集成学习(机器学习)
集成学习
-
Bagging
实例:

- 采样方式
随机采样(bootsrap)就是从我们的训练集中采集固定个数的样本,但是每采样一个样本后,都将样本放回。也就是说,之前采集到的样本放回后有可能继续被采集到。
- 集成方式
Bagging的集合策略也比较简单,对于分类问题,通常使用简单投票法,得到最多票数的类别或者类别之一为最终的模型输出。对于回归问题,通常采用简单平均,对弱学习器得到的回归结果进行算数平均得到最终的模型输出
- 优缺点
其主要目的为通过平均降低方差。 Z 1 , Z 2 , ⋯ , Z n Z_1,Z_2,\cdots,Z_n Z1,Z2,⋯,Zn的方差为 δ 2 / n \delta^2/n δ2/n。采用Bagging策略明显减小模型方差(variance)。
此方法降低了方差,但由于将多棵决策树的结果进行了平均,这损失了模型的可解释性。同时对于训练集的拟合程度会差一些,也就是模型的偏倚会大一些。
-
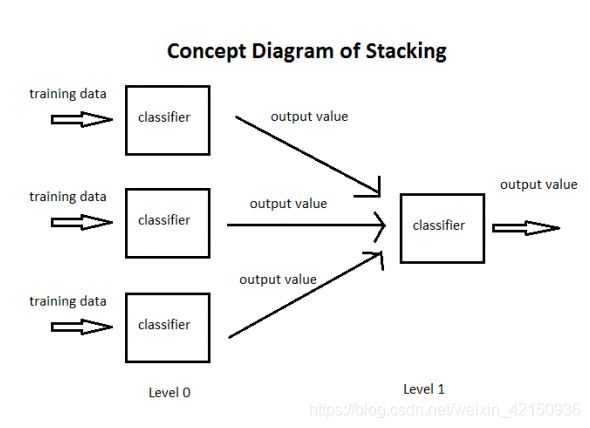
Stacking
Stacking就是当用初始训练数据学习出若干个基学习器后,将几个学习期的预测结果作为新的训练集,来学习一个新的学习器
实例:
-
采样方式
直接使用测试集进行预测
-
集成方式
a. 使用交叉验证方式对训练集样本进行训练得到第一层classifier,之后使用classifier对训练集样本进行预测从而得到结果(nm的矩阵,n表示训练集的行数,m代表分类器的个数)
b. 将第一层的测试结果(nm矩阵)作为输入,对训练集进行训练得到第二层的classifier,则得到第二层classfier -
优缺点
它的平滑性和突出每个基本模型在其中执行的最好的能力,并且抹黑其执行不佳的每个基本模型,所以由于单个模型。当基本模型显著不同时,堆叠是最有效的。
- Boost算法
-
简介
Boost(提升),是指每次我都产生一个弱模型,然后加权累加到总模型中,然后每一步弱预测模型生成的依据都是损失函数的负梯度方向,这样若干步后就可以达到逼近损失函数局部最小值的目的
-
加法模型
f ( x ) = ∑ m = 1 M β m b ( x ; θ m ) f(x)=\sum_{m=1}^M\beta_mb(x;\theta_m) f(x)=m=1∑Mβmb(x;θm)
其中 b b b是基函数, β \beta β是基函数的系数,这就是最终分类器。现在我们的目标是使损失函数的期望取最小值,也就是:
min β m , θ m ∑ i = 1 N L ( y i , ∑ m = 1 M β m b ( x i ; θ m ) ) \min_{\beta_m,\theta_m}\sum_{i=1}^NL(y_i,\sum_{m=1}^M\beta_mb(x_i;\theta_m)) βm,θmmini=1∑NL(yi,m=1∑Mβmb(xi;θm))一次性对M个分类器同时进行优化,显然不现实。因此提出了以下的想法:
min β m , θ m ∑ i = 1 N L ( y i , f m − 1 + β m b ( x i ; θ m ) ) \min_{\beta_m,\theta_m}\sum_{i=1}^NL(y_i,f_{m-1}+\beta_mb(x_i;\theta_m)) βm,θmmini=1∑NL(yi,fm−1+βmb(xi;θm))要使损失函数最小,那就使得新加的一项刚好等于损失函数的负梯度,这样不就使得损失函数的下最快下降了吗,因此就有:
β m b ( x ; θ m ) = − λ d L ( y , f m − 1 ) d f \beta_mb(x;\theta_m)=-\lambda \frac{dL(y,f_{m-1})}{df} βmb(x;θm)=−λdfdL(y,fm−1)
此方法只是对提升法的解释,使用时还需要根据具体情况分析
- 处理方法之GDBT
- 采用平方误差作为损失函数
L ( y , f m − 1 ( x ) + β m b ( x ; θ m ) ) L(y,f_{m-1}(x)+\beta_mb(x;\theta_m)) L(y,fm−1(x)+βmb(x;θm))
( y − f m − 1 ( x ) − β m b ( x ; θ m ) ) 2 (y-f_{m-1}(x)-\beta_mb(x;\theta_m))^2 (y−fm−1(x)−βmb(x;θm))2
-
数据处理
上式可以等价于:
( γ m − 1 − β m b ( x ; θ m ) ) 2 (\gamma_{m-1}-\beta_mb(x;\theta_m))^2 (γm−1−βmb(x;θm))2 -
理解
以 γ m − 1 \gamma_{m-1} γm−1作为输出,使用X去拟合一个回归树进而形成新的区域划分 R m R_m Rm。划分后,将会生成新的区域如 R m 1 , R m 2 , ⋯ R m j R_{m1},R_{m2},\cdots R_{mj} Rm1,Rm2,⋯Rmj,对应的取值为 c m 1 , c m 2 , ⋯ c m j c_{m1},c_{m2},\cdots c_{mj} cm1,cm2,⋯cmj
f m = f m − 1 + ∑ j = 1 m c m j I ( x ∈ R m j ) f_{m}=f_{m-1}+\sum_{j=1}^mc_{mj}I(x\in R_{mj}) fm=fm−1+j=1∑mcmjI(x∈Rmj)
- Adaboost的原理
-
简介
AdaBoost,是英文“Adaptive Bootsing”的缩写。它的自适应在于:前一个基本分类器分错的样本会得到加强,加权后的全体样本再次被用来训练下一个基本分类器。同时,在每一轮转中加入一个新的弱分类器,直到达到某个预定的足够小的错误率或达到预指定的最大迭代次数。
具体来说,整个Adaboost迭代算法就3步:
a. 初始化训练数据的权值分布。如果有N个样本,则每个训练样本最开始时都被赋予相同的权值:1/N
b. 训练弱分类器。具体训练过程中,如果某个样本点已经被准去地分类,那么在构造下一个训练集中,它的权值就被降低;相反,如果某个样本点没有被准确地分类,那么它的权值就得到提高。然后,权值更新过的样本集被用于训练下一个分类器,整个训练过程如此迭代地进行下去。
c. 将各个训练得到的弱分类器组合成强分类器。各个弱分类器的训练过程结束后,加大分类误差率小的分类器的权重,使其在最终的分类函数中起着较大的决定作用,而降低分类误差较大的弱分类器的权重,使其在最终的分类函数中起着较小的决定作用。换言之,误差率低的弱分类器在最终分类器中的权重较大,否则较小 -
计算流程
给定一个训练数据集 T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x N , y N ) } T=\{(x_1,y_1),(x_2,y_2),\cdots,(x_N,y_N)\} T={(x1,y1),(x2,y2),⋯,(xN,yN)},其中实例 x ∈ R n x\in R^n x∈Rn, y i ∈ Y = { − 1 , + 1 } y_i \in Y=\{-1,+1\} yi∈Y={−1,+1}。Adaboost的目的就是从训练集中学习到一系列弱分类器或基本分类器,最后将这些弱分类器组合成为一个强分类器。
步骤1. 初始化训练数据的权值分布。每个样本最初时都被赋予相同的权值: 1 / N 1/N 1/N
D 1 = ( w 11 , w 12 , ⋯ , w 1 N ) , w 1 i = 1 N , i = 1 , 2 , ⋯ , N D_1=(w_{11},w_{12},\cdots ,w_{1N}),w_{1i}=\frac{1}{N},i=1,2,\cdots,N D1=(w11,w12,⋯,w1N),w1i=N1,i=1,2,⋯,N步骤2. 进行多轮迭代,用m=1,2,…M代表迭代的轮数
a. 使用权值分布 D m D_m Dm的训练数据集学习,得到基本分类器
G m : X → { − 1 , 1 } G_m:X \rightarrow \{-1,1\} Gm:X→{−1,1}
b. 计算 G m ( x ) G_m(x) Gm(x)在训练集上的分类误差率:
e m = P ( G m ( x i ) ≠ y i ) = ∑ i = 1 n w m i I ( G m ( x i ) ≠ y i ) e_m=P(G_m(x_i)\neq y_i)=\sum_{i=1}^{n}w_{mi}I(G_m(x_i)\neq y_i) em=P(Gm(xi)̸=yi)=i=1∑nwmiI(Gm(xi)̸=yi)
注: I ( G m ( x i ) ≠ y i ) I(G_m(x_i)\neq y_i) I(Gm(xi)̸=yi):不等函数 I I I的值为1,相等函数 I I I的值为0c. 计算G_m(x)的系数
a m = 1 2 log 1 − e m e m a_m=\frac{1}{2}\log \frac{1-e_m}{e_m} am=21logem1−em
这里的对数是自然对数。显然 a m a_m am是 e m e_m em的单调函数,这里就解释了为什么对于没有正确分类的数据要加大权值d. 更新训练集的权值
D m + 1 = ( w m + 1 , 1 , w w + 1 , 2 , ⋯ , w m + 1 , N ) D_{m+1}=(w_{m+1,1},w_{w+1,2},\cdots,w_{m+1,N}) Dm+1=(wm+1,1,ww+1,2,⋯,wm+1,N)
w m + 1 , i = w m i Z m e x p ( − α m y i G m ( x i ) ) w_{m+1,i}=\frac{w_{mi}}{Z_m}exp(-\alpha_my_iG_m(x_i)) wm+1,i=Zmwmiexp(−αmyiGm(xi))
这里, Z m Z_m Zm是泛化因子
Z m = ∑ i = 1 N w m i e x p ( − α m y i G m ( x i ) ) Z_m=\sum_{i=1}^{N}w_{mi}exp(-\alpha_my_iG_m(x_i)) Zm=i=1∑Nwmiexp(−αmyiGm(xi))
它使得 D m + 1 D_{m+1} Dm+1成为一个概率分布
步骤3. 构建基本分类器的线性组合
f ( x ) = ∑ m = 1 M a m G m ( x ) f(x)=\sum_{m=1}^Ma_mG_m(x) f(x)=m=1∑MamGm(x)
得到最终分类器:
G ( x ) = s i g n ( f ( x ) ) = s i g n ( ∑ m = 1 M a m G m ( x ) ) G(x)=sign(f(x))=sign(\sum_{m=1}^Ma_mG_m(x)) G(x)=sign(f(x))=sign(m=1∑MamGm(x))
- 特点
标准的Adaboot算法只适用于二分类,要想让其处理多分类或回归任务还需要对其进行修改
- Adaboost公式推导
- 损失函数
L ( y , f ( x ) = e x p [ − y f ( x ) ] L(y,f(x)=exp[-yf(x)] L(y,f(x)=exp[−yf(x)]
- 目标
( a m , G m ( x ) ) = a r g m i n a , G ∑ i = 1 N e x p [ − y i ( f m − 1 ( x i ) + a G ( x i ) ) ] (a_m,G_m(x))=argmin_{a,G}\sum_{i=1}^Nexp[-y_i(f_{m-1}(x_i)+aG(x_i))] (am,Gm(x))=argmina,Gi=1∑Nexp[−yi(fm−1(xi)+aG(xi))]
其中 f m − 1 ( x i ) f_{m-1}(x_i) fm−1(xi)代表 x i x_i xi在m-1棵树的得分
- 推导
( a m , G m ( x ) ) = a r g m i n a , G ∑ i = 1 N w ^ m i e x p [ − y i a G ( x i ) ] (a_m,G_m(x))=argmin_{a,G}\sum_{i=1}^N\hat w_{mi}exp[-y_iaG(x_i)] (am,Gm(x))=argmina,Gi=1∑Nw^miexp[−yiaG(xi)]
其中 w ^ m i = e x p [ − y i f m − 1 ( x i ) ] \hat w_{mi}=exp[-y_if_{m-1}(x_i)] w^mi=exp[−yifm−1(xi)]。 w ^ m i \hat w_{mi} w^mi既不依赖于 a a a也不依赖于 G G G,与最小值无关
- 化简上式的右式可得:
e − a ∑ y i = G ( x i ) w ^ m i + e a ∑ y i ≠ G ( x i ) w ^ m i e^{-a}\sum_{y_i = G(x_i)} \hat w_{mi}+e^{a}\sum_{y_i \neq G(x_i)} \hat w_{mi} e−ayi=G(xi)∑w^mi+eayi̸=G(xi)∑w^mi
加上两个基础项有:
e − a ∑ y i = G m ( x ) w ^ m i + e a ∑ y i ≠ G ( x i ) w ^ m i + e − a ∑ y i ≠ G ( x i ) w ^ m i − e − a ∑ y i ≠ G ( x i ) w ^ m i e^{-a}\sum_{y_i = G_m(x)} \hat w_{mi}+e^{a}\sum_{y_i \neq G(x_i)} \hat w_{mi}+e^{-a}\sum_{y_i \neq G(x_i)}\hat w_{mi}-e^{-a}\sum_{y_i \neq G(x_i)}\hat w_{mi} e−ayi=Gm(x)∑w^mi+eayi̸=G(xi)∑w^mi+e−ayi̸=G(xi)∑w^mi−e−ayi̸=G(xi)∑w^mi
等价于
( e a − e − a ) ∑ y i ≠ G ( x i ) w ^ m i + e − a ∑ i = 1 n w m i (e^{a}-e^{-a})\sum_{y_i \neq G(x_i)}\hat w_{mi}+e^{-a}\sum_{i=1}^n w^{mi} (ea−e−a)yi̸=G(xi)∑w^mi+e−ai=1∑nwmi
等价于
( e a − e − a ) ∑ i = 1 n w ^ m i I ( y i ≠ G ( x i ) ) + e − a ∑ i = 1 n w ^ m i (e^{a}-e^{-a})\sum_{i=1}^n\hat w_{mi}I(y_i\neq G(x_i))+e^{-a}\sum_{i=1}^n\hat w_{mi} (ea−e−a)i=1∑nw^miI(yi̸=G(xi))+e−ai=1∑nw^mi
上式中 w ^ m i \hat w_{mi} w^mi是由上次迭代计算得到,当a已知时需要使下面的之最小
G m = a r g min G ∑ i = 1 n w ^ m i I ( y i ≠ G ( x i ) ) G_m=arg\min_G\sum_{i=1}^n\hat w_{mi}I(y_i \neq G(x_i)) Gm=argGmini=1∑nw^miI(yi̸=G(xi))
进一步求 a a a使损失函数最小,则有:
∂ L ∂ a = ( e a + e − a ) ∑ i = 1 n w ^ m i I ( y i ≠ G ( x i ) ) − e − a ∑ i = 1 n w ^ m i = 0 \frac{\partial L}{\partial a}=(e^a+e^{-a})\sum_{i=1}^n\hat w_{mi}I(y_i\neq G(x_i))-e^{-a}\sum_{i=1}^n\hat w_{mi}=0 ∂a∂L=(ea+e−a)i=1∑nw^miI(yi̸=G(xi))−e−ai=1∑nw^mi=0
化简可得:
e 2 a ∑ i = 1 n w ^ m i I ( y i ≠ G ( x i ) ) = ∑ i = 1 n w ^ m i − ∑ i = 1 n w ^ m i I ( y i ≠ G ( x i ) ) e^{2a}\sum_{i=1}^n\hat w_{mi}I(y_i\neq G(x_i))=\sum_{i=1}^n\hat w_{mi}-\sum_{i=1}^n\hat w_{mi}I(y_i\neq G(x_i)) e2ai=1∑nw^miI(yi̸=G(xi))=i=1∑nw^mi−i=1∑nw^miI(yi̸=G(xi))
进而可得最小参数 a m a_m am:
a m = 1 2 l o g ∑ i = 1 n w ^ m i − ∑ i = 1 n w ^ m i I ( y i ≠ G ( x i ) ) ∑ i = 1 n w ^ m i I ( y i ≠ G ( x i ) ) a_m = \frac{1}{2}log\frac{\sum_{i=1}^n\hat w_{mi}-\sum_{i=1}^n\hat w_{mi}I(y_i\neq G(x_i))}{\sum_{i=1}^n\hat w_{mi}I(y_i\neq G(x_i))} am=21log∑i=1nw^miI(yi̸=G(xi))∑i=1nw^mi−∑i=1nw^miI(yi̸=G(xi))
因为错误率为:
e m = ∑ i = 1 n w ^ m i I ( y i ≠ G ( x i ) ) ∑ i = 1 n w ^ m i e_m=\frac{\sum_{i=1}^n \hat w_{mi}I(y_i \neq G(x_i))}{\sum_{i=1}^n \hat w_{mi}} em=∑i=1nw^mi∑i=1nw^miI(yi̸=G(xi))
进而计算 a m a_m am
a m = 1 2 l o g 1 − e m e m a_m=\frac{1}{2}log\frac{1-e_m}{e_m} am=21logem1−em
根据 w m i = e x p ( − y i f m − 1 ( x i ) ) w_{mi}=exp(-y_if_{m-1}(x_i)) wmi=exp(−yifm−1(xi)),更新 w w w公式可得:
w ( m + 1 ) i = e x p ( − y i f m ( x i ) ) w_{(m+1)i}=exp(-y_if_m(x_i)) w(m+1)i=exp(−yifm(xi))
= e x p ( − y i ( f m − 1 ( x i ) + a m G m ( x i ) ) ) =exp(-y_i(f_{m-1}(x_i)+a_mG_m(x_i))) =exp(−yi(fm−1(xi)+amGm(xi)))
= w m i e x p ( − a m y i G m ( x i ) ) =w_{mi}exp(-a_my_iG_m(x_i)) =wmiexp(−amyiGm(xi))
- Xgboost公式推导
- 定义损失函数
L ( y i , y ^ i t ) = ∑ i = 1 n + L ( y i , y ^ i t − 1 + f t ( x i ) ) + Ω ( f t ) L(y_i,\hat y_i^t)=\sum_{i=1}^n +L(y_i,\hat y_i^{t-1}+f_t(x_i))+\Omega(f_t) L(yi,y^it)=i=1∑n+L(yi,y^it−1+ft(xi))+Ω(ft)
- 对定义进行泰勒展开
L ( y i , y ^ i t ) = ∑ i = 1 n [ L ( y i , y ^ i t − 1 ) + g i f t ( x ) + 1 2 h i ( f t ( x ) ) 2 ] + Ω ( f t ) L(y_i,\hat y_i^t)=\sum_{i=1}^n\big[L(y_i,\hat y_i^{t-1})+g_if_t(x)+\frac{1}{2}h_i(f_t(x))^2\big]+\Omega(f_t) L(yi,y^it)=i=1∑n[L(yi,y^it−1)+gift(x)+21hi(ft(x))2]+Ω(ft)
L ( y i , y ^ i t ) = ∑ i = 1 n L ( y i , y ^ i t − 1 ) + ∑ i = 1 n [ g i f t ( x ) + 1 2 h i ( f t ( x ) ) 2 ] + γ T + 1 2 λ ∣ ∣ w ∣ ∣ 2 L(y_i,\hat y_i^t)=\sum_{i=1}^n L(y_i,\hat y_i^{t-1})+\sum_{i=1}^n \big[g_if_t(x)+\frac{1}{2}h_i(f_t(x))^2\big] +\gamma T+\frac{1}{2}\lambda ||w||_2 L(yi,y^it)=i=1∑nL(yi,y^it−1)+i=1∑n[gift(x)+21hi(ft(x))2]+γT+21λ∣∣w∣∣2
- 优化损失函数转化为优化以下式子
∑ i = 1 n g i f t ( x ) + 1 2 ∑ i = 1 n [ h i w i 2 + λ w i 2 ] \sum_{i=1}^ng_if_t(x)+\frac{1}{2}\sum_{i=1}^n\big[h_i w_i^2+\lambda w_i^2\big] i=1∑ngift(x)+21i=1∑n[hiwi2+λwi2]
- 使用叶子结点表示如下:
∑ j = 1 T [ ( ∑ i ∈ I j g i ) w j + 1 2 ( ∑ i ∈ I j h i + λ ) w i 2 ] + γ T \sum_{j=1}^T\big[\big( \sum_{i \in I_j}{g_i}\big)w_j +\frac{1}{2}\big(\sum_{i \in I_j}h_i+\lambda \big)w_i^2\big]+\gamma T j=1∑T[(i∈Ij∑gi)wj+21(i∈Ij∑hi+λ)wi2]+γT
- 优化方法转换为
w j ∗ = − G j H j + λ w_j^*=-\frac{G_j}{H_j+\lambda} wj∗=−Hj+λGj
其中: G j = ∑ i ∈ I j g i , H j = ∑ i ∈ I j h i G_j=\sum_{i\in I_j}g_i,H_j=\sum_{i\in I_j}h_i Gj=∑i∈Ijgi,Hj=∑i∈Ijhi
损失函数的取值如下:
− 1 2 ∑ j = 1 T G j 2 H j + λ + λ T -\frac{1}{2}\sum_{j=1}^T\frac{G_j^2}{H_j+\lambda}+\lambda T −21j=1∑THj+λGj2+λT
- 贪心算法
G a i n = 1 2 [ G L 2 H L + λ + G R 2 H R + λ − ( G L + G R ) 2 H L + H R + λ ] − λ T Gain = \frac{1}{2}\big[ \frac{G_L^2}{H_L+\lambda} + \frac{G_R^2}{H_R+\lambda} -\frac{(G_L+G_R)^2}{H_L+H_R+\lambda}\big]-\lambda T Gain=21[HL+λGL2+HR+λGR2−HL+HR+λ(GL+GR)2]−λT