SparkStreaming详解
Spark core的扩展,支持弹性,高吞吐,容错,实时数据流处理。多数据源,kafka、flume、TCP socket等 也可进行如map,reduce,join,window等高阶函数组成的复杂算法处理。处理结果写入文件系统、数据库、实时表盘中。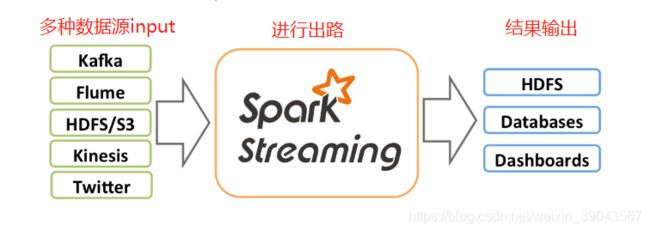
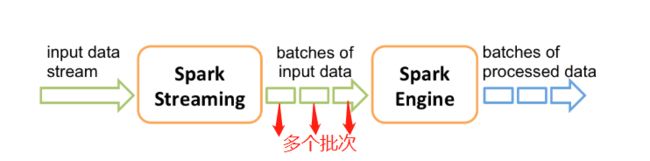
内部工作原理是把实时输入数据流切分成多个批数据,交给spark引擎处理并分批生成数据流。
提供高度抽象离散流(discretized stream)或者 DStream,代表这一个连续的数据流,可以通过数据源输入数据流创建,如kafka,flume等,也可以在其他dstream进行操作创建。(和RDD的创建方式很类似)一个DSream通过一系列的RDD表示。
简单示例:数据源获取通过监听TCP socket数据服务器收到文本数据,
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds(1))
val lines = ssc.socketTextStream("localhost", 9999)
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
wordCounts.print()
ssc.start() // 启动计算
ssc.awaitTermination() // 等待计算的终止前提 linux中执行$ nc -lk 9999 ,然后往里面写入数据,上面程序通过ssc.socketTextStream("localhost", 9999)即可接收到数据进行实时处理。
上面代码中lines是离散流DStream 表示将从数据服务器上收到的数据流。。lines中,每一条记录都是一行文本,然后切分成单词。
words.map(.....)是计算每一个批次中的每一个单词,进一步映射为(word,1)的DStream,
注意:这些lines被执行的时候 只有ssc建立启动时才会执行。
基本知识
maven依赖,初始化,StreamingContext(conf,batch interval)主入口。
Discretized Streams(DStreams)(离散化流)
代表了一个连续的数据流,无论是从源接收到的输入数据流,还是通过变换输入流所产生的处理过的数据流。在内部,一个离散流(DStream)被表示为一系列连续的 RDDs,RDD 是 Spark 的一个不可改变的,分布式的数据集的抽象.在一个 DStream 中的每个 RDD 包含来自一定的时间间隔的数据,如下图所示。

应用于 DStream 的任何操作转化为对于底层的 RDDs 的操作。例如,在先前的例子,转换一个行(lines)流成为单词(words)中,flatMap 操作被应用于在行离散流(lines DStream)中的每个 RDD 来生成单词离散流(words DStream)的 RDDs 。如下图所示。
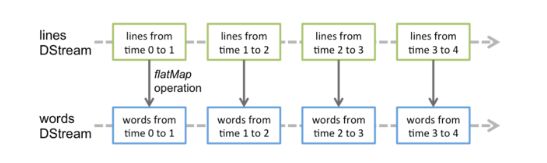
这些底层的 RDD 变换由 Spark 引擎(engine)计算。 DStream 操作隐藏了大多数这些细节并为了方便起见,提供给了开发者一个更高级别的 API 。
Input DStreams 和 Receivers
输入 DStreams 是代表输入数据是从流的源数据(streaming sources)接收到的流的 DStream 。在快速简单的例子中,行(lines)是一个输入 DStream ,因为它代表着从 netcat 服务器接收到的数据的流。每个输入离散流(input DStream)(除了文件流(file stream),在后面的章节进行讨论)都会与一个接收器(Scala doc,Java doc)对象联系,这个接收器对象从一个源头接收数据并且存储到 Sparks 的内存中用于处理。
Spark Streaming 提供了两种内置的流来源(streaming source)。
- Basic sources(基本来源): 在 StreamingContext API 中直接可用的源(source)。例如,文件系统(file systems),和 socket 连接(socket connections)。
- Advanced sources(高级来源): 就像 Kafka,Flume,Kinesis 之类的通过额外的实体类来使用的来源。这些都需要连接额外的依赖,就像在 连接 部分的讨论。
如果你想要在你的流处理程序中并行的接收多个数据流,你可以创建多个输入离散流(input DStreams)(在 性能调整 部分进一步讨论)。这将创建同时接收多个数据流的多个接收器(receivers)。但需要注意,一个 Spark 的 worker/executor 是一个长期运行的任务(task),因此它将占用分配给 Spark Streaming 的应用程序的所有核中的一个核(core)。因此,要记住,一个 Spark Streaming 应用需要分配足够的核(core)(或线程(threads),如果本地运行的话)来处理所接收的数据,以及来运行接收器(receiver(s))。
- 当在本地运行一个 Spark Streaming 程序的时候,不要使用 "local" 或者 "local[1]" 作为 master 的 URL 。这两种方法中的任何一个都意味着只有一个线程将用于运行本地任务。如果你正在使用一个基于接收器(receiver)的输入离散流(input DStream)(例如, sockets ,Kafka ,Flume 等),则该单独的线程将用于运行接收器(receiver),而没有留下任何的线程用于处理接收到的数据。因此,在本地运行时,总是用 "local[n]" 作为 master URL ,其中的 n > 运行接收器的数量
- 将逻辑扩展到集群上去运行,分配给 Spark Streaming 应用程序的内核(core)的内核数必须大于接收器(receiver)的数量。否则系统将接收数据,但是无法处理它。
Basic Source
上面已经通过TCP socket连接接收到的文本数据中创建了一个离散流(DStream)初次之外还有:
- 文件流,从文件中读,hdfs api兼容的文件系统,Spark Streaming监控dataDrectory下创建的文件。注意,数据格式要相同,文件必须在目录中通过原子移动或重命名他们到这个目录下创建。一旦移动,文件不可改,新追加到文件的数据将不会被读取。
- 简单文件可直接读取ssc.textStreamFile("path"),不需要接收器(receiver),不需分配内核。
高级来源
如kafka、flume,
DStream上的transformation
map() --flatMap()--fileter--repartition--union--count--reduce---等等
。。。