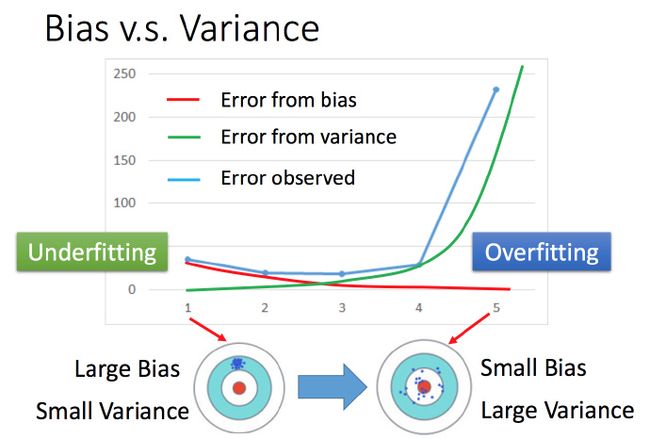
将系列02中的误差拆分为bias何variance。简单model(左边)是bias比较大造成的error,这种情况叫做 Underfitting(欠拟合),而复杂model(右边)是variance过大造成的error,这种情况叫做Overfitting(过拟合)。
怎么判断?
分析
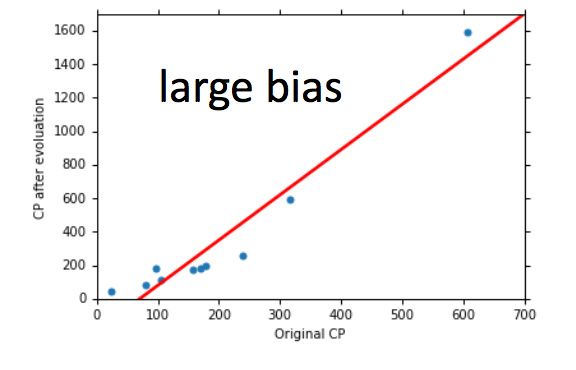
- 如果model没有很好的fit训练集,就是bias过大,也就是Underfitting
- 如果model很好的fit训练集,即再训练集上得到很小的error,但在测试集上得到大的error,这意味着model可能是variance比较大,就是Overfitting。
对于Underfitting和Overfitting,是用不同的方式来处理的
bias大,Underfitting
此时应该重新设计model。因为之前的函数集里面可能根本没有包含 f̂ 。可以:
- 将更多的feature加进去,比如考虑高度重量,或者HP值等等。
- 或者考虑更多次幂、更复杂的model。
如果此时强行再收集更多的data去训练,这是没有什么帮助的,因为设计的函数集本身就不好,再找更多的训练集也不会更好。
variance大,Overfitting
简单粗暴的方法:More data

但是很多时候不一定能做到收集更多的data。可以针对对问题的理解对数据集做调整(Regularization)。比如识别手写数字的时候,偏转角度的数据集不够,那就将正常的数据集左转15度,右转15度,类似这样的处理。
选择model
- 现在在bias和variance之间就需要一个权衡
- 想选择的model,可以平衡bias和variance产生的error,使得总error最小
- 但是下面这件事最好不要做:

用训练集训练不同的model,然后在测试集上比较error,model3的error比较小,就认为model3好。但实际上这只是你手上的测试集,真正完整的测试集并没有。比如在已有的测试集上error是0.5,但有条件收集到更多的测试集后通常得到的error都是大于0.5的。
Cross Validation(交叉验证)
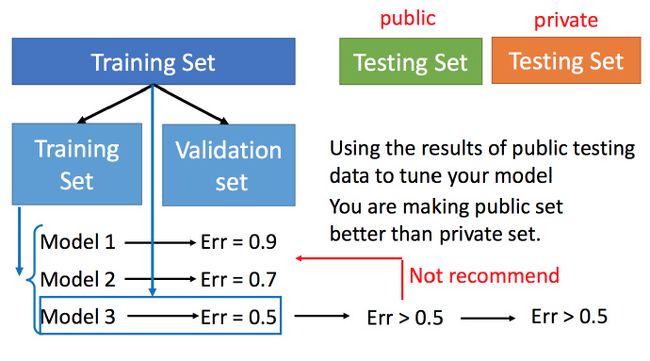
图中public的测试集是已有的,private是没有的,不知道的。Cross Validation 就是将训练集再分为两部分,一部分作为训练集,一部分作为验证集。用训练集训练model,然后再验证集上比较,确实出最好的model之后(比如model3),再用全部的训练集训练model3,然后再用public的测试集进行测试,此时一般得到的error都是大一些的。不过此时会比较想再回去调一下参数,调整model,让在public的测试集上更好,但不太推荐这样。(心里难受啊,大学数模的时候就回去调,来回痛苦折腾)
上述方法可能会担心将训练集拆分的时候分的效果比较差怎么办,可以用下面的方法。
N-fold Cross Validation(N-折交叉验证)
将训练集分成N份,比如分成3份。
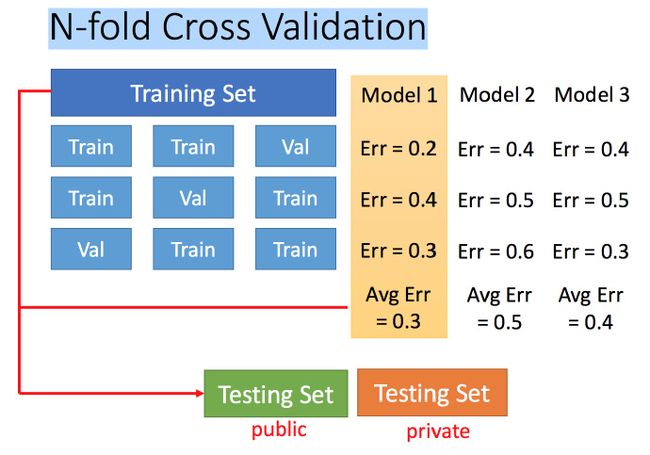
比如在三份中训练结果Average Error是model1最好,再用全部训练集训练model1。(貌似数模也干过,当年都是莫名其妙的分,想想当年数模的时候都根本来不及看是为什么,就是一股脑上去做00oo00)