SparkStreaming socketTextStream
1、SparkStreaming programming-guide 地址
http://spark.apache.org/docs/latest/streaming-programming-guide.html
2、官网中给出SparkStreaming 中数据来源以及去向如下图所示

可以看到Spark 支持 Kafka, Flume, Kinesis, or TCP sockets,并且支持数据保存到 filesystems, databases, and live dashboards。
本文中程序运行于maven基础之上,故而给出所需要的pom文件:
org.apache.spark
spark-core_2.11
2.0.1
org.apache.spark
spark-streaming_2.11
2.0.1
其余source的maven如下
| Source | Artifact |
|---|---|
| Kafka | spark-streaming-kafka-0-8_2.11 |
| Flume | spark-streaming-flume_2.11 |
| Kinesis | spark-streaming-kinesis-asl_2.11 [Amazon Software License] |
本文首先测试最简单的消息来源,TCP Sockets。
3、下面将给出一段简单的SparkStreaming代码,本文将通过解释代码的方式,提出SparkStreaming中的知识点。
val ssc = new StreamingContext(conf, Seconds(10))
val stream = ssc.socketTextStream("218.193.154.155",9999)
// 简单地打印每一批的几个元素
// 批量运行
val events = stream.map{
record =>
val event = record.split(",")
(event(0),event(1),event(2))
}
events.foreachRDD{
rdd =>
val numPurchases = rdd.count()
val uniqueUsers = rdd.map{
case(user, _, _) => user
}.distinct.count
val totalRevenue = rdd.map{
case(_, _, price) => price.toDouble
}.sum()
val productsByPopularity = rdd.map{
case(user, product, price) => (product,1)
}.reduceByKey(_ + _).collect().sortBy(-_._2)
val popular = productsByPopularity(0)
println(s"Total purchases : ${numPurchases}")
println(s"uniqueUsers : ${uniqueUsers}")
println(s"Total Revenue : ${totalRevenue}")
println(s"mostPopluar : ${popular._1}")
}
// stream.print()
ssc.start()
ssc.awaitTermination()本句代码目标明确就是要创建StreamingContext对象,进而可以运行SparkStreaming程序。
但是这里有个Seconds(10) 需要注意,我们进入源码查看。
/**
* Create a StreamingContext by providing the configuration necessary for a new SparkContext.
* @param conf a org.apache.spark.SparkConf object specifying Spark parameters
* @param batchDuration the time interval at which streaming data will be divided into batches
*/
def this(conf: SparkConf, batchDuration: Duration) = {
this(StreamingContext.createNewSparkContext(conf), null, batchDuration)
} 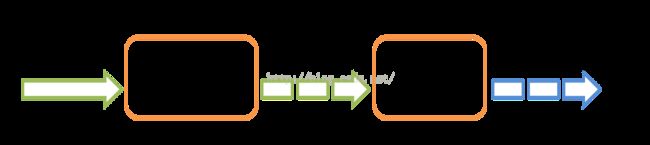
从上图可以清楚地看到,输入流数据经过SparkStreaming 处理,输出一个个处理单元,在流式数据中,最重要的特征之一是时间,这样便可以理解
batchDuration的作用,即根据时间截取数据流。
3-2)val stream = ssc.socketTextStream("218.193.154.155",9999)
其中socketTextStream 函数作用如下
/**
* Creates an input stream from TCP source hostname:port. Data is received using
* a TCP socket and the receive bytes is interpreted as UTF8 encoded `\n` delimited
* lines.
* @param hostname Hostname to connect to for receiving data
* @param port Port to connect to for receiving data
* @param storageLevel Storage level to use for storing the received objects
* (default: StorageLevel.MEMORY_AND_DISK_SER_2)
*/
通过指定hostname 以及port 创建一个socket输入流,注意这里的编码方式为UTF-8,并且以\n作为分隔。
storageLevel 同spark普通程序中数据的存储方式
返回结果是DStream,具体解释如下:
A Discretized Stream (DStream), the basic abstraction in Spark Streaming, is a continuous sequence of RDDs (of the same type) representing
a continuous stream of data.
一个Dstream就是一系列在时间上连续的相同类型的RDD集合,当然这些集合也代表着在时间上具有连续性的数据流。虽然DStream的操作和RDD
的操作极其相似,但DStream不等同于RDD,官方给出下图:
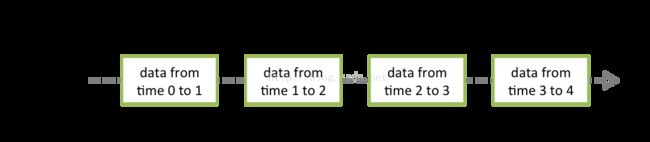
可以看到一个DStream的生命周期可以多个batchduartion,而RDD的生命周期,却仅限于某个batchduration之中。
例如DStream的window操作,可以很容易测试出来,windows中duration指定必须为batchduration的整数倍,即包含整数个RDD
3-3)
val events = stream.map{
record =>
val event = record.split(",")
(event(0),event(1),event(2))
}这里可以将一个DStream就看做成一个RDD,对RDD操作想必读者已经相当熟练,这里不再赘述。
3-4)events.foreachRDD
类似于RDD 的action算子,提取DStream中所有的数据流,并组装成RDD。
3-5) ssc.start()
启动SparkStreaming
3-6)ssc.awaitTermination()
等待结束