用idea开发我们的spark项目
写在前面
如果你是刚入行的java(或大数据)菜鸟,如果你还不会使用idea这样的“神兵利器”,如果你还对 mvn clean package 这样的命令一知半解。那么,你有必要花点时间,瞧一瞧这篇文章,正所谓,“工欲善其事,必先利其器”,它将指导你一步一步用idea开发出我们的spark程序,用maven编译打包我们的Scala(Scala与Java混合)代码。当然,大神请自动忽略。
开发环境
- macOs Mojave
- idea 2019.3.1
- maven-3.6.4
- spark-2.4.3
- hadoop-2.7.4
- jdk-1.8
- scala-2.1.8
快速开始
1. 创建一个空的maven项目
2. 使用Scala插件
使用scala插件,Scala插件的安装和使用在此将不做赘述。引入Scala插件之后,我们就能愉快地编辑我们的Scala代码。
3. 编辑pom文件
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>com.dr.leogroupId>
<artifactId>leo-study-sparkartifactId>
<version>1.0-SNAPSHOTversion>
<description>跟着leo学习sparkdescription>
<url>https://www.jlpyyf.comurl>
<developers>
<developer>
<id>leoid>
<name>leo.jiename>
<email>[email protected]email>
<roles>
<role>developerrole>
roles>
developer>
developers>
<properties>
<project.build.sourceEncoding>UTF-8project.build.sourceEncoding>
<maven.compiler.source>1.8maven.compiler.source>
<maven.compiler.target>1.8maven.compiler.target>
<spark.version>2.4.3spark.version>
<scala.version>2.11scala.version>
<spark.cope>providedspark.cope>
properties>
<dependencies>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_${scala.version}artifactId>
<version>${spark.version}version>
<scope>${spark.cope}scope>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-sql_${scala.version}artifactId>
<version>${spark.version}version>
<scope>${spark.cope}scope>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-hive_${scala.version}artifactId>
<version>${spark.version}version>
<scope>${spark.cope}scope>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>5.1.32version>
dependency>
<dependency>
<groupId>com.microsoft.sqlservergroupId>
<artifactId>mssql-jdbcartifactId>
<version>6.1.0.jre8version>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<groupId>org.scala-toolsgroupId>
<artifactId>maven-scala-pluginartifactId>
<version>2.15.0version>
<executions>
<execution>
<goals>
<goal>compilegoal>
<goal>testCompilegoal>
goals>
execution>
executions>
<configuration>
<scalaVersion>${scala.version}scalaVersion>
<args>
<arg>-target:jvm-1.5arg>
args>
configuration>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-eclipse-pluginartifactId>
<version>2.10version>
<configuration>
<downloadSources>truedownloadSources>
<buildcommands>
<buildcommand>ch.epfl.lamp.sdt.core.scalabuilderbuildcommand>
buildcommands>
<additionalProjectnatures>
<projectnature>ch.epfl.lamp.sdt.core.scalanatureprojectnature>
additionalProjectnatures>
<classpathContainers>
<classpathContainer>org.eclipse.jdt.launching.JRE_CONTAINERclasspathContainer>
<classpathContainer>ch.epfl.lamp.sdt.launching.SCALA_CONTAINERclasspathContainer>
classpathContainers>
configuration>
plugin>
<plugin>
<artifactId>maven-assembly-pluginartifactId>
<version>3.1.1version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependenciesdescriptorRef>
descriptorRefs>
<finalName>leo-study-sparkfinalName>
<appendAssemblyId>falseappendAssemblyId>
configuration>
<executions>
<execution>
<id>make-assemblyid>
<phase>packagephase>
<goals>
<goal>singlegoal>
goals>
execution>
executions>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-compiler-pluginartifactId>
<version>3.6.0version>
<configuration>
<source>1.8source>
<target>1.8target>
configuration>
plugin>
<plugin>
<groupId>org.codehaus.mojogroupId>
<artifactId>build-helper-maven-pluginartifactId>
<version>1.10version>
<executions>
<execution>
<id>add-sourceid>
<phase>generate-sourcesphase>
<goals>
<goal>add-sourcegoal>
goals>
<configuration>
<sources>
<source>src/main/javasource>
<source>src/main/scalasource>
sources>
configuration>
execution>
executions>
plugin>
plugins>
build>
<reporting>
<plugins>
<plugin>
<groupId>org.scala-toolsgroupId>
<artifactId>maven-scala-pluginartifactId>
<configuration>
<scalaVersion>${scala.version}scalaVersion>
configuration>
plugin>
plugins>
reporting>
project>
pom 文件中引入了spark的一些核心依赖以及编译打包Scala和Java代码的插件。
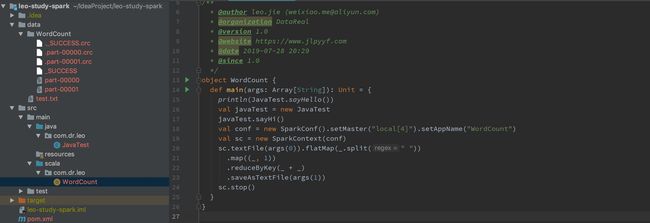
4. 编写WordCount程序
object WordCount {
def main(args: Array[String]): Unit = {
println(JavaTest.sayHello())
val javaTest = new JavaTest
javaTest.sayHi()
val conf = new SparkConf().setMaster("local[4]").setAppName("WordCount")
val sc = new SparkContext(conf)
sc.textFile(args(0)).flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_ + _)
.saveAsTextFile(args(1))
sc.stop()
}
}
- 最终的项目结构:
- 编译打包,发往集群上运行
- 注意一:一般情况下,我们pom中引入的spark相关依赖是不需要打进我们最终的jar中的。所以修改,spark相关依赖的scope属性值为provided。
- 注意二:如果jar需要以集群模式运行,则需要注释我们的WordCount程序中的 setMaster(“local[4]”)
- 运行maven的打包命令
mvn clean package
- 打包结果
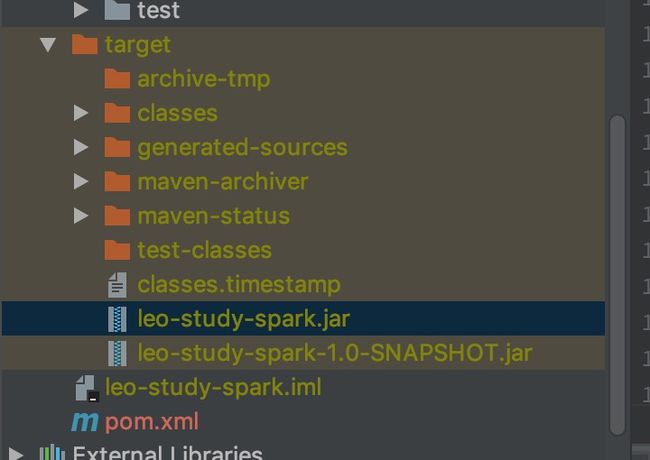
- leo-study-spark.jar就是我们需要在集群上运行的可执行jar包
- 上传leo-study-spark.jar到集群,执行如下命令:
spark-submit --master yarn --deploy-mode cluster --driver-memory 2G --executor-memory 2g --num-executors 5 --conf spark.yarn.executor.memoryOverhead=2048 --conf spark.network.timeout=30000 --class com.dr.leo.WordCount leo-study-spark.jar hdfs://leo/test/test.txt hdfs://leo/test/leo_word_count
- 运行结果截图
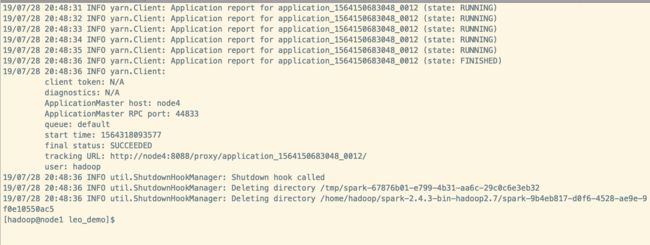
- WordCount的输出结果
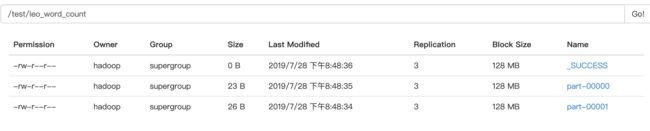
- yarn ui 查看我们刚刚提交的任务

Scala代码中调用Java的方法的结果输出。
小节
以上便完成了spark的项目的搭建,以及用maven编译打包我们的Scala程序。整个流程最核心的其实是pom.xml文件,当然,这个pom.xml文件应该不是最完美的,如有不足之处,还望大家积极指正,与君共勉。