Elasticsearch 写流程
本文分析ES写入单个和批量文档写请求的处理流程,仅限于ES内部实现,并不涉及Lucene内部处理。在ES中,写入单个文档的请求称为Index请求,批量写入的请求称为Bulk请求。写单个和多个文档使用相同的处理逻辑,请求被统一封装为BulkRequest。
1、文档操作的定义
在ES中,对文档的操作有下面几种类型:
enum OpType {
INDEX(0),
CREATE(1),
UPDATE(2),
DELETE(3);
}
- INDEX:向索引中“put”一个文档的操作称为“索引”一个文档。此处“索引”为动词。
- CREATE:put 请求可以通过 op_type 参数设置操作类型为 create,在这种操作下,如果文档已存在,则请求将失败。
- UPDATE:默认情况下,“put”一个文档时,如果文档已存在,则更新它。
- DELETE:删除文档。
在put API中,通过op_type参数来指定操作类型。
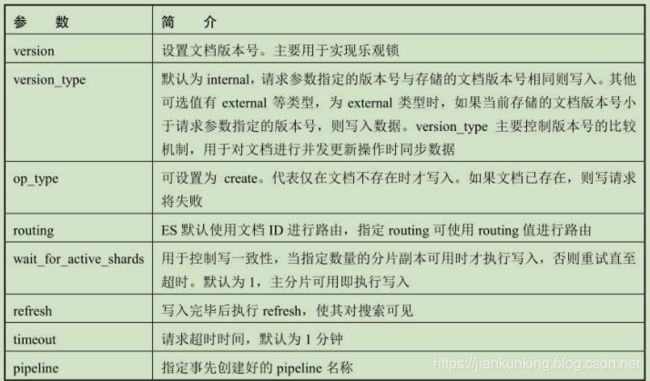
2、可选参数
Index API和Bulk API有一些可选参数,这些参数在请求的URI中指定,例如:
PUT my-index/my-type/my-id?pipeline=my_pipeline_id
{
"foo": "bar"
}
下面简单介绍各个参数的作用,这些参数在接下来的流程分析中都会遇到,如下表所示:
3、Index/Bulk基本流程
新建、索引(这里的索引是动词,指写入操作,将文档添加到Lucene的过程称为索引一个文档)和删除请求都是写操作。写操作必须先在主分片执行成功后才能复制到相关的副分片。写单个文档的流程(图片来自官网)如下图所示:
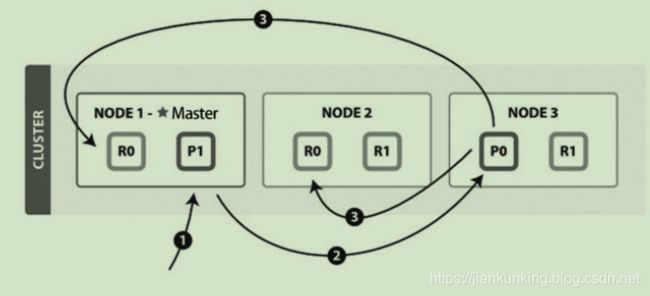
以下是写单个文档所需的步骤:
- 客户端向NODE1发送写请求。
- NODE1使用文档ID来确定文档属于分片0,通过集群状态中的内容路由表信息获知分片0的主分片位于NODE3,因此请求被转发到NODE3上。
- NODE3上的主分片执行写操作。如果写入成功,则它将请求并行转发到 NODE1和NODE2的副分片上,等待返回结果。当所有的副分片都报告成功,NODE3将向协调节点报告成功,协调节点再向客户端报告成功。
在客户端收到成功响应时,意味着写操作已经在主分片和所有副分片都执行完成。
写一致性的默认策略是quorum,即多数的分片(其中分片副本可以是主分片或副分片)在写入操作时处于可用状态。
quorum = int( (primary + number_of_replicas) / 2 ) + 1
4、Index/Bulk详细流程
以不同角色节点执行的任务整理流程如下图所示:
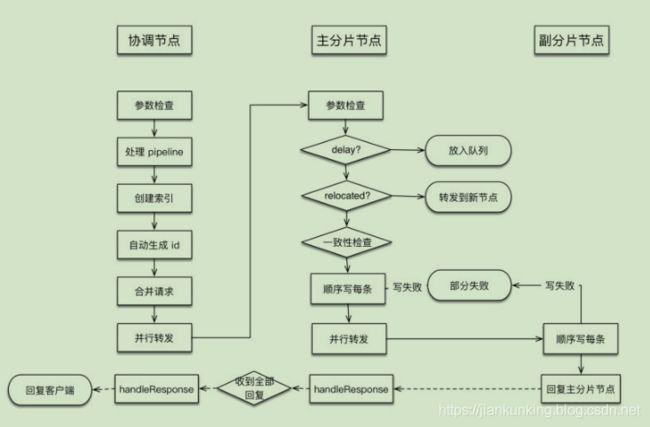
下面分别讨论各个节点上执行的流程。
4.1 协调节点流程
协调节点负责创建索引、转发请求到主分片节点、等待响应、回复客户端。
1、 参数检查
如同我们平常设计的任何一个对外服务的接口处理一样,收到用户请求后首先检测请求的合法性,把检查操作放在处理流程的第一步,有问题就直接拒绝,对异常请求的处理代价是最小的。
检查操作进行以下参数检查,如下表所示:

每项检查遇到异常都会拒绝当前请求。
2、 处理pipeline请求
数据预处理(ingest)工作通过定义pipeline和processors实现。pipeline是一系列processors的定义,processors按照声明的顺序执行。
如果Index或Bulk请求中指定了pipeline参数,则先使用相应的pipeline进行处理。如果本节点不具备预处理资格,则将请求随机转发到其他具备预处理资格的节点。
3、 自动创建索引
如果配置为允许自动创建索引(默认允许),则计算请求中涉及的索引,可能有多个,其中有哪些索引是不存在的,然后创建它。如果部分索引创建失败,则涉及创建失败索引的请求被标记为失败。其他索引正常执行写流程。
创建索引请求被发送到Master节点,待收到全部创建请求的Response(无论成功还是失败的)之后,才进入下一个流程。Master节点什么时候返回Response?在Master节点执行完创建索引流程,将新的clusterState发布完毕才会返回。那什么才算发布完毕呢?默认情况下,Master发布clusterState的Request收到半数以上的节点Response,认为发
布成功。负责写数据的节点会先执行一遍内容路由的过程以处理没有收到最新clusterState的情况。
4、 对请求的预先处理
这里不同于对数据的预处理,对请求的预先处理只是检查参数、自动生成id、处理routing等。
由于上一步可能有创建索引操作,所以在此先获取最新集群状态信息。然后遍历所有请求,从集群状态中获取对应索引的元信息,检查mapping、routing、id等信息。如果id不存在,则生成一个UUID作为文档id。
5、检测集群状态
协调节点在开始处理时会先检测集群状态,若集群异常则取消写入。例如,Master节点不存在,会阻塞等待Master节点直至超时。
因此索引为Red时,如果Master节点存在,则数据可以写到正常shard,Master节点不存在,协调节点会阻塞等待或取消写入。
6、 内容路由,构建基于shard的请求
将用户的 bulkRequest 重新组织为基于 shard 的请求列表。例如,原始用户请求可能有10个写操作,如果这些文档的主分片都属于同一个,则写请求被合并为1个。所以这里本质上是合并请求的过程。此处尚未确定主分片节点。
基于shard的请求结构如下:
Map> requestsByShard = new HashMap<>();
根据路由算法计算某文档属于哪个分片。遍历所有的用户请求,重新封装后添加到上述map结构。
ShardId类的主要结构如下,shard编号是从0开始递增的序号:

7、 路由算法
路由算法就是根据routing和文档id计算目标shardid的过程。
一般情况下,路由计算方式为下面的公式:
shard_num = hash(_routing) % num_primary_shards
默认情况下,_routing值就是文档id。
ES使用随机id和Hash算法来确保文档均匀地分配给分片。当使用自定义id或routing时, id 或 routing 值可能不够随机,造成数据倾斜,部分分片过大。在这种情况下,可以使用index.routing_partition_size 配置来减少倾斜的风险。routing_partition_size 越大,数据的分布越均匀。
在设置了index.routing_partition_size的情况下,计算公式为:
shard_num=(hash(_routing)+hash(_id)%routing_partition_size)%num_primary_shards
也就是说,_routing字段用于计算索引中的一组分片,然后使用_id来选择该组内的分片。
index.routing_partition_size取值应具有大于1且小于index.number_of_shards的值。
8、 转发请求并等待响应
遍历所有需要写的 shard,将位于某个 shard 的请求封装为BulkShardRequest 类,调用TransportShardBulkAction#execute执行发送,在listener中等待响应,每个响应也是以shard为单位的。如果某个shard的响应中部分doc写失败了,则将异常信息填充到Response中,整体请求做成功处理。
待收到所有响应后(无论成功还是失败的),回复给客户端。
转发前先获取最新集群状态,根据集群状态中的内容路由表找到目的shard所在的主分片,如果主分片不在本机,则转发到相应的节点,否则在本地执行。
4.2 主分片节点流程
执行本流程的线程池:bulk。
主分片所在节点负责在本地写主分片,写成功后,转发写副本片请求,等待响应,回复协调节点。
1、 检查请求
主分片所在节点收到协调节点发来的请求后也是先做了校验工作,主要检测要写的是否是主分片,AllocationId(后续章节会介绍)是否符合预期,索引是否处于关闭状态等。
2、 是否延迟执行
判断请求是否需要延迟执行,如果需要延迟则放入队列,否则继续下面的流程。
3、 判断主分片是否已经发生迁移
如果已经发生迁移,则转发请求到迁移的节点。
4、 检测写一致性
在开始写之前,检测本次写操作涉及的shard,活跃shard数量是否足够,不足则不执行写入。默认为1,只要主分片可用就执行写入。
5、 写Lucene和事务日志
遍历请求,处理动态更新字段映射,然后调用InternalEngine#index逐条对doc进行索引。
Engine封装了Lucene和translog的调用,对外提供读写接口。
在写入Lucene之前,先生成Sequence Number和Version。这些都是在InternalEngine类中实现的。Sequence Number每次递增1,Version根据当前doc的最大版本加1。
索引过程为先写Lucene,后写translog。
因为Lucene写入时对数据有检查,写操作可能会失败。如果先写translog,写入Lucene 时失败,则还需要对translog进行回滚处理。
6、flush translog
根据配置的translog flush策略进行刷盘控制,定时或立即刷盘。
7. 写副分片
现在已经为要写的副本shard准备了一个列表,循环处理每个shard,跳过unassigned状态的shard,向目标节点发送请求,等待响应。这个过程是异步并行的。
转发请求时会将SequenceID、PrimaryTerm、GlobalCheckPoint、version等传递给副分片。
在等待Response的过程中,本节点发出了多少个Request,就要等待多少个Response。无论这些Response是成功的还是失败的,直到超时。
收集到全部的Response后,执行finish()。给协调节点返回消息,告知其哪些成功、哪些失败了。
8、处理副分片写失败情况
主分片所在节点将发送一个shardFailed请求给Master。
向Master发送shardFailed请求:
sendShardAction(SHARD_FAILED_ACTION_NAME, currentState,shardEntry, listener);
然后Master会更新集群状态,在新的集群状态中,这个shard将:
- 从in_sync_allocations列表中删除;
- 在routing_table的shard列表中将state由STARTED更改为UNASSIGNED;
- 添加到routingNodes的unassignedShards列表。
4.3 副分片节点流程
执行本流程的线程池:bulk。
执行与主分片基本相同的写doc过程,写完毕后回复主分片节点。
在副分片的写入过程中,参数检查的实现与主分片略有不同,最终都调用 IndexShardOperationPermits#acquire判断是否需要delay,继续后面的写流程。
5、I/O异常处理
在一个shard上执行的一些操作可能会产生I/O异常之类的情况。一个shard上的CRUD等操作在ES里由一个Engine对象封装,在Engine处理过程中,部分操作产生的部分异常ES会认为有必要关闭此Engine,上报Master。例如,系统I/O层面的写入失败,这可能意味着磁盘损坏。
对Engine异常的捕获目前主要通过IOException实现。例如,索引文档过程中的异常处理:

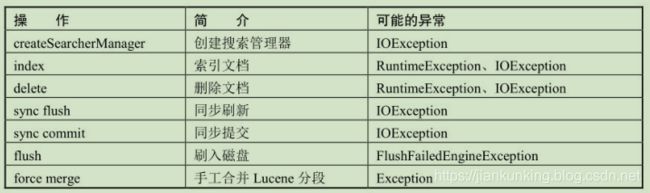
Engine类中的maybeFailEngine()负责检查是否应当关闭引擎failEngine()。
可能会触发maybeFailEngine()的操作如下表所示:
5.1 Engine关闭过程
将Lucene标记为异常,关闭shard,然后汇报给Master。
5.2 Master的对应处理
收到节点的SHARD_FAILED_ACTION_NAME消息后,Master通过reroute将失败的shard通过reroute迁移到新的节点,并更新集群状态。
5.3 异常流程总结
- 如果请求在协调节点的路由阶段失败,则会等待集群状态更新,拿到更新后,进行重试,如果再次失败,则仍旧等集群状态更新,直到超时1分钟为止。超时后仍失败则进行整体请求失败处理。
- 在主分片写入过程中,写入是阻塞的。只有写入成功,才会发起写副本请求。如果主shard写失败,则整个请求被认为处理失败。如果有部分副本写失败,则整个请求被认为处理成功。
- 无论主分片还是副分片,当写一个doc失败时,集群不会重试,而是关闭本地shard,然后向Master汇报,删除是以shard为单位的。
6、系统特性
ES本身也是一个分布式存储系统,如同其他分布式系统一样,我们经常关注的一些特性如下。
- 数据可靠性:通过分片副本和事务日志机制保障数据安全。
- 服务可用性:在可用性和一致性的取舍方面,默认情况下 ES 更倾向于可用性,只要主分片可用即可执行写入操作。
- 一致性:笔者认为是弱一致性。只要主分片写成功,数据就可能被读取。因此读取操作在主分片和副分片上可能会得到不同结果。
- 原子性:索引的读写、别名更新是原子操作,不会出现中间状态。但bulk不是原子操作,不能用来实现事务。
- 扩展性:主副分片都可以承担读请求,分担系统负载。
7、思考
分析完写入流程后,也许读者已经意识到了这个过程的一些缺点:
- 副分片写入过程需要重新生成索引,不能单纯复制数据,浪费计算能力,影响入库速度。
- 磁盘管理能力较差,对坏盘检查和容忍性比HDFS差不少。例如,在配置多磁盘路径的情况下,有一块坏盘就无法启动节点。
本文整理自:《Elasticsearch源码解析与优化实战》
个人微信公众号:

作者:jiankunking 出处:http://blog.csdn.net/jiankunking