mongodb副本集中其中一个节点宕机无法重启的问题
2-8日我还在家中的时候,被告知mongodb副本集中其中一个从节点因未知原因宕机,然后暂时负责代管的同事无论如何就是启动不起来。
当时mongodb的日志信息是这样的:
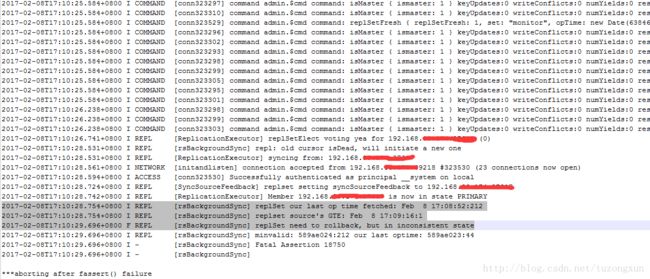
实际上这里这么长一串最重要的信息应该是在后边几行:
2017-02-08T17:10:28.754+0800 I REPL [rsBackgroundSync] replSet our last op time fetched: Feb 8 17:08:52:212
2017-02-08T17:10:28.754+0800 I REPL [rsBackgroundSync] replset source's GTE: Feb 8 17:09:16:1
2017-02-08T17:10:29.696+0800 F REPL [rsBackgroundSync] replSet need to rollback, but in inconsistent state据我的理解,这里大概的意思是指明了副本集节点最后的正常时间,说现在启动这个节点需要回滚,但是回滚的时候存在矛盾冲突,然后无法正常启动。
当时我正有事忙着,电脑又不在手边上,仅凭这几行提示我也无法确定究竟是什么原因,又想到一台从节点暂时宕机对整个系统没有太大影响,于是就让他先看了一下机器内存,结果发现内存实在低的不像话,才三四十兆。
但是这台机只有一个程序在运行,就是mongodb数据库,数据库没运行的情况下内存这样低绝对有问题。
于是我初步推断大概是内存的问题导致数据缺失,而后同步出现矛盾冲突,便提出了重启机器的要求,由于是生产环境要走一系列流程,因此直到昨晚机器才完成重启。
机器重启后,内存果然恢复正常,但是重启数据库的时候还是一样的问题。
既如此,那就只能翻出2-8当天出问题时的日志再看看了,于是发现之前的日志上方还有有这样一些内容:
2017-02-08T17:09:26.471+0800 I NETWORK [SyncSourceFeedback] Socket recv() timeout 192.168.*.*:27017
2017-02-08T17:09:26.471+0800 I NETWORK [SyncSourceFeedback] SocketException: remote: 192.168.*.*:27017 error: 9001 socket exception [RECV_TIMEOUT] server [192.168.*.*:27017]
2017-02-08T17:09:26.471+0800 I NETWORK [SyncSourceFeedback] DBClientCursor::init call() failed
2017-02-08T17:09:26.471+0800 I REPL [SyncSourceFeedback] SyncSourceFeedback error sending update: DBClientBase::findN: transport error: 192.168.*.*:27017 ns: admin.$cmd query: { replSetUpdatePosition: 1, optimes: [ { _id: ObjectId('5850ee6ae9405575765fc1d0'), optime: Timestamp 1486544809000|72, memberId: 0, cfgver: 5, config: { _id: 0, host: "192.168.*.*:27017", arbiterOnly: false, buildIndexes: true, hidden: false, priority: 5.0, tags: {}, slaveDelay: 0, votes: 1 } }, { _id: ObjectId('5850eebcd4c62a9b9fbba274'), optime: Timestamp 1486544869000|114, memberId: 1, cfgver: 5, config: { _id: 1, host: "192.168.*.*:27017", arbiterOnly: false, buildIndexes: true, hidden: false, priority: 1.0, tags: {}, slaveDelay: 0, votes: 1 } }, { _id: ObjectId('5850eeb2a7e579698bafa475'), optime: Timestamp 1486544867000|332, memberId: 2, cfgver: 5, config: { _id: 2, host: "192.168.*.*:27017", arbiterOnly: false, buildIndexes: true, hidden: false, priority: 1.0, tags: {}, slaveDelay: 0, votes: 1 } } ] }
2017-02-08T17:09:27.098+0800 W NETWORK [ReplExecNetThread-2534] Failed to connect to 192.168.*.*:27017 after 5000 milliseconds, giving up.
2017-02-08T17:09:27.098+0800 I REPL [ReplicationExecutor] Error in heartbeat request to 192.168.*.*:27017; Location18915 Failed attempt to connect to 192.168.*.*:27017; couldn't connect to server 192.168.*.*:27017 (192.168.*.*), connection attempt failed
2017-02-08T17:09:31.455+0800 I REPL [ReplicationExecutor] could not find member to sync from
2017-02-08T17:09:32.097+0800 W NETWORK [ReplExecNetThread-2535] Failed to connect to 192.168.*.*:27017, reason: errno:115 Operation now in progress
2017-02-08T17:09:32.098+0800 I REPL [ReplicationExecutor] Error in heartbeat request to 192.168.*.*:27017; Location18915 Failed attempt to connect to 192.168.*.*:27017; couldn't connect to server 192.168.*.*:27017 (192.168.*.*), connection attempt failed
2017-02-08T17:09:39.098+0800 W NETWORK [ReplExecNetThread-2535] Failed to connect to 192.168.*.*:27017 after 5000 milliseconds, giving up.
2017-02-08T17:09:39.098+0800 I REPL [ReplicationExecutor] Error in heartbeat request to 192.168.*.*:27017; Location18915 Failed attempt to connect to 192.168.*.*:27017; couldn't connect to server 192.168.*.*:27017 (192.168.*.*), connection attempt failed
2017-02-08T17:09:42.099+0800 W NETWORK [ReplExecNetThread-2534] Failed to connect to 192.168.*.*:27017, reason: errno:113 No route to host一番查询后,有说是副本集选举问题的,有说是网络防火墙问题的,但并没有找到解决办法,于是只好自己想了一个解决办法,强制把宕机节点删除掉再新建一个全新的数据库作为节点加进来。
在这个过程中我有所犹豫,因为我并不确定在加入了用户验证和使用了keyfile文件的时候能否成功解决我的问题,不知道是否会出现用户验证不通过而导致无法加入节点的问题。
不过好在,实在想不出更好办法的情况下,我用rs.remove删除宕机节点,再用rs.add添加新节点后,一切数据都正常同步了,包括之前的用户名密码和系统所需的主要数据。
而且原本以为一千多万的数据可能需要耗费很久时间同步,结果并没有用多久这个节点就从startup2变成了secondary。
本以为会有一番周折,结果有些出乎意料的解决了,但是并没有找到问题出现的根本原因,因此详细记录这一过程,以便其他人查看的同时,也算是记录下一个问题,寻求能想到相关原因的朋友给予解答。