Hadoop学习笔记_4:运行模式之伪分布式模式
-
伪分布式模式
Hadoop can also be run on a single-node in a pseudo-distributed mode where each Hadoop daemon runs in a separate Java process.
Hadoop也可以以伪分布式模式在单节点上运行,其中每个Hadoop守护程序都在单独的Java进程中运行。
-
启动HDFS并运行MapReduce程序
-
配置集群
-
配置
etc/hadoop/hadoop-env.sh,修改JAVA_HOME路径为环境变量。[root@localhost hadoop]# vim hadoop-env.sh # The only required environment variable is JAVA_HOME. All others are # optional. When running a distributed configuration it is best to # set JAVA_HOME in this file, so that it is correctly defined on # remote nodes. # 唯一需要的环境变量是JAVA_HOME。 所有其他均为可选。 运行分布式配置时,最好在此文件中设置JAVA_HOME,以便在远程节点上正确定义它。 # The java implementation to use. export JAVA_HOME=/opt/module/jdk1.8.0_144 -
配置
etc/hadoop/core-site.xml,指定nameNode地址及临时文件目录。[root@localhost hadoop]# vim core-site.xml <configuration> <!-- 指定 HDFS 中 NameNode 的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://192.168.116.100:9000</value> </property> <!-- 指定 Hadoop 运行时产生文件的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/module/hadoop-2.7.2/data/tmp</value> </property> </configuration>这里hdfs中由于没有配置hosts文件的映射,使用了IP地址的方式配置。
-
配置
etc/hadoop/hdfs-site.xml,配置副本数量,默认为3【这里的副本是本地设置,其他节点自动备份】。[root@localhost hadoop]# vim hdfs-site.xml <configuration> <!-- 指定 HDFS 副本的数量 --> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration>
-
-
启动集群
-
格式化 NameNode(第一次启动时需要格式化)
[root@localhost hadoop-2.7.2]# bin/hdfs namenode -format -
启动 NameNode 、DataNode
[root@localhost hadoop-2.7.2]# sbin/hadoop-daemon.sh start namenode starting namenode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-root-namenode-localhost.localdomain.out [root@localhost hadoop-2.7.2]# sbin/hadoop-daemon.sh start datanode starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-root-datanode-localhost.localdomain.out -
-
查看集群
-
查看是否启动成功(
jps是JDK中的命令,配置完成环境变量后即可使用)[root@localhost hadoop-2.7.2]# jps 1362 DataNode 1461 Jps 1308 NameNode -
通过web端查看
HDFS文件系统,这里是在win宿主机下浏览器进行的访问,由于没有配置hosts相关映射,通过IP直接进行访问。http://192.168.116.100:50070/dfshealth.html#tab-overview
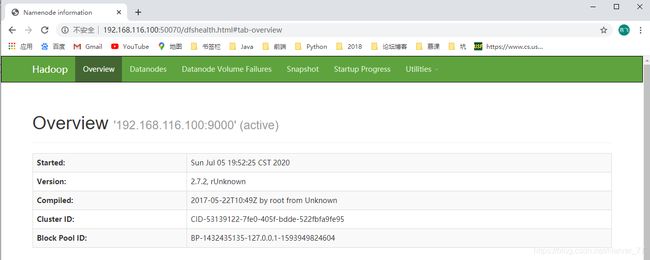
-
查看产生的Log日志
[root@localhost logs]# ll 总用量 72 -rw-r--r-- 1 root root 25277 7月 5 20:10 hadoop-root-datanode-localhost.localdomain.log -rw-r--r-- 1 root root 714 7月 5 19:52 hadoop-root-datanode-localhost.localdomain.out -rw-r--r-- 1 root root 30915 7月 5 20:10 hadoop-root-namenode-localhost.localdomain.log -rw-r--r-- 1 root root 5002 7月 5 20:00 hadoop-root-namenode-localhost.localdomain.out -rw-r--r-- 1 root root 0 7月 5 19:52 SecurityAuth-root.audit [root@localhost logs]# cat hadoop-root-datanode-localhost.localdomain.log -
格式化NameNode请注意:
-
进入指定好的 Hadoop 运行时产生文件的存储目录:
-
/name,nameNode
[root@localhost hadoop-2.7.2]# cd data/tmp/dfs/name/current/ [root@localhost current]# ll 总用量 1040 -rw-r--r-- 1 root root 1048576 7月 5 20:10 edits_inprogress_0000000000000000001 -rw-r--r-- 1 root root 350 7月 5 19:50 fsimage_0000000000000000000 -rw-r--r-- 1 root root 62 7月 5 19:50 fsimage_0000000000000000000.md5 -rw-r--r-- 1 root root 2 7月 5 19:52 seen_txid -rw-r--r-- 1 root root 201 7月 5 19:50 VERSION [root@localhost current]# cat VERSION #Sun Jul 05 19:50:24 CST 2020 namespaceID=253643691 clusterID=CID-53139122-7fe0-405f-bdde-522fbfa9fe95 cTime=0 storageType=NAME_NODE blockpoolID=BP-1432435135-127.0.0.1-1593949824604 layoutVersion=-63/data,dataNode
[root@localhost hadoop-2.7.2]# cd data/tmp/dfs/data/current/ [root@localhost current]# ll 总用量 4 drwx------ 4 root root 54 7月 5 19:52 BP-1432435135-127.0.0.1-1593949824604 -rw-r--r-- 1 root root 229 7月 5 19:52 VERSION [root@localhost current]# cat VERSION #Sun Jul 05 19:52:36 CST 2020 storageID=DS-9a858421-29ac-4778-b625-6881374acfd6 clusterID=CID-53139122-7fe0-405f-bdde-522fbfa9fe95 cTime=0 datanodeUuid=acc2d611-bd06-4a73-94e8-9672fed10714 storageType=DATA_NODE layoutVersion=-56可以发现:nameNode和dataNode中的clusterID一致,在HDFS中需要保持一致才能进行通信。随意格式化nameNode,会导致nameNode的clusterID发生变化,无法与dataNode一致,造成无法通信及数据获取。因此,在格式nameNode时,需要删除data数据及log日志数据,然后进行
namenode -format操作。 -
-
-
操作集群
-
在
HDFS文件系统中创建一个输入文件夹(input)[root@localhost hadoop-2.7.2]# bin/hdfs dfs -mkdir -p /user/bcxtm/input -
将测试文件上传至文件系统中:
-put[root@localhost hadoop-2.7.2]# bin/hdfs dfs -put wcinput/wc.input /user/bcxtm/input/
-
运行
MapReduce程序,再次实现wordcount案例[root@localhost hadoop-2.7.2]# bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/bcxtm/input/ /user/bcxtm/output
-
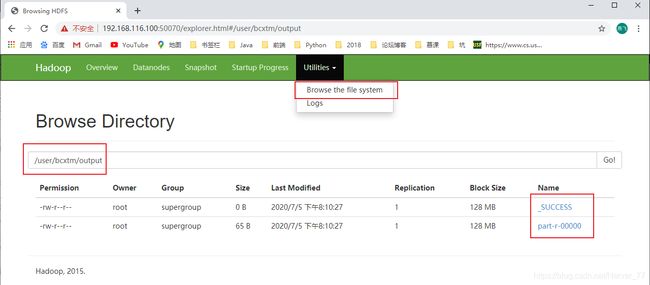
将测试输出文件下载到本地:
-get[root@localhost hadoop-2.7.2]# hdfs dfs -get /user/bcxtm/output/part-r-00000 /wcoutput/ get: `/wcoutput/': No such file or directory [root@localhost hadoop-2.7.2]# mkdir wcoutput [root@localhost hadoop-2.7.2]# hdfs dfs -get /user/bcxtm/output/part-r-00000 ./wcoutput/ # 查看下载到本地的测试输出文件 [root@localhost hadoop-2.7.2]# cat wcoutput/part-r-00000 Alibaba 1 Baidu 1 Bcxtm 3 ByteDance 1 lisi 1 wangwu 2 zhangsan 1
-
-
-
启动YARN并运行MapReduce程序
-
配置集群
-
配置
etc/hadoop/yarn-env.sh,修改JAVA_HOME路径为环境变量。[root@localhost hadoop]# vim yarn-env.sh [root@localhost hadoop]# cat yarn-env.sh # some Java parameters # export JAVA_HOME=/home/y/libexec/jdk1.6.0/ if [ "$JAVA_HOME" != "" ]; then #echo "run java in $JAVA_HOME" JAVA_HOME=/opt/module/jdk1.8.0_144 -
配置
etc/hadoop/yarn-site.xml,nodeManager和resourceManager。这里ResourceManager地址仍是使用IP地址进行配置。[root@localhost hadoop]# vim yarn-site.xml [root@localhost hadoop]# cat yarn-site.xml <configuration> <!-- Site specific YARN configuration properties --> <!-- Reducer 获取数据的方式 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定 YARN 的 ResourceManager 的地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>192.168.116.100</value> </property> </configuration> -
配置
etc/hadoop/mapred-env.sh,修改JAVA_HOME路径为环境变量。[root@localhost hadoop]# vim mapred-env.sh [root@localhost hadoop]# cat mapred-env.sh # export JAVA_HOME=/home/y/libexec/jdk1.6.0/ export JAVA_HOME=/opt/module/jdk1.8.0_144 export HADOOP_JOB_HISTORYSERVER_HEAPSIZE=1000 export HADOOP_MAPRED_ROOT_LOGGER=INFO,RFA -
配置
etc/hadoop/mapred-site.xml,重命名模板配置相应文件。[root@localhost hadoop]# ll ## ... -rw-r--r-- 1 root root 758 5月 22 2017 mapred-site.xml.template [root@localhost hadoop]# mv mapred-site.xml.template mapred-site.xml [root@localhost hadoop]# ll ## ... -rw-r--r-- 1 root root 758 5月 22 2017 mapred-site.xml [root@localhost hadoop]# vim mapred-site.xml [root@localhost hadoop]# cat mapred-site.xml <configuration> <!-- 指定 MR 运行在 YARN 上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
-
-
启动集群
-
启动前必须保证NameNode及DataNode已启动
[root@localhost hadoop]# jps 1936 Jps 1362 DataNode 1308 NameNode -
启动
ResourceManager及NodeManager[root@localhost hadoop-2.7.2]# sbin/yarn-daemon.sh start resourcemanager starting resourcemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-root-resourcemanager-localhost.localdomain.out [root@localhost hadoop-2.7.2]# sbin/yarn-daemon.sh start nodemanager starting nodemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-root-nodemanager-localhost.localdomain.out [root@localhost hadoop-2.7.2]# jps 2081 Jps 1362 DataNode 1308 NameNode 1964 ResourceManager 2014 NodeManager
-
-
集群操作
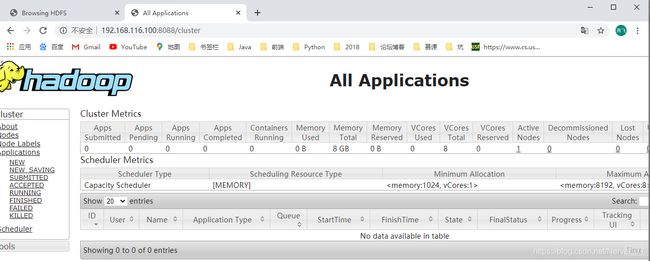
- 通过
web查看:http://192.168.116.100:8088/cluster
- 通过
-
配置历史服务器
- 配置
mapred-site.xml,增加历史服务器地址及web端地址

[root@localhost hadoop]# vim mapred-site.xml [root@localhost hadoop]# cat mapred-site.xml <configuration> <!-- 指定 MR 运行在 YARN 上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!-- 历史服务器端地址 --> <property> <name>mapreduce.jobhistory.address</name> <value>192.168.116.100:10020</value> </property> <!-- 历史服务器 web 端地址 --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>192.168.116.100:19888</value> </property> </configuration>-
启动历史服务器
[root@localhost hadoop-2.7.2]# sbin/mr-jobhistory-daemon.sh start historyserver starting historyserver, logging to /opt/module/hadoop-2.7.2/logs/mapred-root-historyserver-localhost.localdomain.out [root@localhost hadoop-2.7.2]# jps 1362 DataNode 2474 JobHistoryServer 2507 Jps 1308 NameNode 1964 ResourceManager 2014 NodeManager -
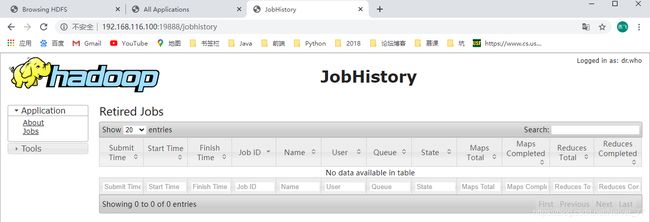
通过
web查看:http://192.168.116.100:19888/jobhistory
- 配置
-
配置日志聚集(应用运行完成以后,将程序运行日志信息上传到 HDFS 系统上)
注意:开启日志聚集功能 , 需要重新启动 NodeManager 、 ResourceManager 和
HistoryServer-
配置
yarn-site.xml,设置日志聚集功能及过期时间(秒)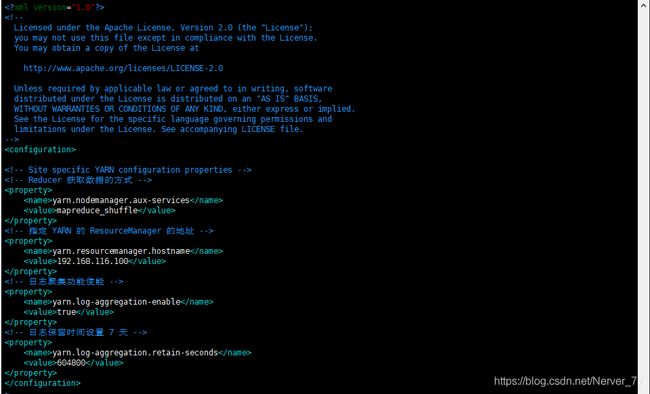
[root@localhost hadoop]# vim yarn-site.xml [root@localhost hadoop]# cat yarn-site.xml <configuration> <!-- Site specific YARN configuration properties --> <!-- Reducer 获取数据的方式 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定 YARN 的 ResourceManager 的地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>192.168.116.100</value> </property> <!-- 日志聚集功能使能 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 日志保留时间设置 7 天 --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property> </configuration> -
关闭NodeManager 、 ResourceManager 和 HistoryServer
[root@localhost hadoop-2.7.2]# sbin/yarn-daemon.sh stop nodemanager stopping nodemanager [root@localhost hadoop-2.7.2]# sbin/yarn-daemon.sh stop resourcemanager stopping resourcemanager [root@localhost hadoop-2.7.2]# sbin/mr-jobhistory-daemon.sh stop historyserver stopping historyserver [root@localhost hadoop-2.7.2]# jps 1362 DataNode 2664 Jps 1308 NameNode -
启动NodeManager 、 ResourceManager 和 HistoryServer
[root@localhost hadoop-2.7.2]# sbin/yarn-daemon.sh start nodemanager starting nodemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-root-nodemanager-localhost.localdomain.out [root@localhost hadoop-2.7.2]# sbin/yarn-daemon.sh start resourcemanager starting resourcemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-root-resourcemanager-localhost.localdomain.out [root@localhost hadoop-2.7.2]# sbin/mr-jobhistory-daemon.sh start historyserver starting historyserver, logging to /opt/module/hadoop-2.7.2/logs/mapred-root-historyserver-localhost.localdomain.out [root@localhost hadoop-2.7.2]# jps 1362 DataNode 2819 ResourceManager 2965 JobHistoryServer 2998 Jps 2697 NodeManager 1308 NameNode
-
-
删除
HDFS文件系统中的output文件,方便后续重新执行MapReduce程序[root@localhost hadoop-2.7.2]# hdfs dfs -rm -r /user/bcxtm/output 20/07/05 21:48:10 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 0 minutes, Emptier interval = 0 minutes. Deleted /user/bcxtm/output -
重新执行MapReduce程序
[root@localhost hadoop-2.7.2]# hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/bcxtm/input /user/bcxtm/output 20/07/05 22:09:30 INFO client.RMProxy: Connecting to ResourceManager at /192.168.116.100:8032 20/07/05 22:09:36 INFO input.FileInputFormat: Total input paths to process : 1 20/07/05 22:09:36 INFO mapreduce.JobSubmitter: number of splits:1 20/07/05 22:09:36 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1593957936940_0001 20/07/05 22:10:12 INFO impl.YarnClientImpl: Submitted application application_1593957936940_0001 20/07/05 22:10:37 INFO mapreduce.Job: The url to track the job: http://192.168.116.100:8088/proxy/application_1593957936940_0001/ 20/07/05 22:10:37 INFO mapreduce.Job: Running job: job_1593957936940_0001 20/07/05 22:10:43 INFO mapreduce.Job: Job job_1593957936940_0001 running in uber mode : false 20/07/05 22:10:43 INFO mapreduce.Job: map 0% reduce 0% 20/07/05 22:10:53 INFO mapreduce.Job: map 100% reduce 0% 20/07/05 22:11:21 INFO mapreduce.Job: map 100% reduce 100% 20/07/05 22:11:31 INFO mapreduce.Job: Job job_1593957936940_0001 completed successfully 20/07/05 22:11:31 INFO mapreduce.Job: Counters: 49可以看到,通过YRAN进行MapReduce的程序执行,会创建一个job后进行先Map再Reduce的一个运行流程。最后通过web页面可以看到这个任务的执行情况及历史信息等。

-
查看历史服务器信息

-
查看日志聚集信息
-
-