SparkStreaming---DStream
文章目录
- 1.DStream是什么
- 2.DStream创建
-
- 2.1 RDD队列
- 2.2 自定义数据源
- 3.DStream转换
-
- 3.1 无状态转换
-
- 3.1.1 Transformations
- 3.1.2 join
- 3.2 有状态转换操作
-
- 3.2.1 UpdateStateByKey
- 3.2.2 WindowOperations
- 4.DStream输出
1.DStream是什么
参考博文SparkStreaming入门
2.DStream创建
2.1 RDD队列
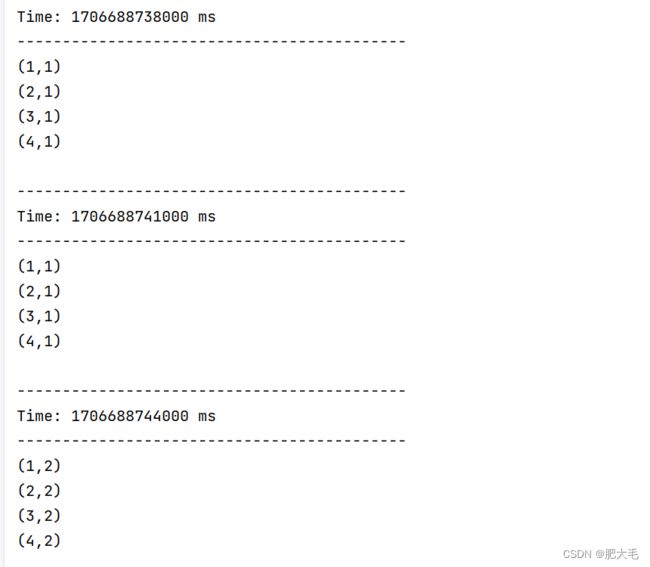
可以通过使用 queueStream(queueOfRDDs)来创建 DStream,每一个推送到这个队列中的 RDD,都会作为一个 DStream 处理。
def main(args: Array[String]): Unit = {
//1.初始化 Spark 配置信息
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("StreamWordCount")
//2.初始化 SparkStreamingContext
//处理区间为3s一次
val ssc = new StreamingContext(sparkConf, Seconds(3))
//创建RDD队列
val rddQueue = new mutable.Queue[RDD[Int]]()
//创建QueueInputDStream
//oneAtTime=false表示同时处理队列中所有的RDD
val inputStream: InputDStream[Int] = ssc.queueStream(rddQueue, oneAtATime = false)
//对DStream处理
val mapStream: DStream[(Int, Int)] = inputStream.map((_, 1))
val resDStream: DStream[(Int, Int)] = mapStream.reduceByKey(_ + _)
resDStream.print()
//启动SparkStreamingContext
ssc.start()
//向RDD队列中放入RDD
for(i <- 1 to 5) {
rddQueue+=ssc.sparkContext.makeRDD(List(1,2,3,4))
Thread.sleep(2000)
}
//等待接收数据
ssc.awaitTermination()
}
2.2 自定义数据源
用户自定义数据源需要继承 Receiver,并实现 onStart、onStop 方法来自定义数据源采集。
class MyReceiver(host:String,port:Int) extends Receiver[String](StorageLevel.MEMORY_ONLY)
{
//最初启动的时候,调用该方法,读数据并将数据发送给 Spark
override def onStart(): Unit = {
new Thread("Receiver"){
override def run(){
receive()
}
}.start()
}
///读数据并将数据发送给 Spark
def receive(): Unit = {
//创建Socket
val socket: Socket = new Socket(host,port)
//创建变量用于接收端口穿过来的数据
var input:String=null
//创建BufferedReader用于读取端口传来的数据
val reader: BufferedReader = new BufferedReader(new InputStreamReader(socket.getInputStream, StandardCharsets.UTF_8))
//读取数据
input=reader.readLine()
//当 receiver 没有关闭并且输入数据不为空
while(!isStopped() && input != null){
//循环发送数据给 Spark
store(input)
input=reader.readLine()
}
//跳出循环则关闭资源
reader.close()
socket.close()
//重启任务
restart("restart")
}
override def onStop(): Unit = {
}
}
使用自定义数据源采集数据
def main(args: Array[String]): Unit = {
//1.初始化 Spark 配置信息
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("StreamWordCount")
//2.初始化 SparkStreamingContext
//处理区间为3s一次
val ssc = new StreamingContext(sparkConf, Seconds(3))
//3.创建自定义 receiver 的 Streaming
val lineStream = ssc.receiverStream(new MyReceiver("localhost", 9999))
//4.处理接收的数据
val words: DStream[String] = lineStream.flatMap(_.split(" "))
val wordMap: DStream[(String, Int)] = words.map((_, 1))
val res = wordMap.reduceByKey(_ + _)
res.print()
//启动SparkStreamingContext
ssc.start()
//等待接收数据
ssc.awaitTermination()
}
3.DStream转换
在SparkStreaming中,各个DStream之间是相互独立的,互不干扰的。
DStream 上的操作与 RDD 的类似,分为 Transformations(转换)和 Output Operations(输出)两种,此外转换操作中还有一些比较特殊的原语,如:updateStateByKey()、transform()以及各种 Window 相关的原语。
3.1 无状态转换
无状态转化操作就是把简单的 RDD 转化操作应用到每个批次上,也就是转化 DStream 中的每一个 RDD。即一次对一个批次的RDD执行转换操作。
3.1.1 Transformations
在Spark Streaming中,transform操作是一个强大的功能,允许你将一个DStream转换成一个新的DStream。 它类似于Spark Core中的flatMap和map操作。你可以使用它来执行各种转换操作,例如过滤、分组、连接等。原RDD保持不变。
def main(args: Array[String]): Unit = {
//1.初始化 Spark 配置信息
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("StreamWordCount")
//2.初始化 SparkStreamingContext
//处理区间为3s一次
val ssc = new StreamingContext(sparkConf, Seconds(3))
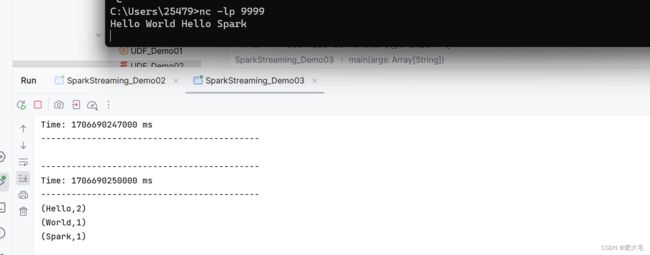
//3.通过监控端口创建 DStream,读进来的数据为一行行
val lines = ssc.socketTextStream("localhost", 9999)
//4.使用transform来转换
val resTransform = lines.transform(rdd => {
val words = rdd.flatMap(_.split(" "))
val wordMap = words.map((_, 1))
val res = wordMap.reduceByKey(_ + _)
res
})
//打印
resTransform.print()
//启动SparkStreamingContext
ssc.start()
//等待接收数据
ssc.awaitTermination()
}
3.1.2 join
两个DStream流之间的 join 需要两个流的批次大小一致,这样才能做到同时触发计算。计算过程就是对当前批次的两个流中各自的 RDD 进行 join,与两个 RDD 的 join 效果相同。
def main(args: Array[String]): Unit = {
//1.初始化 Spark 配置信息
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("StreamWordCount")
//2.初始化 SparkStreamingContext
//处理区间为3s一次
val ssc = new StreamingContext(sparkConf, Seconds(3))
//3.通过监控端口创建 DStream,读进来的数据为一行行
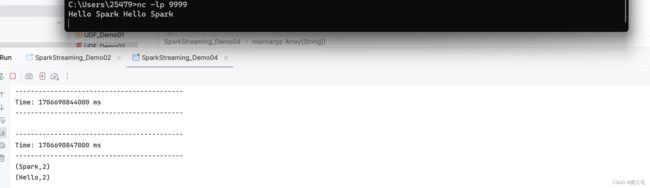
val line9999: ReceiverInputDStream[String] = ssc.socketTextStream("localhost", 9999)
val line8888: ReceiverInputDStream[String] = ssc.socketTextStream("localhost", 8888)
//4.将两个流转换为K,V类型
val lines1: DStream[(String, Int)] = line8888.flatMap(_.split(" ")).map((_,1))
val lines2: DStream[(String, Int)] = line9999.flatMap(_.split(" ")).map((_,11))
//5.使用join来对两个DStream进行连接
var resTransform: DStream[(String, (Int, Int))] =lines1.join(lines2)
//打印
resTransform.print()
//启动SparkStreamingContext
ssc.start()
//等待接收数据
ssc.awaitTermination()
}

3.2 有状态转换操作
在Spark Streaming中,有状态转换操作是指那些需要依赖之前批次数据或中间结果来计算当前批次数据的操作。这些操作在处理数据时,会在跨时间区间内跟踪数据的状态变化。在有状态转换的过程中,需要借助检查点(checkpoint)来完成转换。
3.2.1 UpdateStateByKey
UpdateStateByKey用于记录历史记录,有时,我们需要在 DStream 中跨批次维护状态(例如流计算中累加 wordcount)。针对这种情况,updateStateByKey()为我们提供了对一个状态变量的访问,用于键值对形式的 DStream。给定一个由(键,事件)对构成的 DStream,并传递一个指定如何根据新的事件更新每个键对应状态的函数,它可以构建出一个新的 DStream,其内部数据为(键,状态) 对。
updateStateByKey() 的结果会是一个新的 DStream,其内部的 RDD 序列是由每个时间区间对应的(键,状态)对组成的。
def main(args: Array[String]): Unit = {
//定义状态更新方法:参数 seq 为当前批次单词数量,state 为以往批次单词数量
val updateFuc = (seq:Seq[Int],state:Option[Int])=>{
//当前批次的单词数量
val updateSeq: Int = seq.foldLeft(0)((x, y) => x + y)
//以往批次的单词数量
val updateState:Int = state.getOrElse(0)
Some(updateSeq+updateState)
}
//1.初始化 Spark 配置信息
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("StreamWordCount")
//2.初始化 SparkStreamingContext
//处理区间为3s一次
val ssc = new StreamingContext(sparkConf, Seconds(3))
ssc.checkpoint("./ck")
val line9999: ReceiverInputDStream[String] = ssc.socketTextStream("localhost", 9999)
val wordMap: DStream[(String, Int)] = line9999.flatMap(_.split(" ")).map((_,1))
val res = wordMap.updateStateByKey[Int](updateFuc)
//打印
res.print()
//启动SparkStreamingContext
ssc.start()
//等待接收数据
ssc.awaitTermination()
}
3.2.2 WindowOperations
Window Operations 可以设置窗口的大小和滑动窗口的间隔来动态的获取当前 Steaming 的允许状态。所有基于窗口的操作都需要两个参数,分别为窗口时长以及滑动步长。
注意:窗口时长和滑动步长这两者都必须为采集周期大小的整数倍。
实现需求:WordCount案例:3 秒一个批次,窗口 12 秒,滑步 6 秒。
def main(args: Array[String]): Unit = {
//1.初始化 Spark 配置信息
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("StreamWordCount")
//2.初始化 SparkStreamingContext
//处理区间为3s一次
val ssc = new StreamingContext(sparkConf, Seconds(3))
ssc.checkpoint("./ck")
val lines = ssc.socketTextStream("localhost", 9999)
val dataMap: DStream[(String, Int)] = lines.flatMap(_.split(" ")).map((_, 1))
//窗口 12 秒,滑步 6 秒
val wordCountByWindows = dataMap.reduceByKeyAndWindow((a: Int, b: Int) => {
a + b
}, Seconds(12), Seconds(6))
wordCountByWindows.print()
//启动SparkStreamingContext
ssc.start()
//等待接收数据
ssc.awaitTermination()
}
reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks]):
当在一个(K,V)对的DStream上调用此函数,会返回一个新(K,V)对的DStream,此处通过对滑动窗口中批次数据使用
reduce 函数来整合每个 key 的 value 值。
参数解答:windowLength 是滑动窗口的大小。
slideInterval 是滑动窗口的滑动间隔。这意味着每6秒,窗口会向前滑动一次。
关于 Window 的操作还有如下方法:
(1)window(windowLength, slideInterval): 基于对源 DStream 窗化的批次进行计算返回一个新的 Dstream;
(2)countByWindow(windowLength, slideInterval): 返回一个滑动窗口计数流中的元素个数;
(3)reduceByWindow(func, windowLength, slideInterval): 通过使用自定义函数整合滑动区间流元素来创建>一个新的单元素流;
(4)reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks]): 这个函数是上述函数的变化版本,每个窗口的 reduce 值都是通过用前一个窗的 reduce 值来递增计算。通过 reduce 进入到滑动窗口数据并”反向 reduce”离开窗口的旧数据来实现这个操作。一个例子是随着窗口滑动对 keys 的“加”“减”计数。当窗口较大而滑动步数较小时,可以使用该函数来避免重复计算。
4.DStream输出
输出操作指定了对流数据经转化操作得到的数据所要执行的操作(例如把结果推入外部数据库或输出到屏幕上)。与 RDD 中的惰性求值类似,如果一个 DStream 及其派生出的 DStream 都没有被执行输出操作,那么这些 DStream 就都不会被求值。 如果 StreamingContext 中没有设定输出操作,整个 context 就都不会启动。
