自然语言处理(NLP):24Bert+Faiss快速搭建智能客服系统
本文主要同大家分享NLP-智能客服系统解决方案,同大家学习交流
作者:走在前方
博客:https://wenjie.blog.csdn.net/
专注于文本分类、关键词抽取、文本摘要、FAQ 问答系统、对话系统语义理解 NLU、知识图谱等研究和实践。结合工业界具体案例和学术界最新研究成果实现 NLP 技术场景落地。
本文分享主题:Faiss和bert提供的模型实现了一个中文问答系统。旨在提供一个用Faiss结合各种AI模型实现语义相似度匹配的解决方案。 一般两种处理方案
- 业务系统定制
- 平台方式搭建通用的智能客服
针对智能客服-检索式问答系统,一般处理流程
-
问答对数据集的清洗
-
Embedding
-
模型训练
-
计算文本相似度
-
在问答库中选出与输入问题相似度最高的问题
-
返回相似度最高的问题所对应的答案
根据搭建智能客服难以程序,我们一般情况流程
- 基于ES的智能问题系统
(通过关键词匹配获取答案,类似电商、新闻搜索领域关键词召回)
- 基于TF-IDF方式
(计算每个单词的tfidf数值,分词后换算句子表示。 TF-IDF 方式也在用在关键词提取)
- 基于Doc2Vec 模型(考虑词和段,相比于word2vec来说有了段落信息)
- 通过深度学习语言模型bert 提取向量,然后计算相似度
方案可以扩展到的业务需求,更多分享关注博客
- 智能客服领域语义匹配
(对话系统检索式智能问答系统,答案在知识库中且返回唯一的数据记录)
-
以图搜索(resnet 图片想向量化表示)
-
新闻领域文本相似推荐(相似新闻推荐等)
-
基于文本语义匹配检索系统(文本相似性rank )
本文分享主要核心要点
-
bert 文本向量化
- bert-as-serving 服务搭建
- tensorflow 安装(ubuntu和windows下)
-
索引库构建
- faiss 产品手册介绍
- faiss 索引库搭建
-
问题-答案库构建
-
搭建数据库(mysql、mongodb、postgresql等)
-
基于语义匹配检索(query-> 向量化 -> 索引库快速检索)
针对这类问题,重点是把图片、文本等通过某种方式进行向量化表示(word2vec、doc2vec、elmo、bert等),然后把这种特征向量进行索引(faiss/Milus) ,最终实现在线服务系统的检索,然后再通过一定的规则进行过滤,获取最终的数据内容。
数据准备
针对智能客服系统,我们的数据集主要包括三个方面的内容
data/question.txt 是导入的问题集所在的路径
data/answer.txt 是导入的答案集所在的路径
data/id.txt 对应的数据唯一标识
数据样例说明(每行都一一对应的关系
data/question.txt
为什么伤口能自动愈合?
为什么儿童的心脏比成人跳得快?
data/answer.txt
皮肤一被划破或擦伤,身体就会立刻加以修补。
人的年龄越小,心脏跳动得越快。如:婴儿每分钟跳180次,
data/id.txt
100001
100002
针对不同的业务系统,我们只需要提供这种数据格式,通过本文的模板就可以快速搭建一个demo了,祝大家学习愉快。
如果想要测试更多的数据集,从github上查找或者爬虫进行验证
文本向量服务(bert-as-service)
使用bert as service 服务
环境准备
Python >= 3.5
Tensorflow >= 1.10 ( one-point-ten )
ubuntu系统-gpu下载离线安装文件并pip安装
tensorboard-1.15.0-py3-none-any.whl
tensorflow_estimator-1.15.1-py2.py3-none-any.whl
tensorflow_gpu-1.15.3-cp37-cp37m-manylinux2010_x86_64.whl
window 系统cpu安装
pip install tensorflow==1.15.0
验证是否安装
import tensorflow as tf
input1 = tf.placeholder(tf.float32)
input2 = tf.placeholder(tf.float32)
output = input1 * input2
with tf.Session() as sess:
r = sess.run([output], feed_dict={input1: [7.], input2: [8.]})
print(r.__getitem__(0)[0])
上述测试的结果56.0,我们测试成功。
bert-as-service 安装
- 参考github 提供的代码
git clone https://github.com/hanxiao/bert-as-service.git
- 安装server和client
pip install bert-serving-server # server
pip install bert-serving-client # client, independent of bert-serving-server
- 下载pretrained BERT models
Chinese Simplified and Traditional, 12-layer, 768-hidden, 12-heads, 110M parameters
https://storage.googleapis.com/bert_models/2018_11_03/chinese_L-12_H-768_A-12.zip
解压模型:
chinese_L-12_H-768_A-12
├── bert_config.json
├── bert_model.ckpt.data-00000-of-00001
├── bert_model.ckpt.index
├── bert_model.ckpt.meta
└── vocab.txt
bert_config.json: bert 模型配置参数
vocab.txt: 字典
bert_model: 预训练的模型
- 启动bert-service
bert-serving-start -model_dir chinese_L-12_H-768_A-12 \
-num_worker=4 \
-max_seq_len 42
workers = 4 表示同时并发处理请求数
model_dir 预训练的模型
max_seq_len 业务分析句子的长度
- 测试文本-> 向量表示结果
on another CPU machine
from bert_serving.client import BertClient
bc = BertClient(ip=‘xx.xx.xx.xx’) # ip address of the GPU machine
bc.encode([‘First do it’, ‘then do it right’, ‘then do it better’])
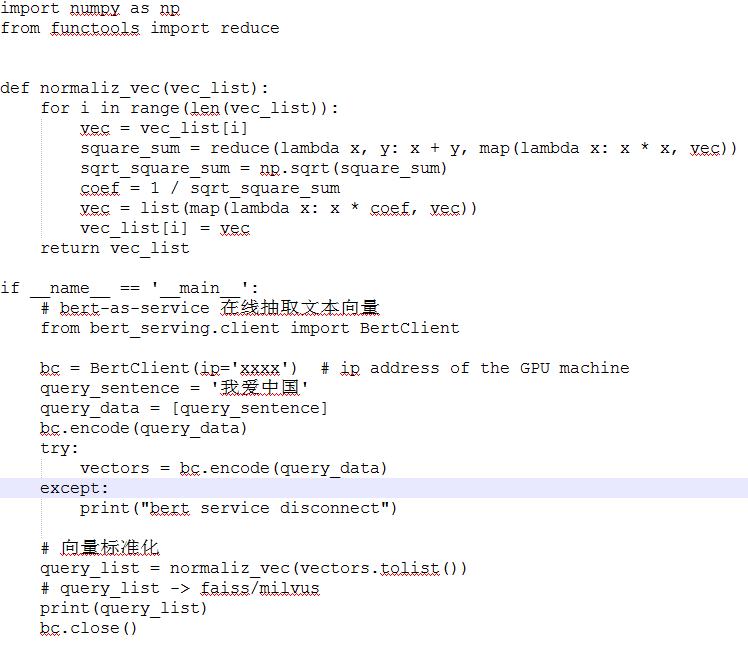
索引库(faiss)+知识库(db)搭建
环境准备
索引库文件存储: faiss
知识库:可以存储mongo/PostgreSQL/mysql 根据数据量进行选择
faiss 产品学习手册
构建索引+问题-答案库创建
第一步:我们创建问题-答案库(可以选择mysql、mongodb、PostgreSQL 等。。。)
本文给大家分享的内容,数据存储在mysql上。
create database faiss_qa;
use faiss_qa;
CREATE TABLE `answer_info` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`answer` text CHARACTER SET utf8,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=latin1;
CREATE INDEX answer_info_index_id on answer_info(id);
第二步:执行数据生成程序
python main.py \
–collection faiss_qa \
–id …/data/id.txt \
–question …/data/question.txt \
–answer …/data/answer.txt \
–load
注:
data/question.txt 是导入的问题集所在的路径
data/answer.txt 是导入的答案集所在的路径
data/id.txt 对应的数据唯一标识
文本相似度检索
命令行模式-离线测试
这里同一个意思不同的表达方式,我们查看下效果如何。重点还是因为bert抽取向量效果很好。
- 案例1
$ python main.py \
–collection faiss_qa \
–sentence 人有多少种血型 \
–search
给出的答案:
No.100021 人的血型一共分为四种类型,包括:A型.B型、AB型以及O型。当病人输血时,所输入的血型一定要和病人的血型相符合否则会有生命危险。
- 案例2
$ python main.py \
–collection faiss_qa \
–sentence 人的血型有多少种 \
–search
给出的答案:
No.100021 人的血型一共分为四种类型,包括:A型.B型、AB型以及O型。当病人输血时,所输入的血型一定要和病人的血型相符合否则会有生命危险。
API接口模式-在线服务
启动在线服务,然后我们通过curl进行测试效果
- 案例1
$ curl -H “Content-Type:application/json” \
-X POST --data ‘{“query”: “人有多少种血型”}’ \
http://localhost:5000/api/v1/search
返回的结果
{
“errno”: 200,
“data”: [
{
“_id”: 100021,
“text”: “人的血型一共分为四种类型,包括:A型.B型、AB型以及O型。当病人输血时,所输入的血型一定要和病人的血型相符合否则会有生命危险。”
}
]
}
- 案例2(同案例1,使用另外一种表达方式,发现仍能获取期望的结果)
$ curl -H “Content-Type:application/json” \
-X POST --data ‘{“query”: “人的血型有多少种”}’ \
http://localhost:5000/api/v1/search| jq
返回的结果
{
“errno”: 200,
“data”: [
{
“_id”: 100021,
“text”: “人的血型一共分为四种类型,包括:A型.B型、AB型以及O型。当病人输血时,所输入的血型一定要和病人的血型相符合否则会有生命危险。”
}
]
}
- 案例3
curl -H “Content-Type:application/json”
-X POST --data ‘{“query”: “心脏跳一次用多长时间?”}’ \
http://localhost:5000/api/v1/search|jq
{
“errno”: 200,
“data”: [
{
“_id”: 100003,
“text”: “心脏的每一次跳动大约用0.8秒,其中心房收缩用0.1秒,而舒张却用0.7秒;心室的收缩用0.3秒,舒张用0.5秒。”
}
]
}
- 案例4(问题-答案库未找到匹配结果情况)
$ curl -H “Content-Type:application/json” \
-X POST --data ‘{“query”: “心”}’ \
http://localhost:5000/api/v1/search
返回结果:
{
“errno”: 200,
“data”: [
{
“_id”: null,
“text”: “对不起,我暂时无法为您解答该问题”
}
]
}
优化方案
bert 特征向量提取:bert-base 模型,可以考虑更小的模型尝试特征提取
https://github.com/brightmart/albert_zh
https://www.sohu.com/a/347721677_473283
https://www.ctolib.com/liushaoweihua-bert_encode_server.html