hadoop伪分布模式
1.概要:
伪分布式就是在一台虚拟主机上同时开启以下所有进程
NameNode、DataNode、ResourceManager、NodeManager、JobHistoryServer
操作上
1、要在已经可以联网的虚拟机上安装好JDK+HADOOP,配置环境变量
2、配置相关文件
3、启动集群相关进程,并检查启动是否成功,尤其namenode格式化要注意删除data、logs文件夹
4、对hdfs文件增删改查操作,包括下载到本地Linux文件系统中。
5、在hadoop上运行任务,如hadoop自带的wordcount、grep示例
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar
wordcount /user/atguigu/input/ /user/atguigu/output
6、在web端查看文件系统或者任务的日志信息
2.环境变量的配置
jdk:
文件:将jdk的压缩包(jdk-8u171-linux-x64.tar.gz)放在/opt/software里
解压:tar -zxvf jdk-8u171-linux-x64.tar.gz -C /opt/module/
(解压到指定文件夹中,-C 不要漏)
pwd:进入/opt/module/jdk1.8.0_171,pwd复制jdk的根目录
vim /etc/profile编辑环境变量:
export JAVA_HOME=/opt/module/jdk1.8.0_171
export PATH=$PATH:$JAVA_HOME/bin
保存后将文件生效:source /etc/profile
测试环境变量:java -version
jdk环境变量配置成功
hadoop:
源文件:将hadoop的压缩包(hadoop-2.7.2.tar.gz)放在/opt/software里
解压:tar -zxvf hadoop-2.7.2.tar.gz -C /opt/module/
(解压到指定文件夹中,-C 不要漏)
pwd:进入/opt/module/hadoop-2.7.2,pwd复制hadoop的根目录
vim /etc/profile编辑环境变量:
export HADOOP_HOME=/opt/module/hadoop-2.7.2
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
保存后将文件生效:source /etc/profile
测试环境变量:hadoop version
hadoop环境变量配置成功
3.hadoop运行模式
本地模式:local,配置文件不需要改动
伪分布模式:只有一个节点,所有的hdfs+mapreduce+yarn在一台主机上
完全分布式:三台虚拟机模拟的hadoop集群,hdfs+mapreduce+yarn
4.hadoop文件系统
bin:hadoop+hdfs等命令
etc:配置文件
lib:本地库
sbin:集群启动脚本
share:示例
5.本地模式示例(JDK+Hadoop环境变量配置好就可以运行)
1. 创建在hadoop-2.7.2文件下面创建一个input文件夹
[atguigu@hadoop101 hadoop-2.7.2]$ mkdir input
2. 将hadoop的xml配置文件复制到input(提供数据源 共8个xml文件)
[atguigu@hadoop101 hadoop-2.7.2]$ cp etc/hadoop/*.xml input
3. 执行share目录下的mapreduce程序
[atguigu@hadoop101 hadoop-2.7.2]$ bin/hadoop jar(老师直接写的hadoop jar)
share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar grep(过滤) input /
(老师写这个斜杠了)output(不能提前创建) 'dfs[a-z.]+'(正则表达式 dfs开头a-z的任意字符 +)
4. 查看输出结果
[atguigu@hadoop101 hadoop-2.7.2]$ cat output/*
6. 伪分布模式的配置
熟练地可以直接去以下网址复制粘贴。
https://blog.csdn.net/qq_43141232/article/details/104840023
一、 启动HDFS并运行MapReduce程序
1. vim /opt/module/hadoop-2.7.2/etc/hadoop/hadoop-env.sh (25行,配置hadoop-env)
export JAVA_HOME=/opt/module/jdk1.8.0_171
2. vim /opt/module/hadoop-2.7.2/etc/hadoop/core-site.xml
fs.defaultFS
hdfs(协议)://hadoop101(主机名):9000(端口号)
(格式化后才有此目录)
hadoop.tmp.dir
/opt/module/hadoop-2.7.2/data/tmp
3. vim /opt/module/hadoop-2.7.2/etc/hadoop/hdfs-site.xml
dfs.replication
1
二、 YARN上运行MapReduce 程序
4. vim /opt/module/hadoop-2.7.2/etc/hadoop/yarn-env.sh (23行,配置yarn-env)
export JAVA_HOME=/opt/module/jdk1.8.0_171
5. vim /opt/module/hadoop-2.7.2/etc/hadoop/yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
hadoop101 (默认0.0.0.0本地模式)
6. vim /opt/module/hadoop-2.7.2/etc/hadoop/mapred-env.sh (16行,配置mapred-env)
export JAVA_HOME=/opt/module/jdk1.8.0_171
7. cd /opt/module/hadoop-2.7.2/etc/hadoop 进入hadoop目录
mv mapred-site.xml.template mapred-site.xml 修改文件名称
vim /opt/module/hadoop-2.7.2/etc/hadoop/mapred-site.xml
mapreduce.framework.name
yarn (默认本地local)
三、 配置历史服务器
历史服务器与下面配置的日志聚集,在于查看已经跑完的任务的日志(History+logs)
8. vim /opt/module/hadoop-2.7.2/etc/hadoop/mapred-site.xml
mapreduce.jobhistory.address
hadoop101:10020
mapreduce.jobhistory.webapp.address
hadoop101:19888
四、 配置日志的聚集
9. vim /opt/module/hadoop-2.7.2/etc/hadoop/yarn-site.xml
yarn.log-aggregation-enable
true
yarn.log-aggregation.retain-seconds
604800
(修改配置文件需要重启yarn)
至此配置项已经配置完毕。
7.相关进程的启动、关闭、查看
重新格式化的时候要将data与log文件夹删除。保证namespace+cluster ID等一致
先格式化NameNode
bin/hdfs namenode -FORMAT
相关进程以及启动命令如下:( 关闭进程就将start换成stop即可 )
NameNode sbin/hadoop-daemon.sh start namenode
DataNode sbin/hadoop-daemon.sh start datanode
ResourceManager sbin/yarn-daemon.sh start resourcemanager
NodeManager sbin/yarn-daemon.sh start nodemanager
JobHistoryServer sbin/mr-jobhistory-daemon.sh start historyserver
进程的查看 ( jps )
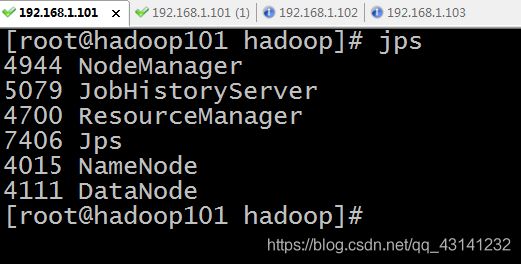
8.常见操作
(1)在hdfs文件系统上创建一个input文件夹,(并不是linux本地系统)。
bin/hdfs dfs -mkdir -p /user/atguigu/input
(2)将文件上传到hdfs文件系统上
bin/hdfs dfs -put wcinput/wc.input /user/atguigu/input/
(3)查看上传的文件是否正确
bin/hdfs dfs -ls /user/atguigu/input/
bin/hdfs dfs -cat /user/atguigu/input/wc.input
(4)运行mapreduce程序
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar
wordcount /user/atguigu/input/ /user/atguigu/output
(5)查看输出结果
命令行查看:
bin/hdfs dfs -cat /user/atguigu/output/*
(6)下载hdfs文件至本地(tmp_xs文件夹提前创建好,不然就是文件名)
hdfs dfs -get /user/atguigu/input/wc.input /opt/module/hadoop-2.7.2/tmp_xs
(7)删除文件或文件夹
bin/hdfs dfs -rm -f /user/atguigu/input/wc.input
bin/hdfs dfs -rm -r /user/atguigu/input
9.WEB端页面查看
重要三端口:50070(hdfs) + 8088(yarn) + 19888(日志)
1). web端查看HDFS文件系统
http://192.168.1.101:50070/dfshealth.html#tab-overview
注意:如果不能查看,看如下帖子处理
http://www.cnblogs.com/zlslch/p/6604189.html
2). yarn的浏览器页面查看
http://192.168.1.101:8088/cluster
3). 查看jobhistory
http://192.168.1.101:19888/jobhistory
4). 查看logs详情日志
http://192.168.1.101:19888/jobhistory


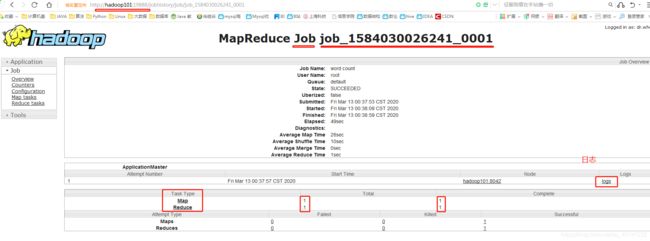

10.实操集群(单词计数)
(a)在hdfs文件系统上创建一个input文件夹,(并不是linux本地系统)。
bin/hdfs dfs -mkdir -p /user/atguigu/input
(b)将测试文件内容上传到文件系统上
bin/hdfs dfs -put wcinput/wc.input /user/atguigu/input/
(c)查看上传的文件是否正确
bin/hdfs dfs -ls /user/atguigu/input/
bin/hdfs dfs -cat /user/atguigu/ input/wc.input
(d)运行mapreduce程序
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar
wordcount /user/atguigu/input/ /user/atguigu/output
(e)查看输出结果
bin/hdfs dfs -cat /user/atguigu/output/*
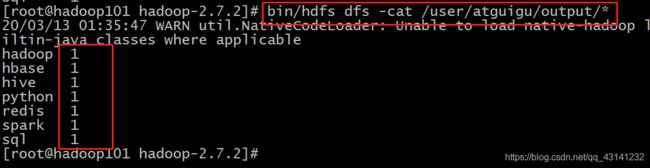
如有不对,欢迎指出纠正,谢谢