SparkStreaming入门(DStream ,Receiver,input DStream)
流计算简介
数据总体上分为静态数据和流数据。对静态数据和流数据的处理,对应着两种截然不同的计算模式:批量计算和实时计算。批量计算以“静态数据”为对象,可以在很充裕的时间内对海量数据进行批处理,计算得到有价值的信息。Hadoop就是很典型的批处理模型,有HDFS和HBase存放大量的静态数据,由MapReduce负责对海量数据执行批量计算。流数据必须采用实时计算,实时计算最重要的一个需求是能够实时得到计算结果,一般要求响应时间为秒级。现在,数据不仅格式复杂,而且数量量巨大,这给实时计算带来很大的挑战。因此,针对流数据的实时计算-流计算,应运而生。
流计算有个基本概念,即数据的价值随着时间的流逝而降低。因此,当事件出现时应该立刻进行处理,而不是缓存起来进行批量处理。为了及时处理流数据,需要一个低延迟、可扩展、高可靠的处理引擎。
流计算系统的需求特性:
• 高性能。处理大数据的基本要求,如每秒处理几十万条数据。
• 海量式。支持TB级甚至是PB级的数据规模。
• 实时性。必须保证一个较低的延迟时间,达到秒级别,甚至是毫秒级别。
• 分布式。支持大数据的基本架构,必须能够平滑扩展。
• 易用性。能够快速进行开发和部署。
• 可靠性。能可靠地处理流数据。
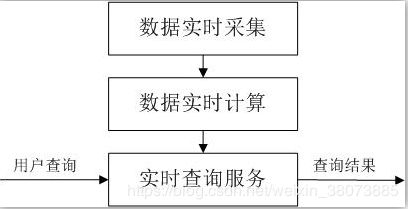
流计算处理过程包括数据实时采集、数据实时计算和实时查询服务。
数据实时采集:数据实时采集阶段通常采集多个数据源的海量数据,需要保证实时性、低延迟与稳定可靠。以日志数据为例,由于分布式集群的广泛应用,数据分散存储在不同的机器上,因此需要实时汇总来自不同机器上的日志数据。目前有许多互联网公司发布的开源分布式日志采集系统均可满足每秒数百MB的数据采集和传输需求,如Facebook的Scribe、LinkedIn的Kafka、淘宝的TimeTunnel,以及基于Hadoop的Chukwa和Flume等。
数据实时计算:流处理系统接收数据采集系统不断发来的实时数据,实时的进行分析计算,并反馈实时结果。
实时查询服务:经由流计算框架得出的结果可供用户及逆行试试查询、展示或储存。
SparkStreaming 简介
Spark Streaming时构建在Spark上的实时计算框架,他扩展了Spark处理大规模流式数据的能力。Spark Streaming可结合批处理和交互查询,适合一些需要对历史数据及逆行结合分析的应用场景。
Spark Streaming是Spark的核心组件之一,为Spark提供了可扩展、高吞吐、容错的流计算能力。下图为Spark Streaming支持的输入、输出数据源。

Spark Streaming的基本原理是将实时输入流以时间片(秒级)为单位进行拆分,然后经Spark引擎以类似批处理的方式处理每个时间片数据。
在Spark中,一个应用(Application)由一个任务控制节点(Diver)和若干个作业(Job)构成,一个作业由多个阶段(Stage)构成,一个阶段由多个任务(Task)组成。当执行一个应用时,任务控制节点会向集群管理器(Cluster Manager)申请资源,启动Executor,并向Executor发送应用程序代码和文件,然后在Executor上执行task。在Spark Streaming中,会有一个组件Receiver,作为一个长期运行的task泡在一个Executor上。每个Receiver都会负责一个input DStream(比如从文件中读取数据的文件流,例如上图中的kafka tcp)。Spark Streaming通过input data stream与外部数据源进行连接,读取相关数据。
下图为SparkStreaming的执行流程:

Spark Streaming内部的基本工作原理如下:接收实时输入数据流,然后将数据拆分成多个batch,比如每收集1秒的数据封装为一个batch,然后将每个batch交给Spark的计算引擎进行处理,最后会生产出一个结果数据流,其中的数据也是由一个一个的batch所组成的。
Spark Streaming最主要的抽象是DStream(Discretized Stream,离散化数据流),表示连续不断的数据流。在内部实现上,Spark Streaming的输入数据按照时间片(例如1秒)分成一段段的DStream,每一段数据转换为Spark的RDD,并且对DStream的操作都最终转换为相应的RDD操作。
DStream(离散流)
DStream可以通过输入数据源来创建,比如Kafka、Flume和Kinesis;也可以通过对其他DStream应用高阶函数来创建,比如map、reduce、join、window。DStream的内部,其实一系列持续不断产生的RDD。DStream中的每个RDD都包含了一个时间段内的数据。

对DStream应用的算子,比如map,其实在底层会被翻译为对DStream中每个RDD的操作。比如对一个DStream执行一个map操作,会产生一个新的DStream。但是,在底层,其实其原理为,对输入DStream中每个时间段的RDD,都应用一遍map操作,然后生成的新的RDD,即作为新的DStream中的那个时间段的一个RDD。底层的RDD的transformation操作,其实,还是由Spark Core的计算引擎来实现的。Spark Streaming对Spark Core进行了一层封装,隐藏了细节,然后对开发人员提供了方便易用的高层次的API。
wordcoun案例
这里我先举一个用SparkStreaming网络流实现单词计数的例子
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* Spark Streaming Socket套接字流 单词计数
* @author xjh 2018.09.28
*/
object StreamingNetwork {
def main(args: Array[String]): Unit = {
val sparkConf=new SparkConf().setAppName("WordCuntStreaming").setMaster("local[2]")
//设置为本地运行模式 2个线程 1个监听 宁一个处理数据
val ssc=new StreamingContext(sparkConf,Seconds(5)) //时间间隔为秒
val lines =ssc.socketTextStream("msiPC",9999)
// val lines =ssc.textFileStream("D:\\ideaCode\\spark_wordCount\\StreamingTestData")
val words=lines.flatMap(_.split(" "))
val wordCounts=words.map((_,1)).reduceByKey(_+_)
wordCounts.print()
ssc.start() //开始计算
ssc.awaitTermination() //等待计算结束
}
}
因为这是SparkStreaming的首个代码案例,南国在这里对代码做个详细 的讲解:
- sparkConf是配置Spark程序的相关配置
- ssc是创建一个StreamingContext对象,它是所有Spark Streaming功能的主要入口点。
- lines是ssc网络流的输入路径,这里指定的参数是网络终端的特定ip和端口号
- 后面的words wordCounts在之前的spark核心编程已经讲过 不再复述
- ssc.start()是开始计算
- ssc.awaitTermination() //等待计算结束
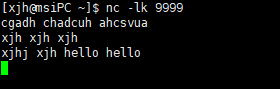
这段代码采取本地local模式运行,这里我们需要在目标终端打开特定的端口号,例如nc -lk 9999 本地代码运行成功后在控制台会连续不断的显示时间分片。因为是实时计算 我们需要在终端实时输入数据使得代码有输入源。
例如:下图所示
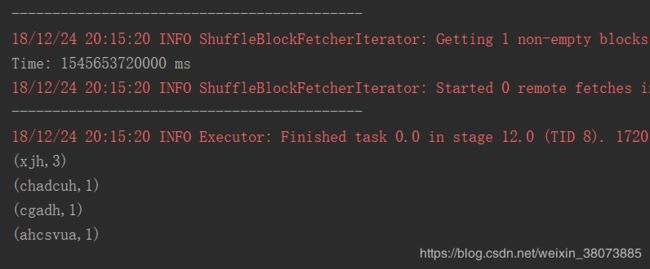
程序运行的结果:
在接收到输入数据时:

接收到数据后单词计数得到的结果:
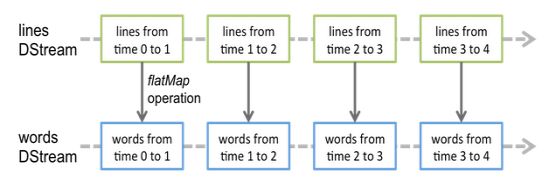
结合之前所讲DStream知识,单词计数中flatMap操作应用于lines中的每个RDD 以生成words的RDD 。如下图所示:
StreamingContext详解
有两种创建StreamingContext的方式:
// 方式1
val conf = new SparkConf().setAppName(appName).setMaster(master);
val ssc = new StreamingContext(conf, Seconds(1));
StreamingContext,还可以使用已有的SparkContext来创建
// 方式2
val sc = new SparkContext(conf)
val ssc = new StreamingContext(sc, Seconds(1));
appName:是用来在Spark UI上显示的应用名称。
master:是一个Spark、Mesos或者Yarn集群的URL,或者是local[*]。
batch interval:可以根据你的应用程序的延迟要求以及可用的集群资源情况来设置。
要初始化Spark Streaming程序,必须创建一个StreamingContext对象,它是所有Spark Streaming功能的主要入口点。
创建一个StreamingContext对象之后,我们还需完成以下几个操作:
- 1.通过创建输入DStream来定义输入源
- 2.通过对DStream应用转换操作和输出操作来定义流计算。
- 3.用streamingContext.start()来开始接收数据和处理流程。
- 4.通过streamingContext.awaitTermination()方法来等待处理结束(手动结束或因为错误而结束)。
- 5.可以通过streamingContext.stop()来手动结束流计算进程
需要注意的要点:
- 1、只要一个StreamingContext启动之后,就不能再往其中添加任何计算逻辑了。比如执行start()方法之后,还给某个DStream执行一个算子。
- 2、一个StreamingContext停止之后,是肯定不能够重启的。调用stop()之后,不能再调用start()
- 3、一个JVM同时只能有一个StreamingContext启动。在你的应用程序中,不能创建两个StreamingContext。
- 4、调用stop()方法时,会同时停止内部的SparkContext,如果不希望如此,还希望后面继续使用SparkContext创建其他类型的Context,比如SQLContext,那么就用stop(false)。
- 5、一个SparkContext可以创建多个StreamingContext,只要上一个先用stop(false)停止,再创建下一个即可。
Input DStreams and Receivers
中文翻译叫做输入离散流和接收器
每个输入DStream(文件流file stream除外)都与Receiver (Scala doc, Java doc)对象相关联,该对象从源接收数据并将其存储在Spark的内存中进行处理。
Spark Streaming提供两类内置流媒体源,还有第三种自定义数据源。
- 1.基本来源:StreamingContext API中直接提供的源。示例:文件系统和套接字连接。
- 2.高级资源:Kafka,Flume,Kinesis等资源可通过额外的实用程序类获得。这些需要链接额外的依赖关系,如 链接部分所述。
- 3、自定义数据源:我们可以自己定义数据源,来决定如何接受和存储数据。
请注意,如果要在流应用程序中并行接收多个数据流,可以创建多个输入DStream。这将创建多个接收器Receiver,这些接收器将同时接收多个数据流。但请注意,Spark worker / executor是一个长期运行的任务,因此它占用了分配给Spark Streaming应用程序的其中一个核心。因此,重要的是要记住,Spark Streaming应用程序需要分配足够的内核(或线程,如果在本地运行)来处理接收的数据,以及运行接收器。
要记住的要点:
在本地运行Spark Streaming程序时,请勿使用“local”或“local [1]”作为主URL。这两种方法都意味着只有一个线程将用于本地运行任务。如果您正在使用基于接收器的输入DStream(例如套接字,Kafka,Flume等),那么将使用单个线程来运行接收器,而不留下用于处理接收数据的线程。因此,在本地运行时,始终使用“local [ n ]”作为主URL,其中n >要运行的接收器数量。
将逻辑扩展到在集群上运行,分配给Spark Streaming应用程序的核心数必须大于接收器数。否则系统将接收数据,但无法处理数据。
Spark Streaming的基本输入源
1.文件流(File Streaming)
object StreamingToFile {
def main(args: Array[String]): Unit = {
val sparkConf=new SparkConf().setAppName("WordCuntStreaming").setMaster("local[2]")
//设置为本地运行模式 2个线程 1个监听 宁一个处理数据
val ssc=new StreamingContext(sparkConf,Seconds(15)) //时间间隔为秒
val lines =ssc.textFileStream("hdfs://msiPC:9000/spark/mycode/streaming")
// val lines =ssc.textFileStream("D:\\ideaCode\\spark_wordCount\\StreamingTestData")
val words=lines.flatMap(_.split(" "))
val wordCounts=words.map((_,1)).reduceByKey(_+_)
wordCounts.print()
ssc.start() //开始计算
ssc.awaitTermination() //等待计算结束
}
}
2.Socket套接字流
博客里第一个案例代码就是,这里不再累赘。
3.RDD队列流
object QueueStream {
def main(args: Array[String]): Unit = {
val sparkConf=new SparkConf().setAppName("TestRDDQueue").setMaster("local[2]")
val ssc=new StreamingContext(sparkConf,Seconds(10))
val rddQueue=new mutable.SynchronizedQueue[RDD[Int]] ()
val queueStream=ssc.queueStream(rddQueue)
val mappedStream=queueStream.map(r=>(r%10,1))
val reduceStream=mappedStream.reduceByKey(_+_)
reduceStream.print()
ssc.start()
//Spark Streaming开始循环监听
for(i<- 1 to 10){
rddQueue+=ssc.sparkContext.makeRDD(1 to 100,2)
Thread.sleep(1000)
}
ssc.stop()
}
}
博客参考:http://spark.apache.org/docs/2.3.0/streaming-programming-guide.html