在R语言中构建动画图以分析我的健身数据
Introduction
所有这些健身追踪器,乐队,甚至我们的智能手机 - 它们都通过某些应用程序存储我们的健康数据,例如iOS上的Healthkit,Android上的Google健身等等。我们距离访问我们的健康数据还有几点距离 - 距离覆盖,步骤 - 燃烧,燃烧的卡路里,心率等
现在,我想分析一下健身水平的某些趋势。 我的应用程序并没有提供这种深度或分析水平。 所以我转向了我喜欢的一件事–R中的数据可视化。我可以轻松地从应用程序中提取这些数据并在R中执行各种分析,包括构建动画图。
这是对的 - 我使用我的健康数据并使用R中非常酷的动画图分析各种指标! 在本文中,我将展示如何使用几行R代码轻松制作这些图。
Table of Contents
我一步一步地写了这篇文章。 我的建议是按照下面提到的顺序:
从您的Fitness应用程序中提取健康数据
将XML数据文件导入R
预处理我们的健康数据
制定我们的假设
探索健康数据
在R中构建酷动画图
从您的健身应用程序中提取健康数据
我是iOS爱好者,所以我在设备上使用HealthKit应用程序来存储我的健康数据。 您可以按照以下步骤导出数据:
- 在iPhone上打开Health应用程序
- 点击’用户’
- 点击“导出健康数据”并通过电子邮件发送给自己(或选择最方便的选项)
瞧! 您将收到一个包含XML对象的zip文件。 下载并将其读入您的R控制台(在下一节中讨论)。
Android用户也可以提取他们的健康数据,但步骤会有所不同。 按照此链接中提到的步骤从Google健身应用中导出您的健康数据。
Importing the XML Data File into R
下载健康数据后,需要使用R友好格式导入它。 使用以下代码块读取XML文件:
注意:如果您尚未安装“XML”软件包,请首先从CRAN存储库安装。
install.packages("XML")
library(XML)
xml <- xmlParse("export.xml")
summary(xml)
#convert the XML object to data frame
df <- XML:::xmlAttrsToDataFrame(xml["//Record"])
Pre-processing our Health Data
在准备可视化和构建仪表板之前,我们必须转换一些变量并添加新功能。 这将有助于我们轻松地对直观图进行子集化和准备。 我们将使用日期列添加新列,例如年,月,周,小时等。
为此,我们需要R中的’lubridate’软件包。我个人喜欢这个软件包 - 当我们处理日期和时间数据时它非常有用。
install.packages("lubridate")
library(lubridate)
#make endDate in a date-time variable POSIXct using lubridate with Indian time zone
df$endDate <-ymd_hms(df$endDate,tz="UTC")
#new features
df$month<-format(df$endDate,"%m")
df$year<-format(df$endDate,"%Y")
df$date<-format(df$endDate,"%Y-%m-%d")
df$dayofweek <-wday(df$endDate, label=TRUE, abbr=FALSE)
df$hour <-format(df$endDate,"%H")
现在,让我们看一下清理和排序数据的结构:
str(df)
Output:
'data.frame': 422343 obs. of 14 variables:
$ type : Factor w/ 12 levels "HKQuantityTypeIdentifierActiveEnergyBurned",..: 9 4 7 7 7 7 7...
$ sourceName : Factor w/ 3 levels "Health","Mukeshâ\200\231s Apple Watch",..: 1 1 2 2 2 2 2 2 2...
$ sourceVersion: Factor w/ 22 levels "10.3.3","11.0.1",..: 1 1 17 17 17 17 17 17 17 17 ...
$ unit : Factor w/ 8 levels "cm","count","count/min",..: 1 5 3 3 3 3 3 3 3 3 ...
$ creationDate : Factor w/ 167201 levels "2017-08-18 19:33:16 +0530",..: 8 8 2450 2452 2464 2472 ...
$ startDate : Factor w/ 361820 levels "2017-08-18 18:30:27 +0530",..: 27 27 9642 9647 9655 9664...
$ endDate : POSIXct, format: "2017-08-19 10:34:01" "2017-08-19 10:34:01" "2018-05-01 08:24:12"...
$ value : num 163 79 83 82.1 83 ...
$ device : Factor w/ 102050 levels "<<HKDevice: 0x283c00dc0>, name:Apple Watch, manufacturer:Apple,...
$ month : chr "08" "08" "05" "05" ...
$ year : chr "2017" "2017" "2018" "2018" ...
$ date : chr "2017-08-19" "2017-08-19" "2018-05-01" "2018-05-01" ...
$ dayofweek : Ord.factor w/ 7 levels "Sunday"<"Monday"<..: 7 7 3 3 3 3 3 3 3 3 ...
$ hour : chr "10" "10" "08" "08" ...
我们开始分析时有很多观察结果。 但是,数据科学家在其他任何事情之前应该做的第一件事是什么? 是的,有必要先设定您的假设。
制定我们的假设
我们的目标是使用随时可用的健康应用数据来研究和回答以下指示:
- 平均步数,心率,覆盖距离,航班攀升
- 在步数和航班攀升方面,每年哪几个月都非常费劲?
- 比较研究步数,燃烧的卡路里,前几个月的距离
- 每周细分步数以检查一个月中的显性天数
- 有异常值吗?
- 工作日和周末的活动如何比较?
- 在一段时间后,受试者是否过渡到健康的生活方式?
还有其他你能想到的吗? 让我知道,我们可以将其添加到最终分析中!
Exploring the Health Data
让我们看一下Apple Watch,健身乐队和健康应用程序存储的观察结果:
table(df$type)
Output:
HKQuantityTypeIdentifierActiveEnergyBurned HKQuantityTypeIdentifierAppleExerciseTime
220673 6905
HKQuantityTypeIdentifierBasalEnergyBurned HKQuantityTypeIdentifierBodyMass
47469 1
HKQuantityTypeIdentifierDistanceWalkingRunning HKQuantityTypeIdentifierFlightsClimbed
48447 7822
HKQuantityTypeIdentifierHeartRate HKQuantityTypeIdentifierHeartRateVariabilitySDNN
45371 567
HKQuantityTypeIdentifierHeight HKQuantityTypeIdentifierRestingHeartRate
1 313
HKQuantityTypeIdentifierStepCount HKQuantityTypeIdentifierWalkingHeartRateAverage
44575 199
我们在每种类型下都有足够的观察。 我们将把重点缩小到下一节中的几个重要变量。
但首先,首先安装并导入一些重要的库,这些库将帮助我们对数据进行子集化并生成图:
install.packages("tidyverse")
install.packages("ggplot2")
library(tidyverse)
library(ggplot2)
准备我们的个性化健身追踪器仪表板
等待结束了! 让我们开始准备我们的仪表板,以创建直观和高级的可视化。 我们主要对以下指标感兴趣:
- 心率
- 步数
- 活跃的能量燃烧
- 爬楼梯
- 距离覆盖
我们一个接一个地把它们拿走。
心率
很容易成为我们数据集中最关键的指标。
让我们看看自从我开始使用这些健身追踪设备以来的心率。 我们将按日期,月份和年份对心率的平均值进行分组。 您可以使用以下代码块执行此操作:
heart_rate <- df %>%
filter(type == 'HKQuantityTypeIdentifierHeartRate') %>%
group_by(date,year,month) %>%
summarize(heart_rate=mean(value))
Output:
head(heart_rate)
# A tibble: 6 x 4
# Groups: date, year [6]
date year month heart_rate
<date> <chr> <chr> <dbl>
1 2018-05-01 2018 05 92.8
2 2018-05-02 2018 05 85.3
3 2018-05-03 2018 05 86.0
4 2018-05-04 2018 05 84.2
5 2018-05-05 2018 05 85.2
6 2018-05-06 2018 05 93.5
p1 <- ggplot(heart_rate,aes(x=date, y=heart_rate, group=year)) +
geom_line(aes(colour=year))+
ggtitle("Mean heartrate over the months")
在X轴上有太多日期看起来很随意。 因此,通过仅表示月份和年份来缩放X轴:
#convert the date format first
heart_rate$date <- as.Date(heart_rate$date,"%Y-%m-%d")
p1 <- p1+scale_x_date(date_labels = "%b/%Y")
Output:
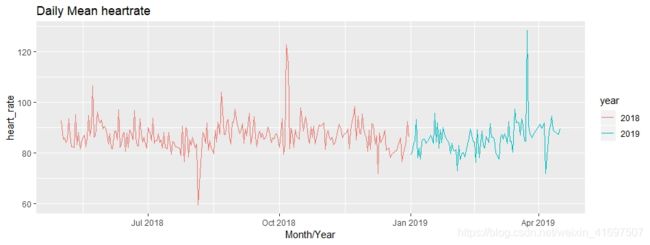
太好了! 这是一个好的开始。 不过,让我们把事情提升一个档次。 是的,我在谈论R中的动画情节!
你必须在社交媒体上遇到动画情节。 我当然不能在没有看到其中一两个的情况下滚动。 我们自己制作动画剧情怎么样? 我们需要’gganimate’包装:
install.packages("gganimate")
library(gganimate)
#animating the above plot
p1+transition_reveal(as.numeric(date))
Output

看起来很酷,对吗? 我们只使用一行代码获得了一个非常“好看”的情节。
现在,我们知道正常静息心率应介于60-100 bpm之间,正常活动心率应介于100-120 bpm之间。
曾经有一段时间心率超过这些界限。 可能是那些日子还有一些额外的活动。 数据点可能是异常值吗? 让我们看一下心率中值来计算出来:
heart_rate <- df %>%
filter(type == 'HKQuantityTypeIdentifierHeartRate') %>%
group_by(date,year,month) %>%
summarize(heart_rate=median(value))+
xlab("Month/Year")
heart_rate$date <- as.Date(heart_rate$date,"%Y-%m-%d")
plot <- ggplot(heart_rate,aes(x=date, y=heart_rate, group=year)) +
geom_line(aes(colour=year))+
ggtitle("Median heartrate")+
xlab("Month/Year")
plot+
scale_x_date(date_labels = "%b/%Y")
Output:

一些尖峰仍然很突出。 这可能是由于爬升的台阶或楼梯数量增加。
这自然会引导我们进入下一个健康数据指标。
步数
最近的许多研究表明,您需要每天采取一定的步骤以保持健康。 出于我们项目的目的,我们假设以下类别适用:
- 每天少于5,000步 - 久坐
- 5,000-7,500之间 - 活动低
- 介于7,500到10,000之间 - 有点活跃
- 超过10,000 - 非常活跃
请注意,此分类完全是为了我们的研究而不是任何医学专业人士推荐的。
那么,让我们创建一个图表,向我们展示每年每天所采取的步骤总数:
steps <- df %>%
filter(type == 'HKQuantityTypeIdentifierStepCount') %>%
group_by(date,year,month) %>%
summarize(steps=sum(value))
steps$date <- as.Date(steps$date,"%Y-%m-%d")
plot2 <- ggplot(steps,aes(x=date, y=steps, group=year)) +
geom_line(aes(colour=year))+
geom_snooth(se=F)+
ggtitle("Total Steps Everyday")+
xlab("Month/Year")
plot2+
scale_x_date(date_labels = "%b/%Y")
Output:

这对我来说有点让人大开眼界。 这个情节显示我在2018年5月之前“有些活跃”,然后开始每天采取更多步骤。 增长趋势清晰可见。
但是2019年2月之后有所减少。我想更深入地了解这一点,以更细致的方式理解这一点。
因此,我创建了一个总结每周步数的图表。 由于我们在2019年看到异常加息,让我们看看每周的中位数步数:
step_count <- df %>%
filter(type == 'HKQuantityTypeIdentifierStepCount') %>%
filter(year==2019) %>%
group_by(dayofweek,year,month) %>%
summarize(step_count=median(value))
plot <- ggplot(step_count,aes(x=month, y=step_count, group=dayofweek)) +
geom_line(aes(colour=dayofweek),size=1.5)+
theme_minimal()+
ggtitle("Weekly median stepcount")
Output:
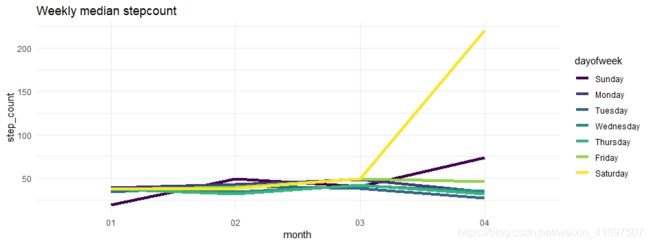
我们可以看到所有日子的步数中位数几乎相同。 因此我们可以肯定地说,步数数据中存在一些异常值。 您可以绘制平均计数,而不是绘制中位数。 这将告诉你周四中的一个有极高的观察。
是时候动画我们的图了:
plot+
geom_point() +
transition_reveal(as.numeric(month))
Output:
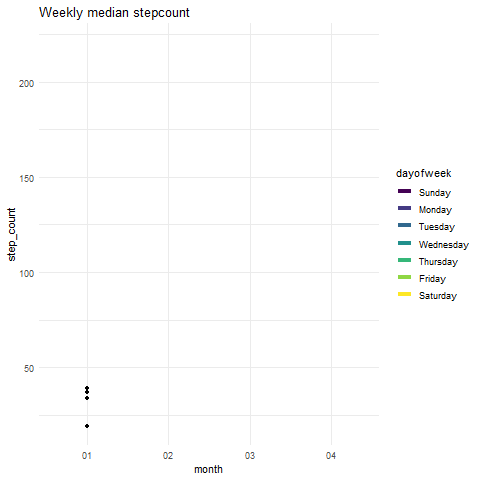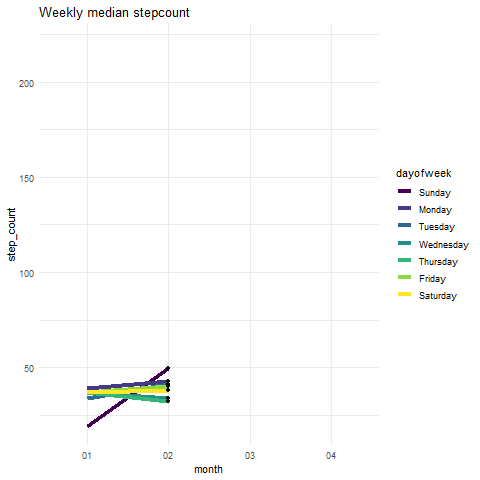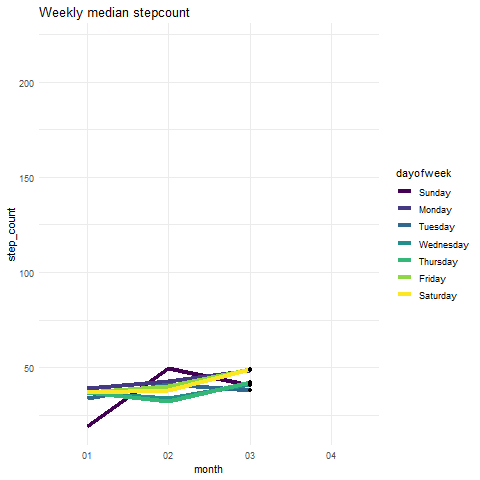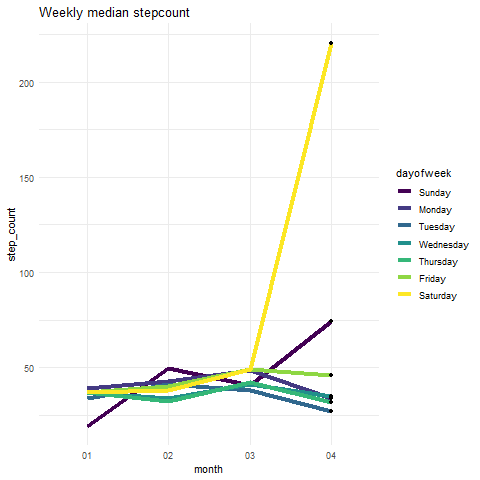
可爱! 让我们继续讨论下一个健康指标。
活跃的能量燃烧
我觉得这是我们健身追踪器中被低估的指标。 我们倾向于关注我们走过的步骤数量,看看我们是否覆盖了足够的地面。 我们燃烧的卡路里怎么样? 如果你问我,这是一个非常有趣的指标。
我们将再次创建一个时间序列图,向我们展示每日燃烧的总卡路里:
energy <- df %>%
filter(type == 'HKQuantityTypeIdentifierActiveEnergyBurned') %>%
group_by(date,year,month) %>%
summarize(energy_burned=sum(value))
energy$date <- as.Date(energy$date,"%Y-%m-%d")
plot3 <- ggplot(energy,aes(x=date, y=energy_burned, group=year)) +
geom_line(aes(colour=year))+
ggtitle("Total Energy burned")
plot3+
scale_x_date(date_labels = "%b/%Y")
Output:
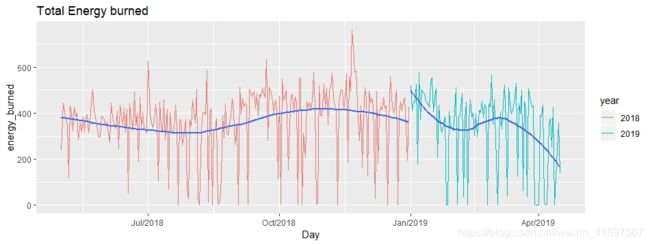
大多数日子都燃烧了大量的活跃卡路里。 该范围每天在400-600千卡之间。 但是有很多观察结果表明燃烧的卡路里在0到200千卡之间。
因此,为了过渡到更健康的生活方式,我应该每天消耗大约500卡路里,以便在一周内减掉1磅。
由于2019年4月的观测数量不足,我们的情节结束时急剧下降。
我们还能对这些数据做些什么呢? 要了解哪些日子需要更多的体力活动来燃烧所需的卡路里量,我们可以制定热图。 让我们这样做,以便每个月的每一天都被考虑在内。
# calendar heatmap: year wise calories burned
f <- df %>%
filter(type == 'HKQuantityTypeIdentifierActiveEnergyBurned') %>%
filter(year==2018) %>%
mutate(week_date = ceiling(day(creationDate) / 7)) %>%
group_by(week_date, month, dayofweek) %>%
summarise(total_cal = sum(value))
p <- ggplot(f,
aes(dayofweek, week_date, fill = f$total_cal)) +
geom_tile(colour = "white") +
facet_wrap(~month) +
theme_bw() +
scale_fill_gradient(name = "Total \nCalories",
low ="#56B1F7" , high = "#132B43") +
labs(x = "Week of the Month",
y = "Week number") +
scale_y_continuous(trans = "reverse")
Output:

上面的图可以通过以下方式轻松解释:
周日,在第5个月的第一周(2018年),燃烧的卡路里接近200.与我们给定的目标相比,这是非常低的。 除周日外,活动整体看起来相当不错。 这非常相关,对吗?
我们可以使用’gganimate’包中的’transition_states()'函数为这些热图或颜色密度图设置动画:
p + transition_states(dayofweek, wrap = FALSE)
Look at this cool visualization:
Output:
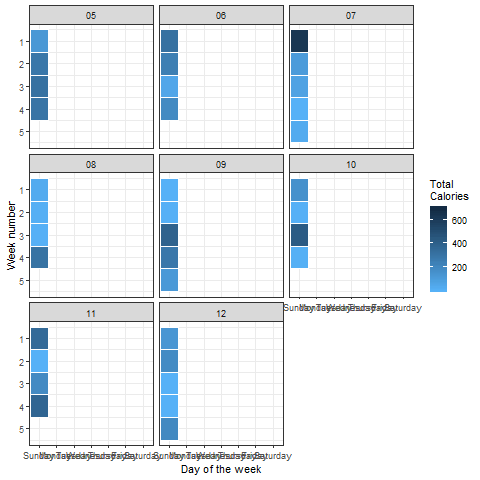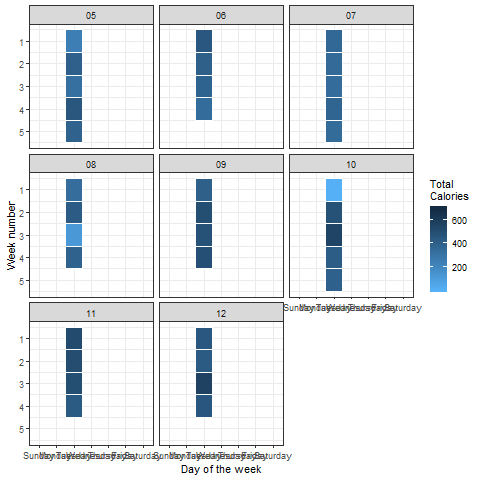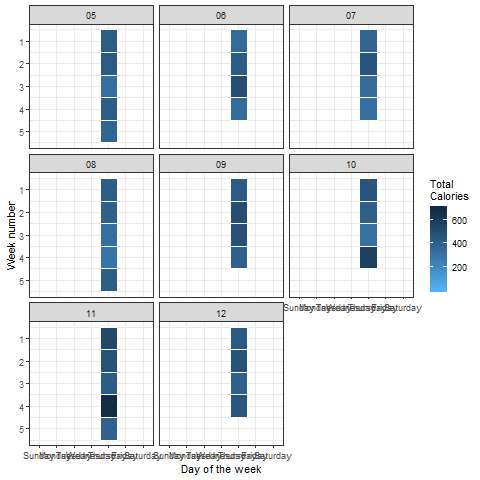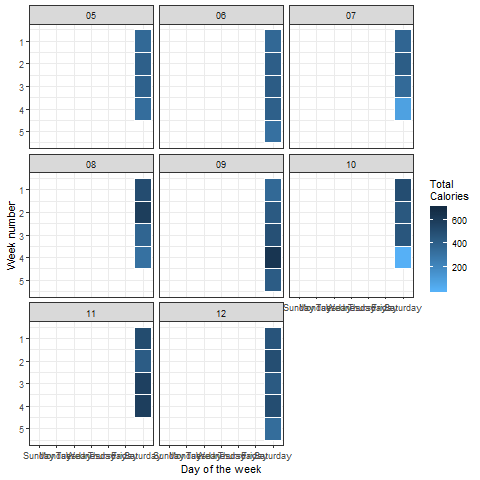
看起来很完美 毫不奇怪,与平日相比,周末燃烧的能源明显减少。
爬楼梯
这是一个独特的指标。 我认识的一些人跑上楼梯,以增强他们的健康。 我当然不这样做,但让我们看看我们可以从这些数据中挤出什么。
对于每年,我们将汇总一个月内攀爬的楼梯总数。 然后我们将绘制一个条形图,比较从上一年攀升的航班:
flight<-df %>%
filter(type == 'HKQuantityTypeIdentifierFlightsClimbed') %>%
group_by(year,month) %>%
summarize(flights=sum(value)) %>%
print (n=100) %>%
ggplot(aes(x=month, y=flights, fill=year)) +
geom_bar(position='dodge', stat='identity') +
scale_y_continuous(labels = scales::comma) +
theme(panel.grid.major = element_blank())+
ggtitle("Total flights climbed")
Output:
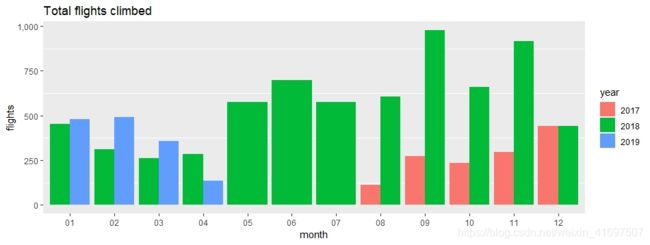
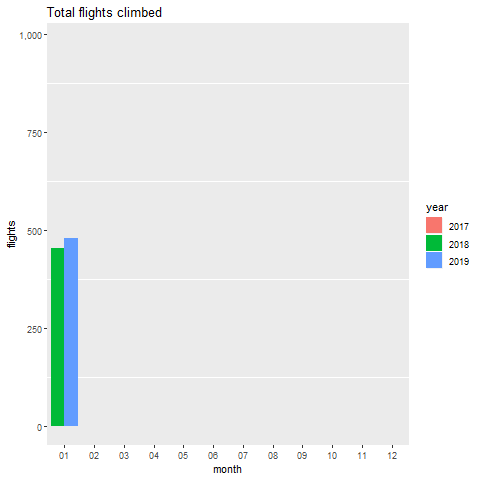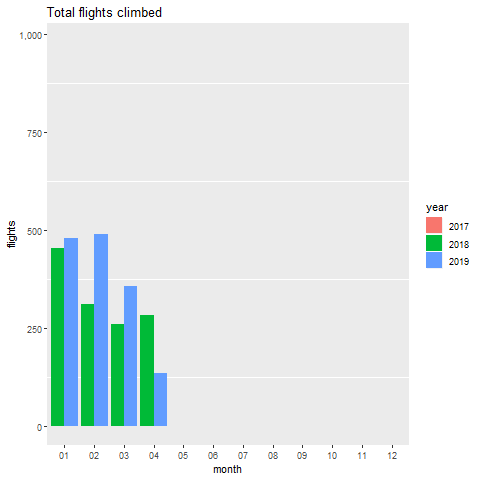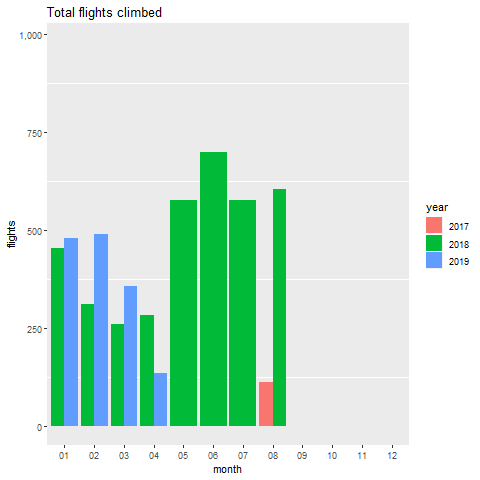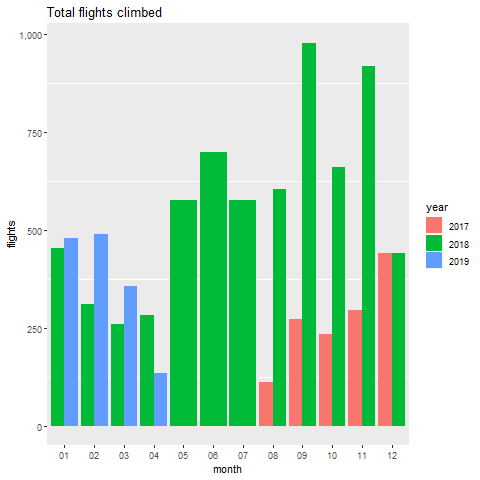
有什么东西跳出来吗? 爬楼梯的最大数量是2018年9月和11月。对此有合理的解释 - 我是会议组织团队的一员。 因此,数据飙升。
现在,我们可以将我们的研究结果与我们之前看到的燃烧能量图相关联。 我们看到2019年燃烧能源的下降趋势,对吧? 请注意2019年爬楼梯的数量是如何减少的。这部分归因于2019年4月的数据不足。
动画这个画图就像以前一样容易,来吧让我们试一试!
flight+transition_states(month, wrap = FALSE) +
shadow_mark()
Output:
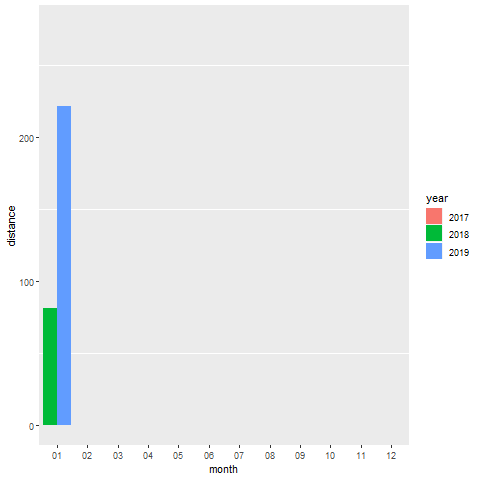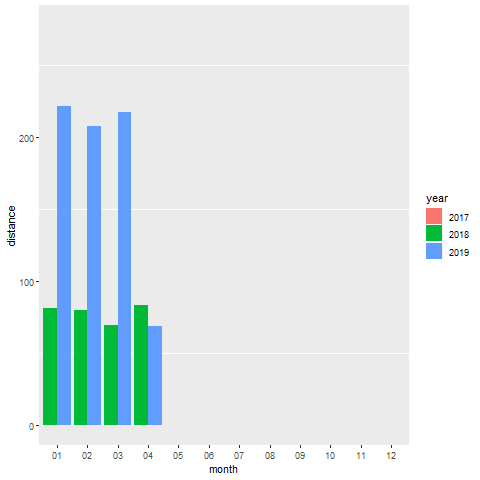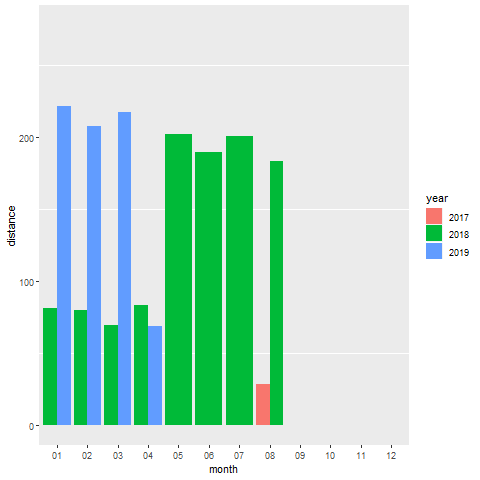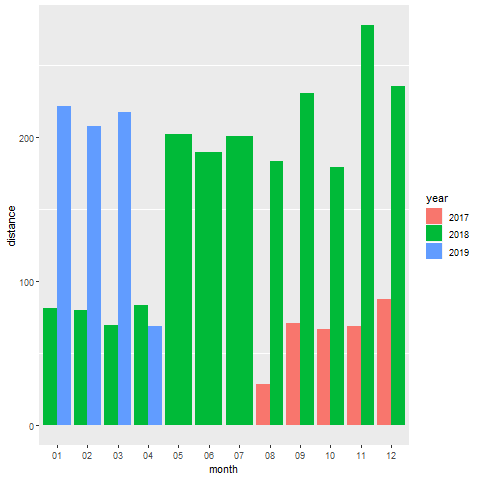
Distance Covered
使用上述方法,我们可以再次聚合与其各自年份相对应的不同月份的行进距离(以公里为单位):
df %>%
filter(type == 'HKQuantityTypeIdentifierDistanceWalkingRunning') %>%
group_by(year,month) %>%
summarize(distance=sum(value)) %>%
print (n=100) %>%
ggplot(aes(x=month, y=distance, fill=year)) +
geom_bar(position='dodge', stat='identity') +
scale_y_continuous(labels = scales::comma) +
theme(panel.grid.major = element_blank())
Output:
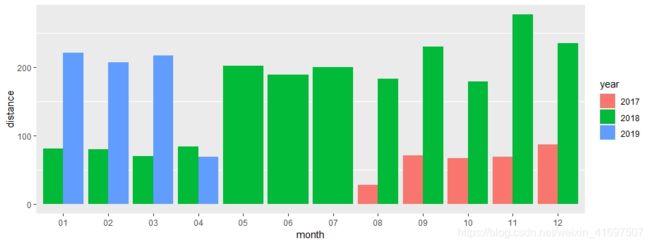
正如预期的那样,2018年11月的旅行距离非常突出。 我们在本文中生成的每个图都可以获得很多洞察力。 这对我来说是一段非常有趣的旅程!
最后,另一个距离的动画:
dist+transition_states(month, wrap = FALSE) +
shadow_mark()
Output:
End Notes
数据可视化是对任何数据进行稳健分析的关键步骤之一。 不仅仅是花哨的数据集,您可以检查您的环境是否有任何数据源,并将它们用于您自己的个性化项目。 这不是很令人兴奋吗?
我们向您展示了大量的情节,让您开始使用自己的健身仪表板。 传输数据并开始练习! 如果您准备好任何更好或改进的地块,请不要忘记更新社区。