Flink高可用集群搭建
部署flink的准备工作
- flink版本的选择需要考虑hadoop的版本,本集群hadoop的版本为2.7.4,flink的版本为flink-1.7.2-bin-hadoop27-scala_2.11.tgz
- flink高可用集群需要依赖zookeeper
开始安装
1. 编辑flink的配置文件 flink-conf.yaml
# 这里选择配置主节点
jobmanager.rpc.address: node1
# The RPC port where the JobManager is reachable.
jobmanager.rpc.port: 6123
# The heap size for the JobManager JVM
# jobmanager内存大小
jobmanager.heap.size: 8192m
# The heap size for the TaskManager JVM
# taskmanager内存大小
taskmanager.heap.size: 8192m
# The number of task slots that each TaskManager offers. Each slot runs one parallel pipeline.
# taskmanager虚拟核数 这里但虚拟机为6 vcores
taskmanager.numberOfTaskSlots: 6
# The parallelism used for programs that did not specify and other parallelism.
# 集群总核数 五节点
parallelism.default: 30
# The default file system scheme and authority.
#
# By default file paths without scheme are interpreted relative to the local
# root file system 'file:///'. Use this to override the default and interpret
# relative paths relative to a different file system,
# for example 'hdfs://mynamenode:12345'
#
# fs.default-scheme
#==============================================================================
# High Availability
#==============================================================================
# The high-availability mode. Possible options are 'NONE' or 'zookeeper'.
# 高可用方式 zoookeeper
high-availability: zookeeper
# The path where metadata for master recovery is persisted. While ZooKeeper stores
# the small ground truth for checkpoint and leader election, this location stores
# the larger objects, like persisted dataflow graphs.
#
# Must be a durable file system that is accessible from all nodes
# (like HDFS, S3, Ceph, nfs, ...)
# 高可用集群数据存储文件夹
high-availability.storageDir: hdfs://leo/flink/ha/
# yarn 应用最大尝试次数
yarn.application-attempts: 10
# The list of ZooKeeper quorum peers that coordinate the high-availability
# setup. This must be a list of the form:
# "host1:clientPort,host2:clientPort,..." (default clientPort: 2181)
# 高可用集群的zookeeper地址
high-availability.zookeeper.quorum: node3:2181,node4:2181,node5:2181
# flink zookeeper 根目录
high-availability.zookeeper.path.root: /flink
# ACL options are based on https://zookeeper.apache.org/doc/r3.1.2/zookeeperProgrammers.html#sc_BuiltinACLSchemes
# It can be either "creator" (ZOO_CREATE_ALL_ACL) or "open" (ZOO_OPEN_ACL_UNSAFE)
# The default value is "open" and it can be changed to "creator" if ZK security is enabled
#
# high-availability.zookeeper.client.acl: open
#==============================================================================
# Fault tolerance and checkpointing
#==============================================================================
# The backend that will be used to store operator state checkpoints if
# checkpointing is enabled.
#
# Supported backends are 'jobmanager', 'filesystem', 'rocksdb', or the
# .
#
state.backend: filesystem
# Directory for checkpoints filesystem, when using any of the default bundled
# state backends.
# checkpoints hdfs路径
state.checkpoints.dir: hdfs://leo/flink-checkpoints
# Default target directory for savepoints, optional.
#
state.savepoints.dir: hdfs://leo/flink-checkpoints
# Flag to enable/disable incremental checkpoints for backends that
# support incremental checkpoints (like the RocksDB state backend).
#
# state.backend.incremental: false
#==============================================================================
# Web Frontend
#==============================================================================
# The address under which the web-based runtime monitor listens.
#
#web.address: 0.0.0.0
# The port under which the web-based runtime monitor listens.
# A value of -1 deactivates the web server.
# web ui端口
rest.port: 8081
# Flag to specify whether job submission is enabled from the web-based
# runtime monitor. Uncomment to disable.
web.submit.enable: true
#==============================================================================
# Advanced
#==============================================================================
# Override the directories for temporary files. If not specified, the
# system-specific Java temporary directory (java.io.tmpdir property) is taken.
#
# For framework setups on Yarn or Mesos, Flink will automatically pick up the
# containers' temp directories without any need for configuration.
#
# Add a delimited list for multiple directories, using the system directory
# delimiter (colon ':' on unix) or a comma, e.g.:
# /data1/tmp:/data2/tmp:/data3/tmp
#
# Note: Each directory entry is read from and written to by a different I/O
# thread. You can include the same directory multiple times in order to create
# multiple I/O threads against that directory. This is for example relevant for
# high-throughput RAIDs.
#
# io.tmp.dirs: /tmp
# Specify whether TaskManager's managed memory should be allocated when starting
# up (true) or when memory is requested.
#
# We recommend to set this value to 'true' only in setups for pure batch
# processing (DataSet API). Streaming setups currently do not use the TaskManager's
# managed memory: The 'rocksdb' state backend uses RocksDB's own memory management,
# while the 'memory' and 'filesystem' backends explicitly keep data as objects
# to save on serialization cost.
#
# taskmanager.memory.preallocate: false
# The classloading resolve order. Possible values are 'child-first' (Flink's default)
# and 'parent-first' (Java's default).
#
# Child first classloading allows users to use different dependency/library
# versions in their application than those in the classpath. Switching back
# to 'parent-first' may help with debugging dependency issues.
#
# classloader.resolve-order: child-first
# The amount of memory going to the network stack. These numbers usually need
# no tuning. Adjusting them may be necessary in case of an "Insufficient number
# of network buffers" error. The default min is 64MB, teh default max is 1GB.
#
# taskmanager.network.memory.fraction: 0.1
# taskmanager.network.memory.min: 64mb
# taskmanager.network.memory.max: 1gb
#==============================================================================
# Flink Cluster Security Configuration
#==============================================================================
# Kerberos authentication for various components - Hadoop, ZooKeeper, and connectors -
# may be enabled in four steps:
# 1. configure the local krb5.conf file
# 2. provide Kerberos credentials (either a keytab or a ticket cache w/ kinit)
# 3. make the credentials available to various JAAS login contexts
# 4. configure the connector to use JAAS/SASL
# The below configure how Kerberos credentials are provided. A keytab will be used instead of
# a ticket cache if the keytab path and principal are set.
# security.kerberos.login.use-ticket-cache: true
# security.kerberos.login.keytab: /path/to/kerberos/keytab
# security.kerberos.login.principal: flink-user
# The configuration below defines which JAAS login contexts
# security.kerberos.login.contexts: Client,KafkaClient
#==============================================================================
# ZK Security Configuration
#==============================================================================
# Below configurations are applicable if ZK ensemble is configured for security
# Override below configuration to provide custom ZK service name if configured
# zookeeper.sasl.service-name: zookeeper
# The configuration below must match one of the values set in "security.kerberos.login.contexts"
# zookeeper.sasl.login-context-name: Client
#==============================================================================
# HistoryServer
#==============================================================================
# The HistoryServer is started and stopped via bin/historyserver.sh (start|stop)
# Directory to upload completed jobs to. Add this directory to the list of
# monitored directories of the HistoryServer as well (see below).
#jobmanager.archive.fs.dir: hdfs:///completed-jobs/
# The address under which the web-based HistoryServer listens.
#historyserver.web.address: 0.0.0.0
# The port under which the web-based HistoryServer listens.
historyserver.web.port: 8082
# Comma separated list of directories to monitor for completed jobs.
#historyserver.archive.fs.dir: hdfs:///completed-jobs/
# Interval in milliseconds for refreshing the monitored directories.
#historyserver.archive.fs.refresh-interval: 10000
2. 编辑 bin/yarn-session.sh
export HADOOP_USER_NAME=hadoop
JVM_ARGS="$JVM_ARGS -Xmx512m"
备注:为了防止发生权限错误
3. 编辑masters文件
node1:8081
node2:8082
4. 编辑slaves文件
node1
node2
node3
node4
node5
5. 编辑zoo.cfg文件,末位追加如下内容
# ZooKeeper quorum peers
#server.1=localhost:2888:3888
# server.2=host:peer-port:leader-port
server.1=node3:2888:3888
server.2=node4:2888:3888
server.3=node5:2888:3888
6. flink日志配置
Flink默认包含两种配置方式:log4j以及logback
不配置的情况下运行flink集群或者运行flink job会提示建议移除其中一种。
直接移除或者重命名都可行。
例如:mv logback.xml logback.xml_bak
7. 快速开始
- Standalone模式
cd /home/hadoop/flink-1.7.2/
[hadoop@node1 flink-1.7.2]$ cd /home/hadoop/flink-1.7.2/
[hadoop@node1 flink-1.7.2]$ ./bin/start-cluster.sh
Starting HA cluster with 2 masters.
Starting standalonesession daemon on host node1.
Starting standalonesession daemon on host node2.
Starting taskexecutor daemon on host node1.
Starting taskexecutor daemon on host node2.
Starting taskexecutor daemon on host node3.
Starting taskexecutor daemon on host node4.
Starting taskexecutor daemon on host node5.
浏览器中访问node1:8081
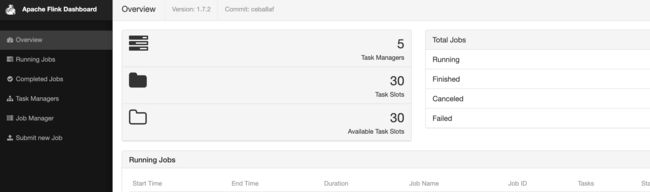
[hadoop@node1 flink-1.7.2]$ ./bin/stop-cluster.sh
Stopping taskexecutor daemon (pid: 12133) on host node1.
Stopping taskexecutor daemon (pid: 8607) on host node2.
Stopping taskexecutor daemon (pid: 31771) on host node3.
Stopping taskexecutor daemon (pid: 32408) on host node4.
Stopping taskexecutor daemon (pid: 18846) on host node5.
Stopping standalonesession daemon (pid: 11640) on host node1.
Stopping standalonesession daemon (pid: 8140) on host node2.
- Flink On Yarn模式
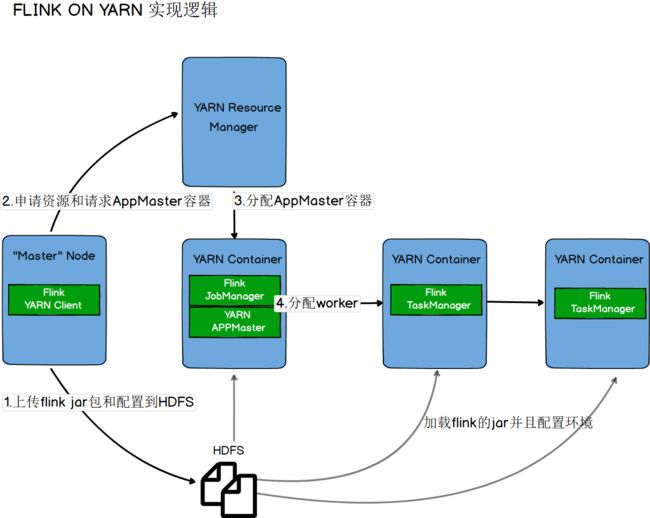
[1] 第一种方式:yarn-session.sh(开辟资源)+flink run(提交任务)
启动一个一直运行的flink集群
# 下面的命令会申请5个taskmanager,每个2G内存和2个solt,超过集群总资源将会启动失败。
./bin/yarn-session.sh -n 5 -tm 2048 -s 2 --nm leo-flink -d
-n ,–container 分配多少个yarn容器(=taskmanager的数量)
-D 动态属性
-d, --detached 独立运行
-jm,–jobManagerMemory JobManager的内存 [in MB]
-nm,–name 在YARN上为一个自定义的应用设置一个名字
-q,–query 显示yarn中可用的资源 (内存, cpu核数)
-qu,–queue 指定YARN队列.
-s,–slots 每个TaskManager使用的slots(vcore)数量
-tm,–taskManagerMemory 每个TaskManager的内存 [in MB]
-z,–zookeeperNamespace 针对HA模式在zookeeper上创建NameSpace
请注意:
请注意:client必须要设置YARN_CONF_DIR或者HADOOP_CONF_DIR环境变量,通过这个环境变量来读取YARN和HDFS的配置信息,否则启动会失败。 经实验发现,其实如果配置的有HADOOP_HOME环境变量的话也是可以的(只是会出现警告)。HADOOP_HOME ,YARN_CONF_DIR,HADOOP_CONF_DIR 只要配置的有任何一个即可。
运行结果如图:

浏览器中访问 http://node4:45559
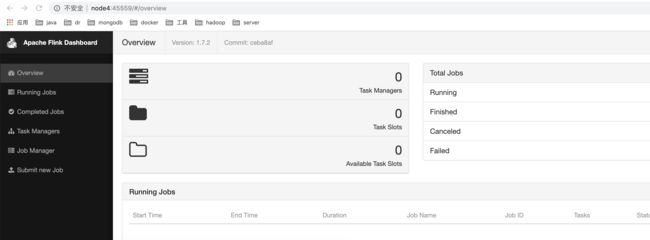
yarn web-ui中

部署长期运行的flink on yarn实例后,在flink web上看到的TaskManager以及Slots都为0。只有在提交任务的时候,才会依据分配资源给对应的任务执行。
提交Job到长期运行的flink on yarn实例上:
./bin/flink run ./examples/batch/WordCount.jar -input hdfs://leo/test/test.txt -output hdfs://leo/flink-word-count
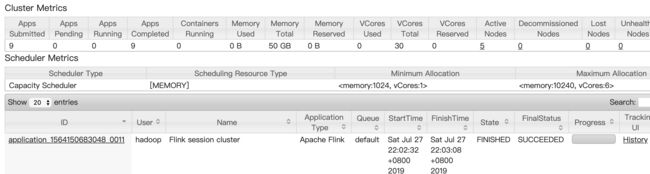
通过web ui可以看到已经运行完成的任务:
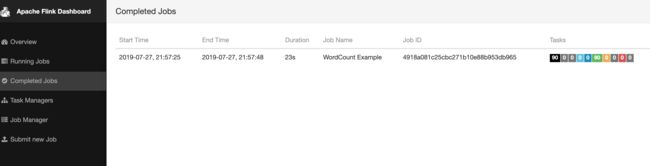
[2] 第二种方式:flink run -m yarn-cluster(开辟资源+提交任务)
./bin/flink run -m yarn-cluster -yn 2 -yjm 1024 -ytm 1024 ./examples/batch/WordCount.jar -input hdfs://leo/test/test.txt -output hdfs://leo/test/flink-word-count2.txt
yarn web ui上查看刚刚提交的任务已经执行成功
文末小节
hadoop、hbase、hive、spark、kafaka、flink的开发环境集群搭建已经成功完成。里面或许有不足之处,或有理解不到位的地方,欢迎指正。以下系列将由基础到进阶,记录这些组件的实际使用。