机器学习 logistic回归的数学原理及Python简单实现
一、logistic回归的使用场景
在分类问题中,输出为离散值。如垃圾邮件过滤系统中,垃圾邮件预测值只能为是或否。线性回归适用于连续性变量的预测。而当添加一个新的与其他样本差异较大的样本时,回归曲线可能会变化较大。若输出值是离散的,要么0要么1,因此预测值很可能会剧烈变化,产生较大的误差。(连续变量变化不是太大,如从0.1变到0.2,但离散变量可能就从非垃圾邮件突然变垃圾邮件了,产生这个变化的原因仅仅是添加了一个差异较大的样本)因此通常情况分类问题不适合用线性回归拟合曲线。
二、logistic函数
分类问题的预测值不再适合用 h θ ( x ) h_\theta(x) hθ(x)= ∑ i = 1 i = m θ i x i \sum_{i=1}^{i=m} \theta_i x_i ∑i=1i=mθixi。以输出值只有0和1为例,选取预测函数为 h θ ( x ) h_\theta(x) hθ(x)= 1 1 + e − θ ^ T x \frac{1}{1+e^{-\hat\theta^Tx}} 1+e−θ^Tx1,此函数称为logistic函数,它的特点是当 θ T x \theta ^Tx θTx很小时,函数值趋于0,当 θ T x \theta ^Tx θTx = 0时函数值为0.5,当 θ T x \theta ^Tx θTx很大时函数值区域1。 θ T x \theta ^Tx θTx=0称为拐点,在这一点函数斜率最大。由于预测值是离散的,而logistic函数也是连续的,因此往往使用一个阈值,超过阈值时为1,未超过时为0,比如把阈值设为0.5,logistic函数值大于0.5,输出值预测为1,小于则预测为0。logistic函数对于这类离散输出的分类问题具有较好的拟合性,函数值始终在(0,1)开区间内,可以有效避免一个差异较大的样本对模型造成的干扰
三、logistic回归
logistic函数的损失函数常常用概率的形式进行计算。由于P{Yi=1}= h θ ( x i ) h_\theta (x_i) hθ(xi),yi只能取0或1,因此P{Yi=0}=1- h θ ( x i ) h_\theta(x_i) hθ(xi),用更简洁的写法就是P{Yi=yi}= h θ ( x i ) y i ( 1 − h θ ( x i ) ) 1 − y i h_\theta (x_i)^{y_i} (1-h_\theta(x_i))^{1-y_i} hθ(xi)yi(1−hθ(xi))1−yi,y=0或1
则样本集的似然性函数L( θ \theta θ)= ∏ i = 1 i = m P \prod_{i=1}^{i=m}P ∏i=1i=mP{Yi=yi}= ∏ i = 1 i = m h θ ( x i ) y i ( 1 − h θ ( x i ) ) 1 − y i \prod_{i=1}^{i=m} h_\theta (x_i)^{y_i} (1-h_\theta(x_i))^{1-y_i} ∏i=1i=mhθ(xi)yi(1−hθ(xi))1−yi,取对数后,ln(L( θ \theta θ)) = ∑ i = 1 i = m \sum_{i=1}^{i=m} ∑i=1i=m[ y i ∗ l n ( h θ ( x i ) ) + ( 1 − y i ) l n ( 1 − h θ ( x i ) y_i*ln(h_\theta(x_i))+(1-y_i)ln(1-h_\theta (x_i) yi∗ln(hθ(xi))+(1−yi)ln(1−hθ(xi)]由概率论与数理统计中对样本参数选择的最大似然性法则可知,应选择似然性最大的参数 θ ^ \hat\theta θ^
接下来,可以选择与梯度下降算法略有不同的梯度上升算法,即 θ i + 1 \theta_{i+1} θi+1= θ i \theta_i θi+ α ▽ l n ( L ( θ ) ) \alpha\triangledown{ln(L(\theta))} α▽ln(L(θ))来计算使得 l n ( L ( θ ) ) ln(L(\theta)) ln(L(θ))最大的参数 θ \theta θ,然后根据计算出的参数 θ \theta θ来计算检测点的预测值 h θ ( x ) h_\theta(x) hθ(x)= 1 1 + e − θ ^ T x \frac{1}{1+e^{-\hat\theta^Tx}} 1+e−θ^Tx1。其中, ▽ l n ( L ( θ ) ) \triangledown{ln(L(\theta))} ▽ln(L(θ))= [ ∂ l n ( L ( θ ) ) ∂ θ 1 ∗ θ ^ 1 ∣ θ ^ 1 ∣ , ∂ l n ( L ( θ ) ) ∂ θ 2 ∗ θ ^ 2 ∣ θ ^ 2 ∣ , . . . ∂ l n ( L ( θ ) ) ∂ θ n ∗ θ ^ n ∣ θ ^ n ∣ ] T [\frac{\partial ln(L(\theta))}{\partial \theta_1}*\frac{\hat\theta_1}{|\hat\theta_1|}, \frac{\partial ln(L(\theta))}{\partial \theta_2}*\frac{\hat\theta_2}{|\hat\theta_2|} , ... \frac{\partial ln(L(\theta))}{\partial \theta_n}*\frac{\hat\theta_n}{|\hat\theta_n|} ]^T [∂θ1∂ln(L(θ))∗∣θ^1∣θ^1,∂θ2∂ln(L(θ))∗∣θ^2∣θ^2,...∂θn∂ln(L(θ))∗∣θ^n∣θ^n]T ,而 ∂ l n ( L ( θ ) ) ∂ θ j \frac{\partial{ln(L(\theta))}}{\partial{}\theta_j} ∂θj∂ln(L(θ))化简后等于 ∑ i = 1 i = m ( y i − h θ ( x i ) ) x i j \sum_{i=1}^{i=m}(y_i-h_\theta(x_i))x_{ij} ∑i=1i=m(yi−hθ(xi))xij ,由此,logistic回归的预测函数 h θ ( x i ) h_\theta(x_i) hθ(xi)= 1 1 + e − θ ^ T x \frac{1}{1+e^{-\hat\theta^Tx}} 1+e−θ^Tx1与损失函数 J ( θ ) J(\theta) J(θ)=ln(L( θ \theta θ)) = ∑ i = 1 i = m \sum_{i=1}^{i=m} ∑i=1i=m[ y i ∗ l n ( h θ ( x i ) ) + ( 1 − y i ) l n ( 1 − h θ ( x i ) y_i*ln(h_\theta(x_i))+(1-y_i)ln(1-h_\theta (x_i) yi∗ln(hθ(xi))+(1−yi)ln(1−hθ(xi)]以及梯度公式均已得到。
四、一个简单的logistic回归预测
选择正态分布的二维特征进行回归预测
import numpy as np
import math
#用logistic计算h_\theta(x)
def sigmoid(inX):
return 1.0/(1+math.exp(-inX))
#生成数据
y1_x1_mu,y1_x1_sigma = 0,3#分类结果为1的y的x1的均值和方差
y1_x1 = np.random.normal(y1_x1_mu,y1_x1_sigma,20)#正态分布中取20个随机数
y1_x2_mu,y1_x2_sigma = 1,2#分类结果为1的y的x2的均值和方差
y1_x2 = np.random.normal(y1_x2_mu,y1_x2_sigma,20)
y1 = np.ones((20,1))
y0_x1_mu,y0_x1_sigma = 0,2#分类结果为0的y的x1的均值和方差
y0_x1 = np.random.normal(y0_x1_mu,y0_x1_sigma,20)
y0_x2_mu,y0_x2_sigma = 5,3
y0_x2 = np.random.normal(y0_x2_mu,y0_x2_sigma,20)
y0 = np.zeros((20,1))
x1 = list(y1_x1)#将y1_x1转为列表 方便合并
x1.extend(list(y0_x1))#在列表末尾添上另一个列表(合并)
x2 = list(y1_x2)
x2.extend(list(y0_x2))
y = list(y1)
y.extend(list(y0))
#梯度上升进行训练,得到合适的参数
#已有m=40个x1,x2,和y,前20个是y1后20个是y0
def gradAdcent(x1,x2,y):
if len(x1)!=40 or len(x2)!=40 or len(y)!=40:
print('parameter number error,it should be 40')
return
loss = 1
theta = [0,0]#2*1
step_size = 0.01#步长,alpha
iter_count = 0
max_iters = 100
while iter_count < max_iters:
loss = 1#似然性
gradient_0 = 0#第一维的梯度分量
gradient_1 = 0#第二维的梯度分量
#计算第一维的梯度分量
for i in range(0,40):
h_theta = sigmoid(x1[i]*theta[0]+x2[i]*theta[1])
gradient_0 += (y[i]-h_theta)*x1[i]
#计算第二维梯度分量
for i in range(0,40):
h_theta = sigmoid(x1[i]*theta[0]+x2[i]*theta[1])
gradient_1 += (y[i]-h_theta)*x2[i]
#沿梯度方向上升
theta[0] += step_size*gradient_0
theta[1] += step_size*gradient_1
#计算似然性
for i in range(0,40):
h_theta = sigmoid(x1[i]*theta[0]+x2[i]*theta[1])#h_theta(xi)
if y[i] != 1 and y[i] != 0:
print('data error of y',(i+1),'it should be 1 or 0')
return
if y[i] ==1 :
loss *= h_theta
if y[i] ==0 :
loss *= (1-h_theta)
iter_count += 1
print('iter_count',iter_count)
print('theta:',theta)
print('loss',loss)
return theta
print('x1:',x1)
print('x2:',x2)
print('y:',y)
#进行训练
final_theta = gradAdcent(x1=x1,x2=x2,y=y)
print('final_theta:',final_theta)
#进行预测
#生成10个预测结果应为1的测试数据,再生成10个预测结果应为0的测试数据.
test_y1_x1 = np.random.normal(y1_x1_mu,y1_x1_sigma,10)
test_y1_x2 = np.random.normal(y1_x2_mu,y1_x2_sigma,10)
test_y0_x1 = np.random.normal(y0_x1_mu,y0_x1_sigma,10)
test_y0_x2 = np.random.normal(y0_x2_mu,y0_x2_sigma,10)
test_x1 = list(test_y1_x1)
test_x1.extend(test_y0_x1)
test_x2 = list(test_y1_x2)
test_x2.extend(test_y0_x2)
right_count = 0
#前十项为预测结果为1的x1,x2,后十项为预测结果为0的x1,x2
#logistic预测值大于0.5预测为1,小于0.5预测为0
for i in range (0,10):
h_theta = sigmoid(test_x1[i]*final_theta[0]+test_x2[i]*final_theta[1])
if h_theta >= 0.5:
right_count += 1
for i in range (0,10):
h_theta = sigmoid(test_x1[i]*final_theta[0]+test_x2[i]*final_theta[1])
if h_theta <= 0.5:
right_count += 1
print('right_count:',right_count)
print('accurate rate:',(right_count/20))
print('end')
运行结果如下
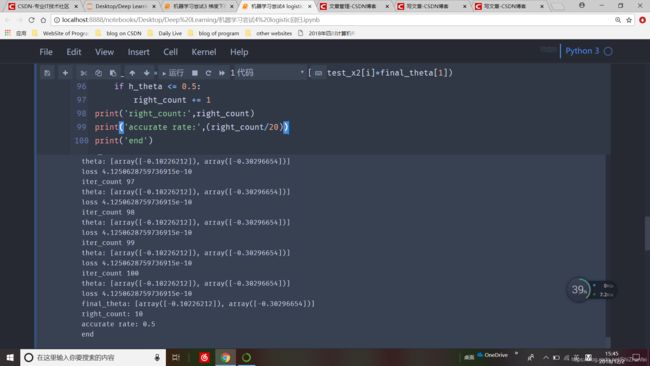
所选参数大致能得到预测准确率稳定在50%左右的训练模型。本文重点在于logistic回归数理过程的梳理和算法实现原理,等知识水平提高,经验丰富后,应该能得到更好的模型。
2018/12/2