R做时间序列(ARIMA)的案例
|
Arima预测模型(R语言)
ARIMA(p,d,q)
模型全称为
差分自回归移动平均模型(Autoregressive Integrated Moving Average Model,简记ARIMA),
AR是自回归, p为自回归项; MA为移动平均,q为移动平均项数,d为时间序列成为平稳时所做的差分次数。
所谓ARIMA模型,是指将非平稳时间序列转化为平稳时间序列,然后将因变量仅对它的滞后值以及随机误差项的现值和滞后值进行回归所建立的模型。ARIMA模型根据原序列是否平稳以及回归中所含部分的不同,包括移动平均过程(MA)、自回归过程(AR)、自回归移动平均过程(ARMA)以及ARIMA过程。
下面我们选取了一些具有周期性(7天)的测试数据,通过ARIMA模型做一个简单的预测。
source<- c(10930,10318,10595,10972,7706,6756,9092,10551,9722,10913,11151,8186,6422,
测试数据的时间序列图,如下:
data<-xts(data,seq(as.POSIXct("2014-01-01"),len=length(data),by="day")) plot(data)

通过以下代码:
data_diff1<-diff(data,differences=1)

可以看出一次差分后的时间序列在均值和方差上看起来像是平稳的,与二次差分的图形相差不大,随着时间推移,时间序列大致保持不变,因此设置差分项d=1。
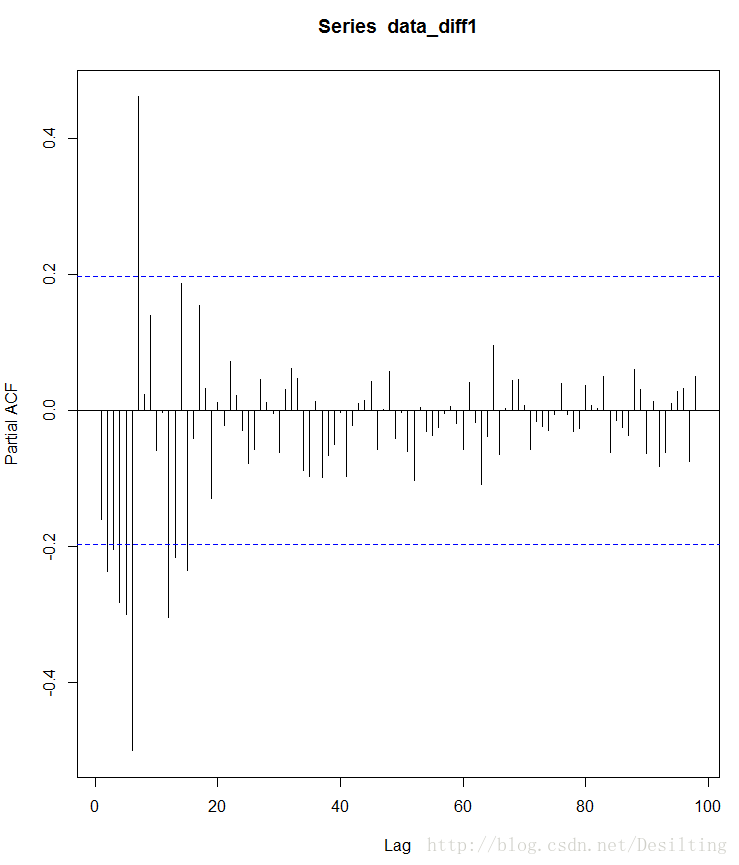
接下来需要选择合适的ARIMA模型,即确定ARIMA(p,d,q)中合适的 p、q 值,我们通过R中的“acf()”和“pacf”函数来做判断。
1、查看自相关图
acf <- acf(data_diff1,lag.max=100,plot=FALSE)

2、查看偏自相关图
pacf <- pacf(data_diff1,lag.max=100,plot=FALSE)
ARMA(p,q)模型的ACF与PACF理论模式
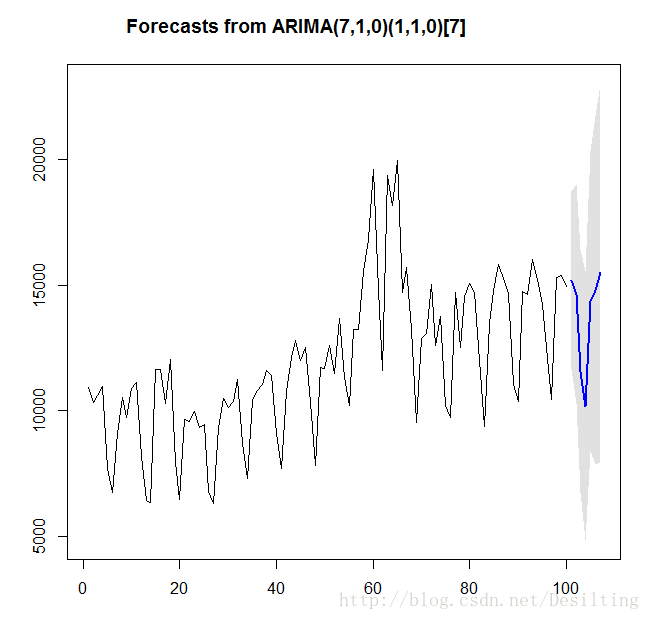
data.fit <- arima(data,order=c(7,1,0), seasonal=list(order=c(1,1,0), period=7))
预测后一周的值:
forecast <- forecast.Arima(data.fit,h=7,level=c(99.5))
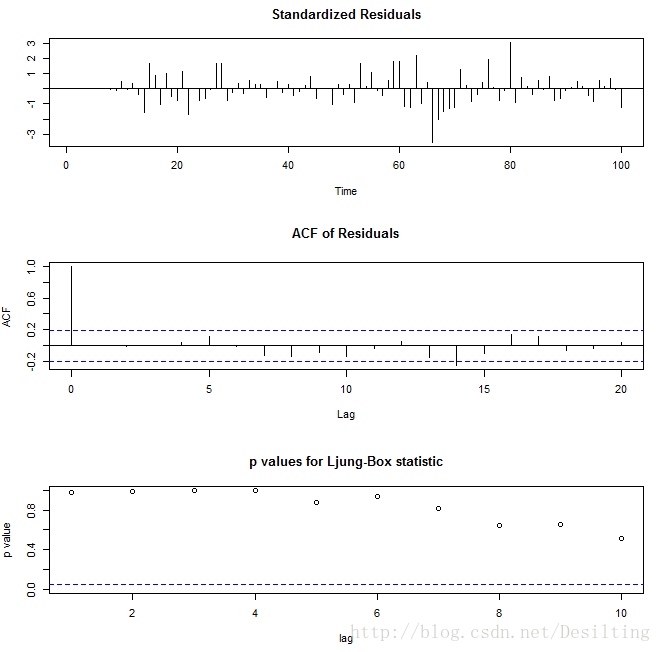
tsdiag检验——
tsdiag(data.fit)
Acf检验说明:
残差没有明显的自相关性
Ljung-Box测试显示:
所有的P-value>0.5, 说明残差为白噪声
*最近正在看这一块的东西,有些地方还没弄太明白,尤其是公式原理,若有不正确的地方,欢迎指正。 |