推荐系列(四):矩阵分解|Matrix Factorization
矩阵分解|Matrix Factorization
在上节讲过,用户和item之间的关系可以用一个关系矩阵表示,而矩阵分解式一个简单的嵌入模型。假设一个用户反馈矩阵: A ∈ R m × n A \in R^{m \times n} A∈Rm×n,其中m表示用户的数量,n表示item的数量
- 用户嵌入矩阵 U ∈ R m × d U \in \mathbb R^{m \times d} U∈Rm×d
- 商品嵌入矩阵 V ∈ R n × d V \in \mathbb R^{n \times d} V∈Rn×d
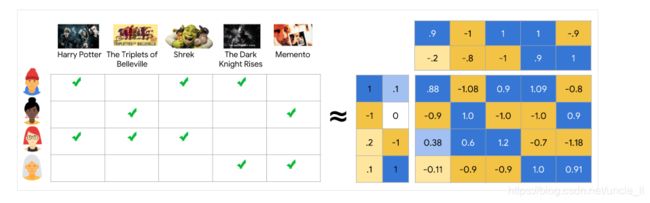
嵌入矩阵可以看作是 U V T ( i , j ) U . V T ⟨ U i , V j ⟩ i j A i , j U V^T(i, j)U . V^T\langle U_i, V_j\rangle i j A_{i, j} UVT(i,j)U.VT⟨Ui,Vj⟩ijAi,j的点积
矩阵分解一般是用近似的方法表示,而不是使用整个矩阵表示,整个矩阵的元素个数是O(nm)个元素,而嵌入矩阵的元素个数是O((m+n)d),其中d的维数一般远小于m和n的维度。因此,嵌入矩阵能够表示数据的潜在结构,这表明观察到的结果接近于低维子空间,类似于降维。在上述例子中,由于维度太低,以至于这个优点被忽略不计。然而,在现实的推荐系统中,使用矩阵分解的效果可以比学习完整矩阵会更加高效。
选择目标函数
一个常用的目标函数是欧式距离,这里以此为例。为此,最小化所有观察到的item对的误差平方和:
min U ∈ R m × d , V ∈ R n × d ∑ ( i , j ) ∈ obs ( A i j − ⟨ U i , V j ⟩ ) 2 \min_{U \in \mathbb R^{m \times d},\ V \in \mathbb R^{n \times d}} \sum_{(i, j) \in \text{obs}} (A_{ij} - \langle U_{i}, V_{j} \rangle)^2 U∈Rm×d, V∈Rn×dmin(i,j)∈obs∑(Aij−⟨Ui,Vj⟩)2
在上述目标函数中,只对观察到的item对(i,j)求和,即用户反馈矩阵中的非零值。然而,只对观察到值进行处理并不是一个好的想法 ,因为矩阵中的所有元素都会对模型产生影响,如果只用观察到的值进行仿真模拟,则该模型无法得出有效的推荐且泛化能力差。一句话总结:在推荐系统中,正样本数据集和负样本数据集都是有用的。
因此会有另外的求和方法,如下所示:
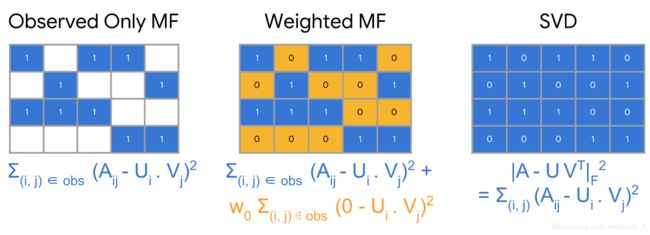
将为观察到的item对的值设置为0, 并对矩阵中所有的值求和,因此求和公式从之前的只对观察到的item对求和之外,还需要对未观察到的item对,求和公式如下所示:
min U ∈ R m × d , V ∈ R n × d ∥ A − U V T ∥ F 2 \min_{U \in \mathbb R^{m \times d},\ V \in \mathbb R^{n \times d}} \|A - U V^T\|_F^2 U∈Rm×d, V∈Rn×dmin∥A−UVT∥F2
上述问题可以使用奇异值分解(Singular Value Decomposition , SVD)处理,然而SVD不是一个很好的解决方法,这是由于其在实际应用中,矩阵A可能是非常稀疏的,比如在视频或新闻APP中,热门的item可能被更多的用户浏览,导致矩阵很稀疏。稀疏矩阵会导致SVD的求解结果近似为0,导致泛化能力很差。
相反,加权矩阵分解 将目标分解为两个总和:
- 观察到的条目的总和;
- 未观察到的条目的总和;
min U ∈ R m × d , V ∈ R n × d ∑ ( i , j ) ∈ obs ( A i j − ⟨ U i , V j ⟩ ) 2 + w 0 ∑ ( i , j ) ̸ ∈ obs ( ⟨ U i , V j ⟩ ) 2 \min_{U \in \mathbb R^{m \times d},\ V \in \mathbb R^{n \times d}} \sum_{(i, j) \in \text{obs}} (A_{ij} - \langle U_{i}, V_{j} \rangle)^2 + w_0 \sum_{(i, j) \not \in \text{obs}} (\langle U_i, V_j\rangle)^2 U∈Rm×d, V∈Rn×dmin(i,j)∈obs∑(Aij−⟨Ui,Vj⟩)2+w0(i,j)̸∈obs∑(⟨Ui,Vj⟩)2
注意,在实际应用中,还需要仔细权衡观察到的item对。例如,热门item或频繁使用(例如,重度用户)可能会主导目标函数。因此,我们可以通过对训练样例进行加权重来考虑item频率来校正模型效果。换句话说,可以通过以下方式替换目标函数:
∑ ( i , j ) ∈ obs w i , j ( A i , j − ⟨ U i , V j ⟩ ) 2 + w 0 ∑ i , j ̸ ∈ obs ⟨ U i , V j ⟩ 2 \sum_{(i, j) \in \text{obs}} w_{i, j} (A_{i, j} - \langle U_i, V_j \rangle)^2 + w_0 \sum_{i, j \not \in \text{obs}} \langle U_i, V_j \rangle^2 (i,j)∈obs∑wi,j(Ai,j−⟨Ui,Vj⟩)2+w0i,j̸∈obs∑⟨Ui,Vj⟩2
最小化目标函数
最小化目标函数的常用算法包括:
- 随机梯度下降(SGD) 是使损失函数最小化的通用方法。
- 加权交替最小二乘(WALS)专门针对这一特定目标。
目标函数对于U和V都是二次的,其中,随机梯度下降算法是比较常用的模型训练方法,这里不做过多的介绍,而WALS通过随机初始化嵌入,然后交替进行以下工作:
- 固定U,对V求解
- 固定V, 对U求解
关于WALS的详细介绍可以看该图:

SGD vs. WALS
SGD和WALS各有自身的优点有缺点:
SGD
-
非常灵活 :可以使用其他损失函数
-
可以并行化
-
收敛较慢
-
更难处理未观察到的item
WALS
-
依赖于均方误差
-
可以并行化
-
收敛速度比SGD快
-
更容易处理未观察到的item