心脏病预测模型(基于Python的数据挖据)
作者:Abdullah Alrhmoun
该项目的目标是建立一个模型,该模型可以根据描述疾病的特征组合预测心脏病发生的概率。为了实现这一目标,作者使用了瑞士Cleveland Clinic Foundation收集的数据集。该项目中使用的数据集包含针对心脏病的14个特征。数据集显示不同水平的心脏病存在从1到4和0没有疾病。我们有303行人数据,13个连续观察不同的症状。此项目研究了不同的经典机器学习模型,以及它们在疾病风险中的发现。
导入依赖库
#导入依赖库
import pandas as pnd
import numpy as np
from sklearn import preprocessing
from sklearn import neighbors, datasets
from sklearn import cross_validation
from sklearn.linear_model import SGDClassifier
from sklearn import svm
import operator
from sklearn.cross_validation import KFold
import itertools
import numpy as np
import matplotlib.pyplot as plt
from sklearn import metrics
from sklearn.metrics import confusion_matrix
from sklearn import tree
import seaborn as sns
from IPython.display import Image
%matplotlib inline载入数据
# 添加列名
header_row = ['age','sex','chest_pain','blood pressure','serum_cholestoral','fasting_blood_sugar',\
'electrocardiographic','max_heart_rate','induced_angina','ST_depression','slope','vessels','thal','diagnosis']
# 载入数据
heart = pnd.read_csv('processed.cleveland.data.csv', names=header_row)
heart[:5]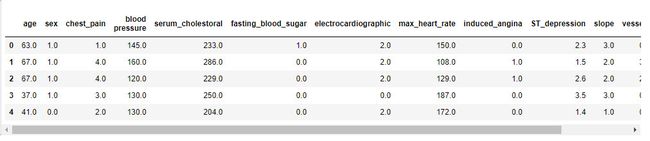
#查看数据维度
heart.shape(303, 14) #303行人的数据,13个连续观察不同症状。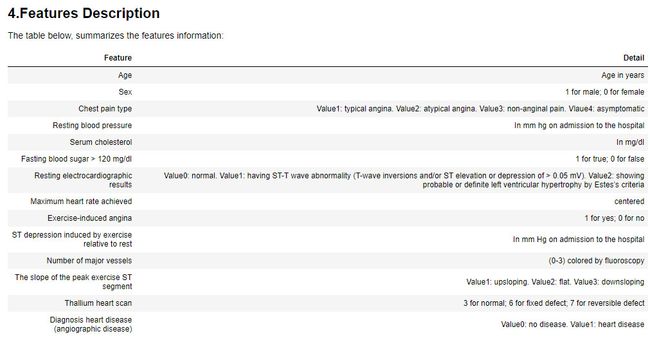
数据探索
# 计算统计值
heart.describe()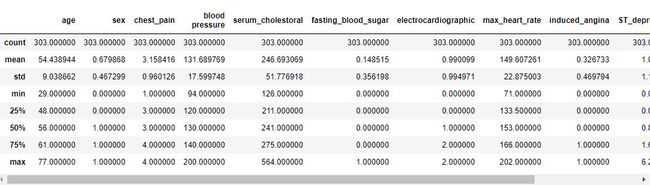
计算某个特征的人数
names_descr = dict()
categorical_columns = ["sex", "chest_pain", "fasting_blood_sugar", "electrocardiographic", "induced_angina", "slope", "vessels", \
"thal", "diagnosis"]
for c in categorical_columns:
print (heart.groupby([c])["age"].count())使用简单的均值插补方法预处理数据,将缺失的数据更改为平均值
for c in heart.columns[:-1]:
heart[c] = heart[c].apply(lambda x: heart[heart[c]!='?'][c].astype(float).mean() if x == "?" else x)
heart[c] = heart[c].astype(float) 心脏病类型发现
set(heart.loc[:, "diagnosis"].values)(0 :没有疾病;1,2,3,4 代表不同疾病类型)
计算1,2,3,4 levels 之间的相似性
vecs_1 = heart[heart["diagnosis"] == 1 ].median().values[:-2]
vecs_2 = heart[heart["diagnosis"] == 2 ].median().values[:-2]
vecs_3 = heart[heart["diagnosis"] == 3 ].median().values[:-2]
vecs_4 = heart[heart["diagnosis"] == 4 ].median().values[:-2]print ("Similarity between type 1 and type 2 is ", np.linalg.norm(vecs_1-vecs_2))
print ("Similarity between type 1 and type 3 is ", np.linalg.norm(vecs_1-vecs_3))
print ("Similarity between type 1 and type 4 is ", np.linalg.norm(vecs_1-vecs_4))
print ("Similarity between type 2 and type 3 is ", np.linalg.norm(vecs_2-vecs_3))
print ("Similarity between type 2 and type 4 is ", np.linalg.norm(vecs_2-vecs_4))
print ("Similarity between type 3 and type 4 is ", np.linalg.norm(vecs_3-vecs_4))sim = {"(1,2)": np.linalg.norm(vecs_1-vecs_2), \
"(1,3)": np.linalg.norm(vecs_1-vecs_3),\
"(1,4)": np.linalg.norm(vecs_1-vecs_4),\
"(2,3)": np.linalg.norm(vecs_2-vecs_3),\
"(2,4)": np.linalg.norm(vecs_2-vecs_4),\
"(3,4)": np.linalg.norm(vecs_3-vecs_4)
}# 根据相近值排序
sorted_sim = sorted(sim.items(), key=operator.itemgetter(1))
sorted_sim可以分别使用每个特征的值来比较心脏病的类型
heart_d = heart[heart["diagnosis"] >= 1 ]
heart_d[:5]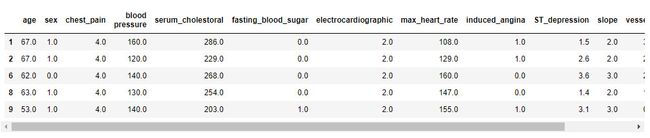
数据预处理
# if "diagnosis" == 0, 没有疾病
# if "diagnosis" >= 1, 有疾病
heart.loc[:, "diag_int"] = heart.loc[:, "diagnosis"].apply(lambda x: 1 if x >= 1 else 0)#数据标准化
preprocessing.Normalizer().fit_transform(heart)#划分数据集
heart_train, heart_test, goal_train, goal_test = cross_validation.train_test_split(heart.loc[:,'age':'thal'], \
heart.loc[:,'diag_int'], test_size=0.33, random_state=0) #计算相关系数
corr = heart.corr()
heart.corr()
#绘制热图
cmap = sns.diverging_palette(250, 10, n=3, as_cmap=True)
def magnify():
return [dict(selector="th",
props=[("font-size", "7pt")]),
dict(selector="td",
props=[('padding', "0em 0em")]),
dict(selector="th:hover",
props=[("font-size", "12pt")]),
dict(selector="tr:hover td:hover",
props=[('max-width', '200px'),
('font-size', '12pt')])
]
corr.style.background_gradient(cmap, axis=1)\
.set_properties(**{'max-width': '80px', 'font-size': '10pt'})\
.set_caption("Hover to magify")\
.set_precision(2)\
.set_table_styles(magnify())
探索可视化
#年龄与血压关系
import matplotlib.pyplot as plt
%matplotlib inline
plt.xlabel("age")
plt.ylabel("blood pressure")
# define title
plt.title("Relationship between age and blood pressure")
# plot
plt.scatter(heart['age'], heart['blood pressure'])
plt.show()
建立训练模型并评估LSS参数
# add parameters for grid search
loss = ["hinge", "log"]
penalty = ["l1", "l2"]
alpha = [0.1, 0.05, 0.01]
n_iter = [500, 1000]
# build the models with different parameters and select the best combination for the highest Accuracy
best_score = 0
best_param = (0,0,0,0)
for l in loss:
for p in penalty:
for a in alpha:
for n in n_iter:
print("Parameters for model", (l,p,a,n))
lss = SGDClassifier(loss=l, penalty=p, alpha=a, n_iter=n)
lss.fit(heart_train, goal_train)
print("Linear regression SGD Cross-Validation scores:")
scores = cross_validation.cross_val_score(lss, heart.loc[:,'age':'thal'], heart.loc[:,'diag_int'], cv=10)
print (scores)
print("Mean Linear regression SGD Cross-Validation score = ", np.mean(scores))
if np.mean(scores) > best_score:
best_score = np.mean(scores)
best_param = (l,p,a,n)
print("The best parameters for model are ", best_param)
print("The Cross-Validation score = ", best_score)lss_best = SGDClassifier(alpha=0.05, fit_intercept=True, loss='log', n_iter=1000,
penalty='l1')
lss_best.fit(heart_train, goal_train)
print("Linear regression SGD Test score:")
print(lss_best.score(heart_test, goal_test)) 模型验证
# Compute confusion matrix
cnf_matrix = confusion_matrix(goal_test, lss_best.predict(heart_test))
np.set_printoptions(precision=2)
# Plot non-normalized confusion matrix
plt.figure()
plot_confusion_matrix(cnf_matrix, classes=["Heart disease", "No heart disease"],
title='Confusion matrix, without normalization')
plt.show()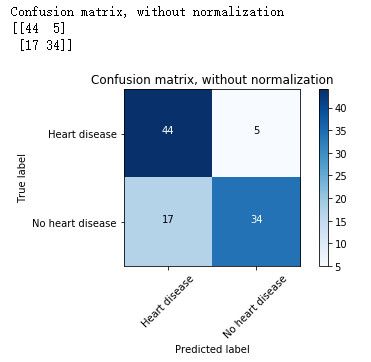
参考:
https://github.com/Sonali1197/Heart-disease-prediction-model
 DrugAI
DrugAI