Spark-Core(三) - Stage剖析&&Spark on yarn的两种模式
一、Spark-Core(二)回顾
二、Stage剖析
- 2.1、遇到action产生job
- 2.2、job产生stage
- 2.3、rdd中的cache
- 2.4、Spark-shell中测试rdd缓存 && StorageLevel
- 2.5、Spark-Core中的框架选择(MEMORY_ONLY)
- 2.6、recomputing重算概念
- 2.7、Spark中的宽窄依赖
三、回顾Hadoop中的Yarn
- 3.1、 Spark on yarn的描述
- 3.2、 Spark on yarn的使用
- 3.3、 Spark-shell上测试client
- 3.4、 spark on yarn上测试cluster模式 && 报错信息排查
一、Spark-Core(二)回顾
- Spark的运行架构,各种关键术语的解释:Driver、Cluster Manager、Executor
RDD中有很多方法,a list of partitions,有一个函数:a function for computing each split,有一系列的依赖: a list of dependencies on other RDD;
| 五大特性 | 对应的在源码中的方法 | 运行在driver端还是executor端 | Input | Output |
|---|---|---|---|---|
| A list of partitions | getPartitions | ? | Partition | |
| A function for compting each split | compute | ? | Iterable可迭代的 | |
| A list of dependencies on other RDD | getDependencies | ? | Dependency |
可选的操作:a Partitioner for key-value RDDs、A list of preferred locations to compute each split
二、Stage剖析:
2.1、遇到action产生job
1、每遇到一个action就会触发一个job,每一个job又会被拆分成更小的task
在Spark-shell中执行如下:
scala> sc.parallelize(List(1,2,3,4,4,4,55,55,2,1)).map((_,1)).reduceByKey(_+_).collect
res1: Array[(Int, Int)] = Array((4,3), (2,2), (55,2), (1,2), (3,1))
scala> sc.parallelize(List(1,2,3,4,4,4,55,55,2,1)).map((_,1)).collect
res2: Array[(Int, Int)] = Array((1,1), (2,1), (3,1), (4,1), (4,1), (4,1), (55,1), (55,1), (2,1), (1,1))
- WebUI界面的结果:
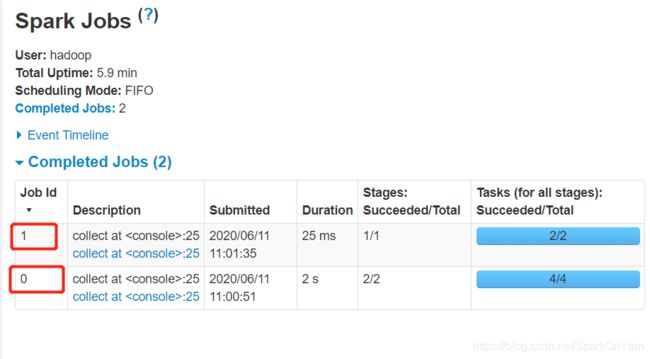
Job的定义:
1、 一种由多个task组成的并行计算,job由Spark中相应算子进行触发(例如save、collect);你会在driver’s log中看到这个术语: - A parallel computation consisting of multiple tasks that gets spawned in response to a Spark action (e.g. save, collect); you’ll see this term used in the driver’s logs
- 每遇到一个action算子如collect就会变成一个job
- 如上图所示:我们两个计算中使用了两个collect算子,所以生成了两个job
- Job id的初始值是0,为什么接下来是1,然后是2;因为每遇到一个action后job id的值都会依次递增1;
2.2、Job如何产生Stage
1、每一个job都会被拆分成更小的task ==>称为Stages;如果Stage之间有依赖,必须前一个Stage执行完后才执行后一个Stage;
- Each job get divided into smaller sets of tasks called stages that depend on each other(similar to the map and reduce stages in MapReduce)
1、下图中的DAG图就是这句语句中出现的:
sc.parallelize(List(1,1,2,2,3,3,3,3,4,4,4,5)).map((,1)).reduceByKey(+_).collect
res2: Array[(Int, Int)] = Array((4,3), (2,2), (1,2), (3,4), (5,1))
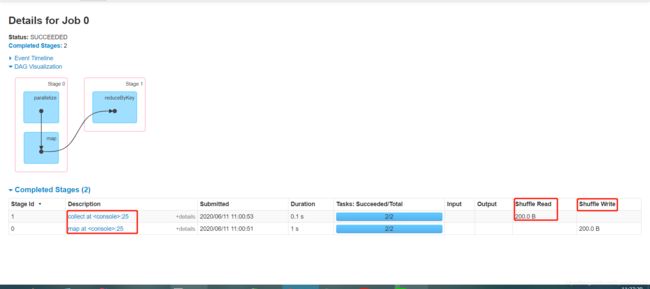
2、reduceByKey算子会产生shuffle,一遇到shuffle就会产生Stage;stage2需要等stage1执行完才执行
3、如上语句中分别是如下的3个算子:parallelize、map、reduceByKey;reduceByKey算子会产生shuffle,shuffle会产生stage。举例:原来是一个stage,当我们遇到shuffle后,就会被切一刀,变成2个stage。
遇到collect触发成为1个job,然后job中有带shuffle的reduceByKey又被拆分为2个stages;如下图中的collect at和map at都是以stage中的最后一个算子进行命名的。
2.3、Rdd中的Cache
Rdd中的缓存主要是用于提升速度使用,扩充:JVM:java memory model,计算是通过cpu来处理的,数据是存在内存中的,现在很多地方都很耗费cpu;
Spark中最重要的一个功能是持久化数据到内存中,内存存储在executor中
1、Spark非常重要的一个功能是将rdd持久化在内存中。当对rdd执行持久化操作的时候,每个节点都会将自己操作的RDD的partition持久化到内存中;这样的话,针对于一个rdd反复操作的场景,就只要对rdd进行一次计算即可,后面再使用该rdd不需要反复计算了。
2、 要持久化RDD,只要调用其cache()或者persist()方法即可。在该rdd第一次被计算出来的时候,就会直接缓存在每个节点中。而且持久化机制是容错的,如果持久化的rdd中的任何partition丢失了,那么spark还会通过其源rdd,使用transformation操作重新计算该partition。
3、 cache和persist的区别在于,cache调用的就是persist,而persist调用的是persist(memory_only);如果需要在内存中清除缓存,采用unpersist方法。
2.4、Spark-shell中测试rdd缓存 && StorageLevel
1、读取文件:
scala> val lines = sc.textFile("file:///home/hadoop/data/ruozeinput.txt")
lines: org.apache.spark.rdd.RDD[String] = file:///home/hadoop/data/ruozeinput.txt MapPartitionsRDD[1] at textFile at <console>:24
2、把这个文件cache住:
scala> lines.cache
res0: lines.type = file:///home/hadoop/data/ruozeinput.txt MapPartitionsRDD[1] at textFile at <console>:24
3、使用collect进行触发:
scala> lines.collect
res1: Array[String] = Array(hello hello hello, world world, john)
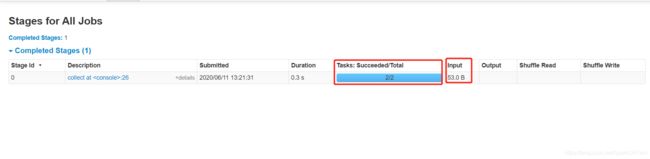
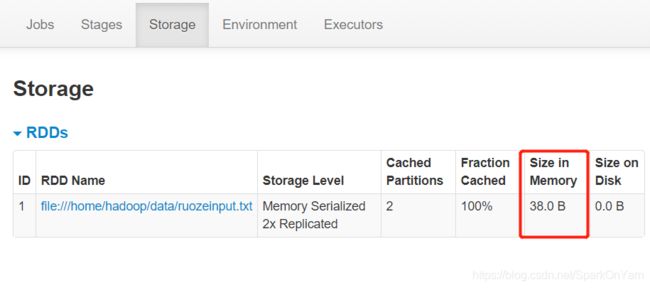
1、使用cache的时候不触发job,cache操作做是lazy的,它遇到collect算子后才会触发;在storage页面中查看到的是缓存信息,有2个分区被100% cache住了;

2、在Stage页面中查看到输入文件大小是53B,而在内存中该文件大小是240B,反而变大了
可以联想到Spark-Core2中的LogAPP解析需求:
一个作业中多个需求,有些部分可以抽取出来,把它cache住,避免反复调用;
cache和persist的方法的区别:
1、cache调用的是persist方法
2、persist调用的是persist中的一个只读内存方法
SparkCore默认使用的就是memory_only方法:
两个方法在源码中的区别:
* Persist this RDD with the default storage level (`MEMORY_ONLY`).
def persist(): this.type = persist(StorageLevel.MEMORY_ONLY)
* Persist this RDD with the default storage level (`MEMORY_ONLY`).
def cache(): this.type = persist()
//鼠标ctrl+左键,点进StorageLevel中去:
object StorageLevel {
val NONE = new StorageLevel(false, false, false, false)
val DISK_ONLY = new StorageLevel(true, false, false, false)
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
val OFF_HEAP = new StorageLevel(true, true, true, false, 1)
private var _useDisk: Boolean, 磁盘
private var _useMemory: Boolean, 内存
private var _useOffHeap: Boolean, 堆外内存
private var _deserialized: Boolean, 反序列化
private var _replication: Int = 1) 副本数
清除缓存:
- scala> lines.unpersist()
res2: lines.type = file:///home/hadoop/data/ruozeinput.txt MapPartitionsRDD[1] at textFile at :24
执行cache的时候是一个lazy操作的,清除缓存的时候却是eager的;
Spark-shell中测试StorageLevel
scala> import org.apache.spark.storage.StorageLevel
import org.apache.spark.storage.StorageLevel
scala> lines.persist(StorageLevel.MEMORY_AND_DISK_SER_2)
res3: lines.type = file:///home/hadoop/data/ruozeinput.txt MapPartitionsRDD[1] at textFile at <console>:24
scala> lines.count
20/06/11 13:51:12 WARN RandomBlockReplicationPolicy: Expecting 1 replicas with only 0 peer/s.
20/06/11 13:51:12 WARN RandomBlockReplicationPolicy: Expecting 1 replicas with only 0 peer/s.
20/06/11 13:51:12 WARN BlockManager: Block rdd_1_0 replicated to only 0 peer(s) instead of 1 peers
20/06/11 13:51:12 WARN BlockManager: Block rdd_1_1 replicated to only 0 peer(s) instead of 1 peers
res4: Long = 3
2.5、Spark-Core中的框架选择
1、http://spark.apache.org/docs/latest/rdd-programming-guide.html,找到rdd-persisitance
| Storage Level | Meaning |
|---|---|
| MEMORY_ONLY | Store RDD as deserialized Java objects in the JVM. If the RDD does not fit in memory, some partitions will not be cached and will be recomputed on the fly each time they’re needed. This is the default level. |
| MEMORY_ONLY_SER | |
| (Java and Scala) | Store RDD as serialized Java objects (one byte array per partition). This is generally more space-efficient than deserialized objects, especially when using a fast serializer, but more CPU-intensive to read. |
此处需要了解到的:
1、缓存可以使用
2、内存和内存序列号
2.6、recomputing重算的概念
生产场景举例:
1、假设一个rdd,数据在hdfs上,使用textFile把数据读取进来,做了map操作后变成了一个新的rdd,而后触发了一个action;
-我们知道的对一个rdd做计算就是对rdd中的每一个分区做计算,在rdd1中做了一个reduceByKey或groupByKey的操作,就变成了两个rdd;分区中的数据存放位置不确定;
2、假设rdd1中的第三个partition挂掉了,根据我们rdd的依赖关系,spark会找到父rdd的信息,这个叫做血缘关系。
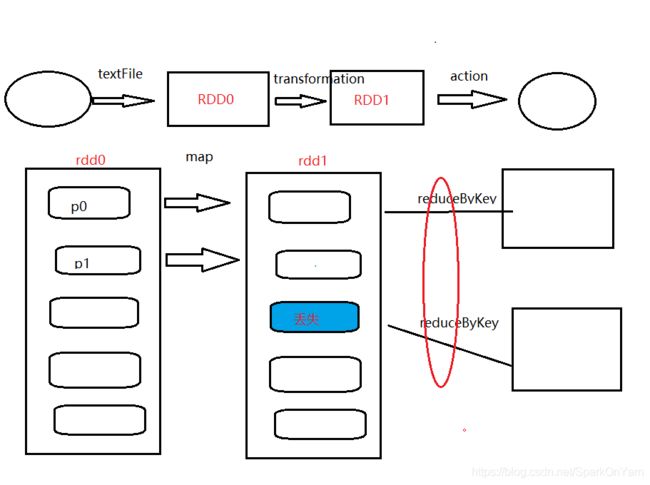
2.7、Spark中的宽窄依赖
对上图需要进行拆分,reduceByKey前的是stage0,reduceByKey后的是stage1;这就涉及到了依赖,Dependency依赖:
Spark中有两大依赖:宽窄依赖
Narrow:窄依赖
定义:一个父rdd的partition只能被子RDD的某个partition使用一次(map filter union join with input co-partitioned)
Wide:宽依赖,带shuffle的
定义:一个父rdd的partition能被子rdd的partition使用多次
groupByKey:一份数据会被子rdd的partition使用多次
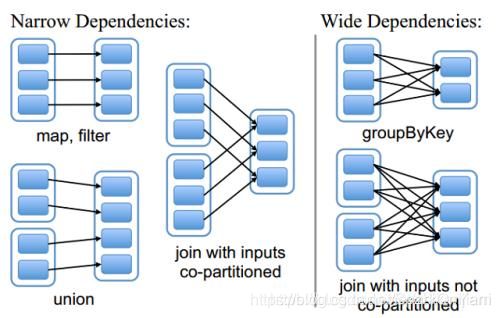
对于宽窄依赖的区别:
- 对于窄依赖:父rdd的某个partition丢了,问题不大,只需要把父rdd的某个partition单独算出来就行了;
- 对于宽依赖,父rdd的partition丢了,所有的都需要重新计算。
第二张图分析:
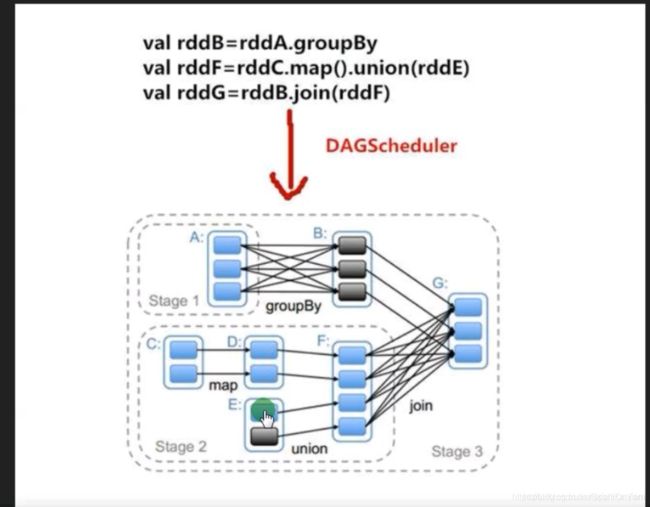
解析:
A遇到groupBy拆分一个stage,黑色区域理解为挂了,join的时候要根据key来shuffle的,在action之前遇到shuffle算子就会变成2个stage;
action产生job,job由N个stage构成,stage由N个task构成;
MapReduce:1+1+1+1
1+1 ==》 2
2+1 ==》 3
3+1 ==》4
对于窄依赖来说,以pipeline的方式一条路干到底;
2.8、Working with key-value Pairs
1、通过key-value访问,最常用的方式是分布式中的shuffle操作,就像group通过key聚合的操作
2、The Key-value operations are available in the PairRDD class, which automatically wraps around an RDD of tuples.
我们在写wordcount的时候并没有用到pairRDD,文本中是单词,为每个单词赋上1个1,然后一个reduceByKey进行分发;
查看PairRDDFunctions.scala的源码:
1、reduceByKey就是PairRDDFunctions这个类中的:
/**
* Merge the values for each key using an associative and commutative reduce function. This will
* also perform the merging locally on each mapper before sending results to a reducer, similarly
* to a "combiner" in MapReduce. Output will be hash-partitioned with the existing partitioner/
* parallelism level.
*/
def reduceByKey(func: (V, V) => V): RDD[(K, V)] = self.withScope {
reduceByKey(defaultPartitioner(self), func)
}
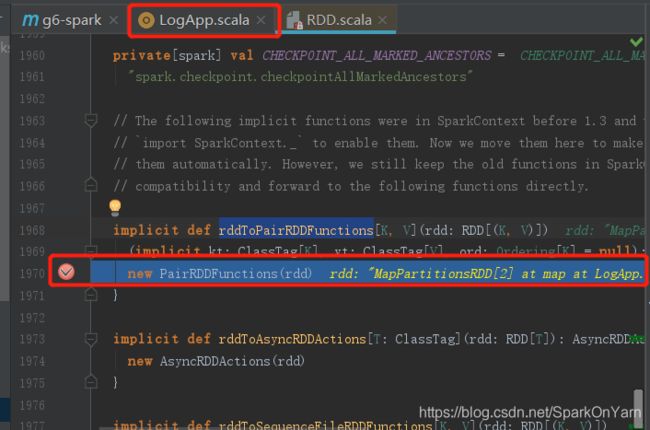
2、在RDD.scala中查看这个方法:
implicit def rddToPairRDDFunctions[K, V](rdd: RDD[(K, V)])
(implicit kt: ClassTag[K], vt: ClassTag[V], ord: Ordering[K] = null): PairRDDFunctions[K, V] = {
new PairRDDFunctions(rdd)
}
//人到超人传一个人进来,里面其实是new了一个超人出去,把人放到里面
测试程序中有reduceByKey算子会不会使用RDD.scala中的rddToPairRDDFunctions这个方法:
在这个地方打个断点,debug测试运行:
面试题:
reduceByKey是哪个类中的算子?
- PairRDDFunctions这个类
三、回顾Hadoop中的Yarn
Yarn的产生背景:
Hadoop
Spark Standalone
MPI
统一的资源管理和调度 --> Yarn
解析:
1、HDFS:负责可靠的存储
2、YARN:集群资源的管理 --> 一个操作系统级别的资源管理和调度框架
3、在集群上可以跑批处理作业MR、Interactive和Tez(Hive底层的执行引擎有Spark、Tez、MR)、online HBase、Streaming(Storm、Flink),多种计算框架可以共享集群资源,按需分配 -->提升资源的利用率
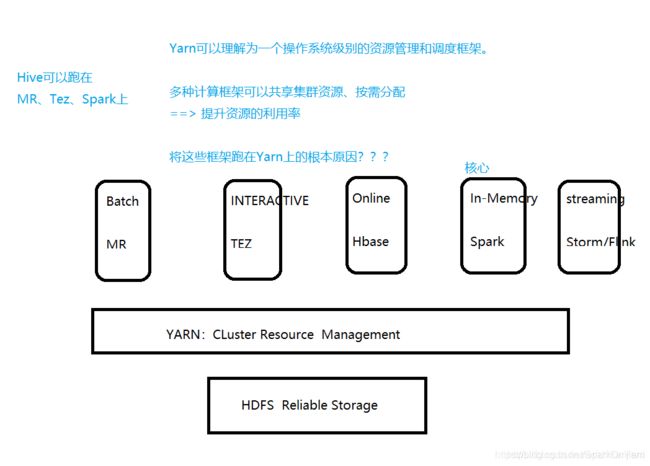
Hadoop中Yarn的架构及各自的职责?
- RM、NM、AM、Container各自的职责
- Yarn的执行流程
https://blog.csdn.net/SparkOnYarn/article/details/105126486#id_2.1
3.1、Spark on Yarn的概述
在Mapreduce中的时候(基于进程),每一个task都是在它自己的进程中,maptask和reducetask是进程级别,每一个task运行完以后,整个进程就结束了;
在Spark中的时候(基于线程),一个executor中可以跑多个task,在应用程序的整个生命周期中executor都会存在的,即使没有job在运行。
好处:tasks都能直接启动以线程的方式,速度快,以内存的方式计算
Cluster Manager:一个Spark应用程序过来以后,首先到的是CM,通过它来申请资源的;local、standalone、yarn、k8s就意味着它是可插拔的。
Worker的概念:在YARN上面是没有的,我们的executor是运行在container里面的(memory of container > executor memory)
对于on yarn的模式,Spark仅仅只是一个客户端而已:
只要客户端有权限,提交的到yarn上即可
3.2、Spark on Yarn的使用
确保要有hadoop_conf_dir和yarn_conf_dir,一直在说spark作为一个客户端,那它要连接到集群的话,肯定需要告诉他们一些配置;一个作业会启很多个executor,多个executor上的配置如何共享呢?
Deploy Mode:
client:Driver在本地,终端不能关
cluster:Driver在集群上,启动以后driver运行起来就在集群上
Client模式测试:
[hadoop@hadoop001 bin]$ ./spark-shell --master yarn client
Exception in thread "main" org.apache.spark.SparkException: When running with master 'yarn' either HADOOP_CONF_DIR or YARN_CONF_DIR must be set in the environment.
at org.apache.spark.deploy.SparkSubmitArguments.error(SparkSubmitArguments.scala:657)
at org.apache.spark.deploy.SparkSubmitArguments.validateSubmitArguments(SparkSubmitArguments.scala:290)
at org.apache.spark.deploy.SparkSubmitArguments.validateArguments(SparkSubmitArguments.scala:251)
at org.apache.spark.deploy.SparkSubmitArguments.<init>(SparkSubmitArguments.scala:120)
at org.apache.spark.deploy.SparkSubmit$$anon$2$$anon$1.<init>(SparkSubmit.scala:911)
at org.apache.spark.deploy.SparkSubmit$$anon$2.parseArguments(SparkSubmit.scala:911)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:81)
at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:924)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:933)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
提示需要指定HADOOP_CONF_DIR和YARN_CONF_DIR,所以需要在如下目录下进行指定:
1、进入Spark_HOME/conf目录,拷贝一份配置文件:
[hadoop@hadoop001 conf]$ pwd
/home/hadoop/app/spark/conf
[hadoop@hadoop001 conf]$ ll
-rwxr-xr-x 1 hadoop hadoop 4461 Jun 11 17:25 spark-env.sh
-rwxr-xr-x 1 hadoop hadoop 4221 Jun 4 21:32 spark-env.sh.template
2、在如下目录中编辑配置如下:
export JAVA_HOME=/usr/java/jdk1.8.0_45
export SCALA_HOME=/home/hadoop/app/scala-2.11.12
export SPARK_WORKING_MEMORY=1g
export SPARK_MASTER_IP=master
export HADOOP_HOME=/home/hadoop/app/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
再次启动即可,注意两者启动的区别:
[hadoop@hadoop001 bin]$ ./spark-shell --master yarn client
Spark context Web UI available at http://hadoop001:4040
Spark context available as 'sc' (master = yarn, app id = application_1591800276964_0001).
Spark session available as 'spark'.
[hadoop@hadoop001 bin]$ ./spark-shell --master locla[2]
Spark context Web UI available at http://hadoop001:4040
Spark context available as 'sc' (master = local[2], app id = local-1591868342145).
Spark session available as 'spark'.
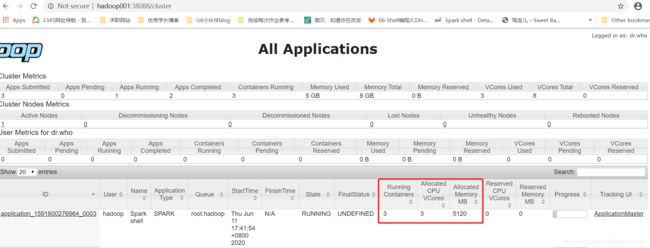
进入到Yarn的UI界面:如下三个参数的由来?
Running Container:3
Allocated CPU VCores:3
Allocated Memory MB:5120
1、查看executors:有1个driver和2个executor(spark-shell), --num-executors NUM默认数量就是2个。
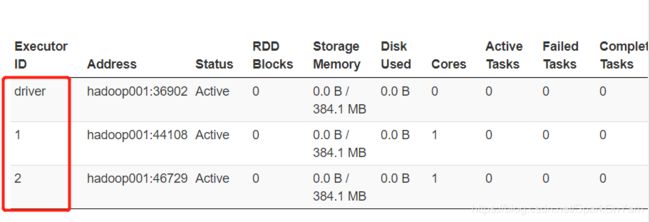
Spark启动以后,进程声明周期和Spark是一致的,我们此时通过jps命令去看一个东西:
[hadoop@hadoop001 bin]$ jps
16915 SecondaryNameNode
17270 ResourceManager
29095 CoarseGrainedExecutorBackend
28183 SparkSubmit
17368 NodeManager
29034 CoarseGrainedExecutorBackend
30682 Jps
16698 DataNode
16588 NameNode
28926 ExecutorLauncher
1、executor是进程,第一个executor
[hadoop@hadoop001 bin]$ ps -ef|grep 29095
hadoop 29095 29091 1 17:42 ? 00:00:07 /usr/java/jdk1.8.0_45/bin/java -server -Xmx1024m -Djava.io.tmpdir=/home/hadoop/tmp/nm-local-dir/usercache/hadoop/appcache/application_1591800276964_0003/container_1591800276964_0003_01_000003/tmp -Dspark.driver.port=44741 -Dspark.yarn.app.container.log.dir=/home/hadoop/app/hadoop-2.6.0-cdh5.16.2/logs/userlogs/application_1591800276964_0003/container_1591800276964_0003_01_000003 -XX:OnOutOfMemoryError=kill %p org.apache.spark.executor.CoarseGrainedExecutorBackend --driver-url spark://CoarseGrainedScheduler@hadoop001:44741 --executor-id 2 --hostname hadoop001 --cores 1 --app-id application_1591800276964_0003 --user-class-path file:/home/hadoop/tmp/nm-local-dir/usercache/hadoop/appcache/application_1591800276964_0003/container_1591800276964_0003_01_000003/__app__.jar
hadoop 30727 26700 0 17:53 pts/2 00:00:00 grep 29095
2、第二个executor:
[hadoop@hadoop001 bin]$ ps -ef|grep 29034
hadoop 29034 29029 1 17:42 ? 00:00:07 /usr/java/jdk1.8.0_45/bin/java -server -Xmx1024m -Djava.io.tmpdir=/home/hadoop/tmp/nm-local-dir/usercache/hadoop/appcache/application_1591800276964_0003/container_1591800276964_0003_01_000002/tmp -Dspark.driver.port=44741 -Dspark.yarn.app.container.log.dir=/home/hadoop/app/hadoop-2.6.0-cdh5.16.2/logs/userlogs/application_1591800276964_0003/container_1591800276964_0003_01_000002 -XX:OnOutOfMemoryError=kill %p org.apache.spark.executor.CoarseGrainedExecutorBackend --driver-url spark://CoarseGrainedScheduler@hadoop001:44741 --executor-id 1 --hostname hadoop001 --cores 1 --app-id application_1591800276964_0003 --user-class-path file:/home/hadoop/tmp/nm-local-dir/usercache/hadoop/appcache/application_1591800276964_0003/container_1591800276964_0003_01_000002/__app__.jar
hadoop 30799 26700 0 17:54 pts/2 00:00:00 grep 29034
3、driver
[hadoop@hadoop001 bin]$ ps -ef|grep 28926
hadoop 28926 28916 1 17:42 ? 00:00:10 /usr/java/jdk1.8.0_45/bin/java -server -Xmx512m -Djava.io.tmpdir=/home/hadoop/tmp/nm-local-dir/usercache/hadoop/appcache/application_1591800276964_0003/container_1591800276964_0003_01_000001/tmp -Dspark.yarn.app.container.log.dir=/home/hadoop/app/hadoop-2.6.0-cdh5.16.2/logs/userlogs/application_1591800276964_0003/container_1591800276964_0003_01_000001 org.apache.spark.deploy.yarn.ExecutorLauncher --arg hadoop001:44741 --properties-file /home/hadoop/tmp/nm-local-dir/usercache/hadoop/appcache/application_1591800276964_0003/container_1591800276964_0003_01_000001/__spark_conf__/__spark_conf__.properties
hadoop 30817 26700 0 17:54 pts/2 00:00:00 grep 28926
3.3、spark-shell上测试Client模式
spark-shell上测试Client模式:
scala> sc.textFile("file:///home/hadoop/data/ruozeinput.txt").flatMap(x =>x.split("\t")).map((_,1)).reduceByKey(_+_).collect
重启yarn后,是有两个stage,因为涉及到reduceByKey,有shuffle操作。
此时client模式,退出出来后,再次打开UI界面肯定就是已打不开的。
3.4、spark on yarn上测试Cluster模式 && 报错信息排查
1、spark-shell上测试Cluster模式:
- cluster是不能跑在spark-shell上的
[hadoop@hadoop001 bin]$ ./spark-shell --master yarn --deploy-mode cluster
Exception in thread "main" org.apache.spark.SparkException: Cluster deploy mode is not applicable to Spark shells.
cluster模式只能通过spark-submit的方式进行提交:
1、提交的代码:
[hadoop@hadoop001 bin]$ ./spark-submit --master yarn \
--deploy-mode cluster \
--driver-memory 500m \
--executor-memory 500m \
--executor-cores 1 \
--class com.ruozedata.bigdata.SparkCore01.WordCountApp \
/home/hadoop/lib/g6-spark-1.0.jar \
hdfs://hadoop004:9000/data/input/ruozeinput.txt \
hdfs://hadoop004:9000/data/output4
这段spark-submit代码剖析:
--master 运行模式
--driver-memory 运行内存
--executor-memory --executor-cores 执行器设置
--class 代码所在的类,idea中在object类下使用copy reference拷贝出路径即可
跟上idea中WordCountApp代码所打出的jar包;
wordcount输入文件路径,对应代码参数的args0
wordcount输出文件目录,对应代码参数中的args1
报错日志信息如下:
20/06/08 07:35:02 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
20/06/08 07:35:05 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
20/06/08 07:35:05 INFO yarn.Client: Requesting a new application from cluster with 1 NodeManagers
20/06/08 07:35:06 INFO yarn.Client: Verifying our application has not requested more than the maximum memory capability of the cluster (8192 MB per container)
20/06/08 07:35:06 INFO yarn.Client: Will allocate AM container, with 884 MB memory including 384 MB overhead
20/06/08 07:35:06 INFO yarn.Client: Setting up container launch context for our AM
20/06/08 07:35:06 INFO yarn.Client: Setting up the launch environment for our AM container
20/06/08 07:35:06 INFO yarn.Client: Preparing resources for our AM container
20/06/08 07:35:07 WARN yarn.Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.
20/06/08 07:35:20 INFO yarn.Client: Uploading resource file:/tmp/spark-efa80a19-9200-4135-9b4f-796ca36e30ac/__spark_libs__5763193401729057789.zip -> hdfs://hadoop004:9000/user/hadoop/.sparkStaging/application_1591572541236_0001/__spark_libs__5763193401729057789.zip
20/06/08 07:35:28 INFO yarn.Client: Uploading resource file:/home/hadoop/lib/g6-spark-1.0.jar -> hdfs://hadoop004:9000/user/hadoop/.sparkStaging/application_1591572541236_0001/g6-spark-1.0.jar
20/06/08 07:35:28 INFO yarn.Client: Uploading resource file:/tmp/spark-efa80a19-9200-4135-9b4f-796ca36e30ac/__spark_conf__6255925981814631459.zip -> hdfs://hadoop004:9000/user/hadoop/.sparkStaging/application_1591572541236_0001/__spark_conf__.zip
20/06/08 07:35:29 INFO spark.SecurityManager: Changing view acls to: hadoop
20/06/08 07:35:29 INFO spark.SecurityManager: Changing modify acls to: hadoop
20/06/08 07:35:29 INFO spark.SecurityManager: Changing view acls groups to:
20/06/08 07:35:29 INFO spark.SecurityManager: Changing modify acls groups to:
20/06/08 07:35:29 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(hadoop); groups with view permissions: Set(); users with modify permissions: Set(hadoop); groups with modify permissions: Set()
20/06/08 07:35:31 INFO yarn.Client: Submitting application application_1591572541236_0001 to ResourceManager
20/06/08 07:35:32 INFO impl.YarnClientImpl: Submitted application application_1591572541236_0001
20/06/08 07:35:33 INFO yarn.Client: Application report for application_1591572541236_0001 (state: ACCEPTED)
20/06/08 07:35:33 INFO yarn.Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: N/A
ApplicationMaster RPC port: -1
queue: root.hadoop
start time: 1591572931612
final status: UNDEFINED
tracking URL: http://hadoop004:38088/proxy/application_1591572541236_0001/
user: hadoop
20/06/08 07:35:38 INFO yarn.Client: Application report for application_1591572541236_0001 (state: ACCEPTED)
20/06/08 07:35:39 INFO yarn.Client: Application report for application_1591572541236_0001 (state: ACCEPTED)
20/06/08 07:35:40 INFO yarn.Client: Application report for application_1591572541236_0001 (state: ACCEPTED)
20/06/08 07:35:41 INFO yarn.Client: Application report for application_1591572541236_0001 (state: ACCEPTED)
20/06/08 07:35:42 INFO yarn.Client: Application report for application_1591572541236_0001 (state: ACCEPTED)
20/06/08 07:35:44 INFO yarn.Client: Application report for application_1591572541236_0001 (state: ACCEPTED)
20/06/08 07:35:45 INFO yarn.Client: Application report for application_1591572541236_0001 (state: ACCEPTED)
20/06/08 07:35:46 INFO yarn.Client: Application report for application_1591572541236_0001 (state: ACCEPTED)
20/06/08 07:35:47 INFO yarn.Client: Application report for application_1591572541236_0001 (state: ACCEPTED)
20/06/08 07:35:48 INFO yarn.Client: Application report for application_1591572541236_0001 (state: ACCEPTED)
20/06/08 07:35:49 INFO yarn.Client: Application report for application_1591572541236_0001 (state: ACCEPTED)
20/06/08 07:35:50 INFO yarn.Client: Application report for application_1591572541236_0001 (state: ACCEPTED)
20/06/08 07:35:51 INFO yarn.Client: Application report for application_1591572541236_0001 (state: ACCEPTED)
20/06/08 07:35:52 INFO yarn.Client: Application report for application_1591572541236_0001 (state: ACCEPTED)
20/06/08 07:35:53 INFO yarn.Client: Application report for application_1591572541236_0001 (state: ACCEPTED)
20/06/08 07:35:54 INFO yarn.Client: Application report for application_1591572541236_0001 (state: ACCEPTED)
20/06/08 07:35:55 INFO yarn.Client: Application report for application_1591572541236_0001 (state: ACCEPTED)
20/06/08 07:35:56 INFO yarn.Client: Application report for application_1591572541236_0001 (state: ACCEPTED)
20/06/08 07:35:57 INFO yarn.Client: Application report for application_1591572541236_0001 (state: ACCEPTED)
20/06/08 07:35:58 INFO yarn.Client: Application report for application_1591572541236_0001 (state: FAILED)
20/06/08 07:35:58 INFO yarn.Client:
client token: N/A
diagnostics: Application application_1591572541236_0001 failed 2 times due to AM Container for appattempt_1591572541236_0001_000002 exited with exitCode: 13
For more detailed output, check application tracking page:http://hadoop004:38088/proxy/application_1591572541236_0001/Then, click on links to logs of each attempt.
Diagnostics: Exception from container-launch.
Container id: container_1591572541236_0001_02_000001
Exit code: 13
Stack trace: ExitCodeException exitCode=13:
at org.apache.hadoop.util.Shell.runCommand(Shell.java:604)
at org.apache.hadoop.util.Shell.run(Shell.java:507)
at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:789)
at org.apache.hadoop.yarn.server.nodemanager.DefaultContainerExecutor.launchContainer(DefaultContainerExecutor.java:213)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:302)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:82)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
Container exited with a non-zero exit code 13
Failing this attempt. Failing the application.
ApplicationMaster host: N/A
ApplicationMaster RPC port: -1
queue: root.hadoop
start time: 1591572931612
final status: FAILED
tracking URL: http://hadoop004:38088/cluster/app/application_1591572541236_0001
user: hadoop
20/06/08 07:35:58 ERROR yarn.Client: Application diagnostics message: Application application_1591572541236_0001 failed 2 times due to AM Container for appattempt_1591572541236_0001_000002 exited with exitCode: 13
For more detailed output, check application tracking page:http://hadoop004:38088/proxy/application_1591572541236_0001/Then, click on links to logs of each attempt.
Diagnostics: Exception from container-launch.
Container id: container_1591572541236_0001_02_000001
Exit code: 13
Stack trace: ExitCodeException exitCode=13:
at org.apache.hadoop.util.Shell.runCommand(Shell.java:604)
at org.apache.hadoop.util.Shell.run(Shell.java:507)
at org.apache.hadoop.util.Shell$ShellCommandExecutor.execute(Shell.java:789)
at org.apache.hadoop.yarn.server.nodemanager.DefaultContainerExecutor.launchContainer(DefaultContainerExecutor.java:213)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:302)
at org.apache.hadoop.yarn.server.nodemanager.containermanager.launcher.ContainerLaunch.call(ContainerLaunch.java:82)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
Container exited with a non-zero exit code 13
Failing this attempt. Failing the application.
Exception in thread "main" org.apache.spark.SparkException: Application application_1591572541236_0001 finished with failed status
at org.apache.spark.deploy.yarn.Client.run(Client.scala:1149)
at org.apache.spark.deploy.yarn.YarnClusterApplication.start(Client.scala:1526)
at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:849)
at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:167)
at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:195)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:86)
at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:924)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:933)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
20/06/08 07:35:58 INFO util.ShutdownHookManager: Shutdown hook called
20/06/08 07:35:58 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-efa80a19-9200-4135-9b4f-796ca36e30ac
20/06/08 07:35:58 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-93f6d245-96db-4282-981e-40c0cf836f76
报错信息排查:
在控制台上输出的日志信息中提供了一个yarn任务运行的网址:
进入这个网址:http://hadoop004:38088/proxy/application_1591572541236_0001/Then
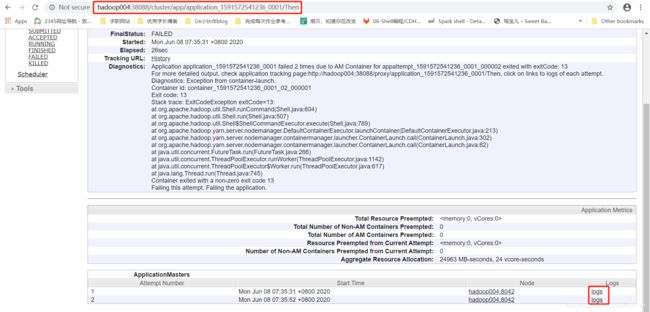
点击logs进行查看这个任务的日志信息:
1、提取到这个错误信息:
java.lang.IllegalArgumentException: System memory 466092032 must be at least 471859200. Please increase heap size using the --driver-memory option or spark.driver.memory in Spark configuration.
20/06/08 07:35:52 ERROR yarn.ApplicationMaster: User class threw exception: java.lang.IllegalArgumentException: System memory 466092032 must be at least 471859200. Please increase heap size using the --driver-memory option or spark.driver.memory in Spark configuration.
java.lang.IllegalArgumentException: System memory 466092032 must be at least 471859200. Please increase heap size using the --driver-memory option or spark.driver.memory in Spark configuration.
查看到的报错信息是:driver-memory不够的原因,解决办法:我在$SPARK_HOME/conf/spark-env.sh中把这个参数调成2g;
然后spark-submit提交的时候,修改内存信息:把–driver-memory调大即可。
发现–executor-cores=1这个参数设置了以后,lib下的这个jar包还是在的;如果这个参数没有设置,那么这个jar包中的数据都会被清空。
采用Spark on yarn的Cluster模式:
./spark-submit --master yarn \
--deploy-mode cluster \
--driver-memory 600m \
--executor-memory 600m \
--executor-cores 1 \
--class com.ruozedata.bigdata.SparkCore01.WordCountApp \
/home/hadoop/lib/g6-spark-1.0.jar \
hdfs://hadoop004:9000/data/input/ruozeinput.txt \
hdfs://hadoop004:9000/data/output5
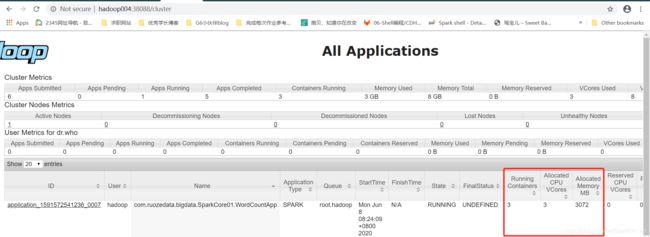
运行完成后是什么样子的?
[hadoop@hadoop004 lib]$ hdfs dfs -ls /data/output5
20/06/08 08:29:20 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 3 items
-rw-r--r-- 1 hadoop supergroup 0 2020-06-08 08:24 /data/output5/_SUCCESS
-rw-r--r-- 1 hadoop supergroup 19 2020-06-08 08:24 /data/output5/part-00000
-rw-r--r-- 1 hadoop supergroup 10 2020-06-08 08:24 /data/output5/part-00001
[hadoop@hadoop004 lib]$ hdfs dfs -text /data/output5/part-00000
20/06/08 08:29:29 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
(john,1)
(world,2)
[hadoop@hadoop004 lib]$ hdfs dfs -text /data/output5/part-00001
20/06/08 08:29:40 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
(hello,3)
总结:
区分跑在什么地方:client、cluster
对于ApplicationManager的职责:
Local模式:
AM:requesting resources
Cluster模式:
AM:除了申请资源还有task的调度