Spark Streaming小程序试验-《单词统计》
1. 试验目标
a . 熟悉spark Streaming操作流程(编程-》打包-》程序提交运行-》job运行监控)
b. 熟悉spark Streaming 运行,和使用场景有初步了解
c .熟悉Spark Streaming基本编程,对spark函数有初步使用 ,flatMap,map,reduceByKey..
2.前提
a . 软件安装:
nc(模拟数据实时输入工具),spark-2.2.0 , sbt-1.1.0, scala-2.11.8

3.编程
程序源码:
import org.apache.spark._
import org.apache.spark.streaming._
object StreamingWordCount {
def main(args: Array[String]){
//config the sparksession
//spark 设置Spark集群地址
val conf=new SparkConf().setMaster("spark://master:7077").setAppName("NetworkWordCount")
// create the streaming context
// 创建Streaming 上下文,跟SparkContext 类似,多一个参数,设置收集数据源的时间间隔(Dstream 按照时间批次收集5s,每5s生成一个RDD)
val ssc= new StreamingContext(conf,Seconds(5))
//conf the socket to reciver the words
//设置Spark Streaming 监控的socket,数据流通过该socket传到spark,生成小的RDD,之后传入spark 做处理
val lines=ssc.socketTextStream("10.0.1.118",9800)
//split the string to the word
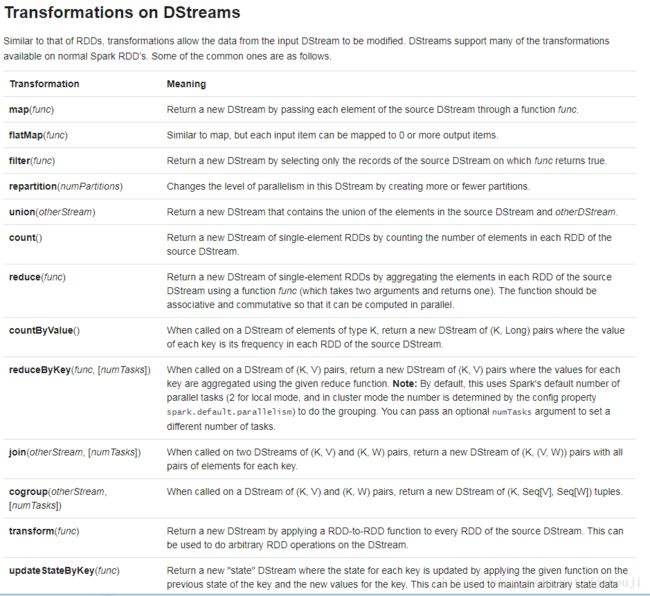
//flatMap 后面通过图说明这个函数跟Map区别,通过flatMap 函数后每个RDD中内容到变成单词,再经过map 映射成元组key就是单词,values为1
//例如: 输入 I Love You , 输出:[(I,1),(Love,1),(You,1)]
val words=lines.flatMap(_.split(" ")).map(word=>(word,1))
//reduce the words
//对上面的数组进行计数,想听的key值value相加,例如:(You,1) (You,1)=>(You,2)
val wordscount=words.reduceByKey((x,y)=>x+y)
//output the result
//Dstrea 输出,print() 会打印RDD前10个元数。
wordscount.print()
//流启动
ssc.start()
//等待流终止,可以用awaitTerminationOrTimeout(3600)设置超时时间
ssc.awaitTermination();
}
}4.打包
将上面程序保存为StreamingWordCount.scala,目录结构(我的整个项目是房子一个WordsCount目录下/workscript/WordsCount):
[root@master WordsCount]# pwd
/workscript/WordsCount
[root@master WordsCount]# find .
.
./src
./src/main
./src/main/scala
./src/main/scala/StreamingWordCount.scala
./simple.sbt
[root@master WordsCount]# ll
drwxrwxr-x 3 hadoop hadoop 17 Feb 8 22:57 src
新建文件simple.sbt,内容如下:
[root@master WordsCount]# cat simple.sbt # 文件版本配置跟上面软件安装截图相匹配。
name := "StreamingWordCount"
version := "1.0"
scalaVersion := "2.11.8"
libraryDependencies += "org.apache.spark" %% "spark-streaming" % "2.2.1" #添加依赖包,这例如果添加依赖错了,在提交job会找不到类。 说明如果有多个依赖:
libraryDependencies ++= Seq(
groupID % artifactID % revision,
groupID % otherID % otherRevision
)sbt 官网依赖配置:https://www.scala-sbt.org/0.13/docs/zh-cn/Library-Dependencies.html
Maven包查询:http://search.maven.org/#search

执行打包:
[root@master WordsCount]# ll #进入WordsCount目录
total 4
-rwxrwxr-x 1 hadoop hadoop 144 Feb 9 01:16 simple.sbt
drwxrwxr-x 3 hadoop hadoop 17 Feb 8 22:57 src
[root@master WordsCount]# sbt package #执行打包,这个过程有点慢。。。。。。。。需要去下载依赖包,所以要联网,联网,当然可以本地(要先下载仓库)
[info] Updated file /workscript/WordsCount/project/build.properties: set sbt.version to 1.1.0
[info] Loading project definition from /workscript/WordsCount/project
[info] Updating ProjectRef(uri("file:/workscript/WordsCount/project/"), "wordscount-build")...
[info] Done updating.
[info] Loading project definition from /workscript/WordsCount/project
[info] Loading settings from simple.sbt ...
[info] Set current project to StreamingWordCount (in build file:/workscript/WordsCount/)
.....
[info] Compiling 1 Scala source to /workscript/WordsCount/target/scala-2.11/classes ...
[info] Done compiling.
[info] Packaging /workscript/WordsCount/target/scala-2.11/streamingwordcount_2.11-1.0.jar ...
[info] Done packaging.
[success] Total time: 475 s, completed Feb 9, 2018 1:29:25 AM
#打好的Jar包在目录/workscript/WordsCount/target/scala-2.11/streamingwordcount_2.11-1.0.jar
[root@master scala-2.11]# ll
total 12
drwxr-xr-x 2 root root 4096 Feb 9 01:29 classes
drwxr-xr-x 4 root root 45 Feb 9 01:25 resolution-cache
-rw-r--r-- 1 root root 4768 Feb 9 01:29 streamingwordcount_2.11-1.0.jar #注意权限5.0 提交Job
移动Jar 到指定目录(自定义,方便管理):
[root@master scala-2.11]# mv streamingwordcount_2.11-1.0.jar /home/hadoop/spark-2.2.0/example_jars/
#提交Job,job提交后通过nc 相socketTextStream("10.0.1.118",9800) 输入数据源。
[hadoop@master bin]$ ./spark-submit --class StreamingWordCount ~/spark-2.2.0/example_jars/streamingwordcount_2.11-1.0.jar
18/02/09 03:10:31 INFO spark.SparkContext: Running Spark version 2.2.0
18/02/09 03:10:48 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
18/02/09 03:10:55 INFO spark.SparkContext: Submitted application: NetworkWordCount
18/02/09 03:10:56 INFO spark.SecurityManager: Changing view acls to: hadoop
18/02/09 03:10:56 INFO spark.SecurityManager: Changing modify acls to: hadoop
18/02/09 03:10:56 INFO spark.SecurityManager: Changing view acls groups to:
18/02/09 03:10:56 INFO spark.SecurityManager: Changing modify acls groups to:
18/02/09 03:10:56 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(hadoop); groups with view permissions: Set(); users with modify permissions: Set(hadoop); groups with modify permissions: Set()
......
18/02/09 03:14:01 INFO scheduler.DAGScheduler: Job 33 finished: print at StreamingWordCount.scala:21, took 0.253337 s
-------------------------------------------
Time: 1518117240000 ms
-------------------------------------------
(remote,1)
(desktop,1)
(connect,1)
(application,1)
(agents,,1)
(YourKit,1)
(to,1)
(profiler,1)
(To,1)
(the,2)
18/02/09 03:14:01 INFO scheduler.JobScheduler: Finished job streaming job 1518117240000 ms.0 from job set of time 1518117240000 ms
数据源输入:
没有nc可以使用yum install nc 命令安装:
[hadoop@master ~]$ nc -lk 9800
To connect the YourKit desktop application to the remote profiler agents, #回车输入完毕
驱动节点显示,该显示如果在5s 内没有输入,则为空:

6.0 前端监控
网址:http://10.0.1.118:8080/


附录
Spark Streaming 编程指导:
http://spark.apache.org/docs/latest/streaming-programming-guide.html
Spark API :
http://spark.apache.org/docs/latest/api/scala/index.html#org.apache.spark.package

Dstream :
