ElasticSearch跨集群查询-构建千亿级日志分析系统
ElasticSearch集群可以处理上PB的数据,集群规模可以成百上千,但要驾驭这么大规模的集群前我们需要对ElasticSearch足够了解,即便使用目前流行的云服务我们也要对ElasticSearch有一定的研究,才能更好的满足我们的业务。本篇主要讲跨集群查询。
1、跨集群查询
跨集群查询允许你的请求查询多个集群的数据,这个特性帮助我们更好的设计我们的架构。
分布式系统或微服务里将系统分为多个模块,模块A由一个团队,模块B由一个团队负责,模块C由一个团队负责,通常各个模块只查询各自的日志,但有些问题涉及多个模块时会查到多个模块的日志,这时跨集群查询刚好可以解决这类问题,对架构来说我们将模块A、模块B、模块C的日志存储在单独的集群里。
这样可以避免集群之间相互的干扰,模块A的日志量大只会影响集群A的写入,做到分而治之。
远程集群配置:
如下命令配置三个远程集群,”cluster_one“、”cluster_two“、”cluster_three“,在Kibana配置的默认集群上执行如下命令,执行后可在Kibana配置访问这些集群的数据。
PUT _cluster/settings
{
"persistent": {
"cluster": {
"remote": {
"cluster_one": {
"seeds": [
"127.0.0.1:9300"
]
},
"cluster_two": {
"seeds": [
"127.0.0.1:9301"
]
},
"cluster_three": {
"seeds": [
"127.0.0.1:9302"
]
}
}
}
}
} 2、权限与网关设置
需要注意的是,三个集群之间的权限要打通,否则会出现拒绝访问的情况,Kibana配置的用户名在三个集群件要有同样的权限。远程群集连接通过配置远程群集并仅连接到该远程群集中有限数量的节点来工作。
每个远程集群都由一个名称和一个种子节点列表引用。注册远程群集时,将从其中一个种子节点检索其群集状态,并选择最多三个网关节点作为远程群集请求的一部分进行连接。
可以手动设置网关节点:
cluster.remote.node.attr.gateway: true
3、跨集群查询如何控制网络时延
因为跨集群搜索涉及向远程集群发送请求,所以任何网络延迟都会影响搜索速度。为了避免搜索速度慢,跨群集搜索提供了两个用于处理网络延迟的选项:
Minimize network roundtrips:
因为跨集群搜索涉及向远程集群发送请求,所以任何网络延迟都会影响搜索速度。为了避免搜索速度慢,跨集群搜索提供了两个处理网络延迟的选项:
默认情况下,Elasticsearch会减少远程集群之间的网络往返次数。这减少了网络延迟对搜索速度的影响。但是,Elasticsearch不能减少大型搜索请求的网络往返次数,例如包含滚动或内联查询的请求。
Minimize network roundtrips (最小化网络往返)的原理如下:
1) 当你向本地群集发送跨群集搜索请求时。集群中的协调节点接收并解析请求.
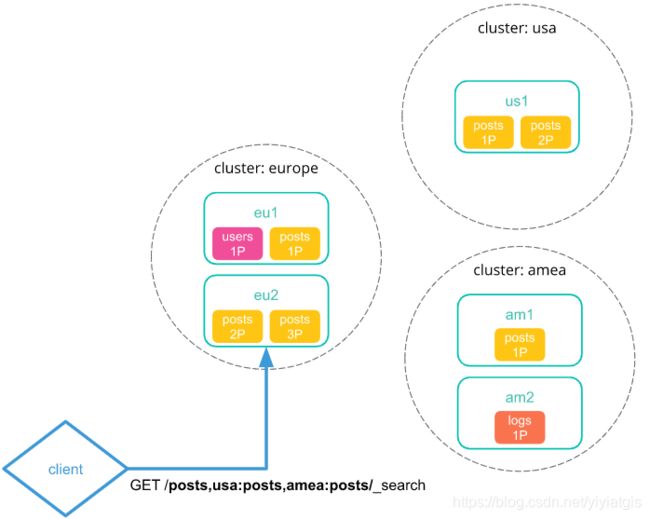
2) 协调节点向每个集群(包括本地集群)发送一个搜索请求。每个集群独立执行搜索请求,根据自身集群的级别设置来返回请求.
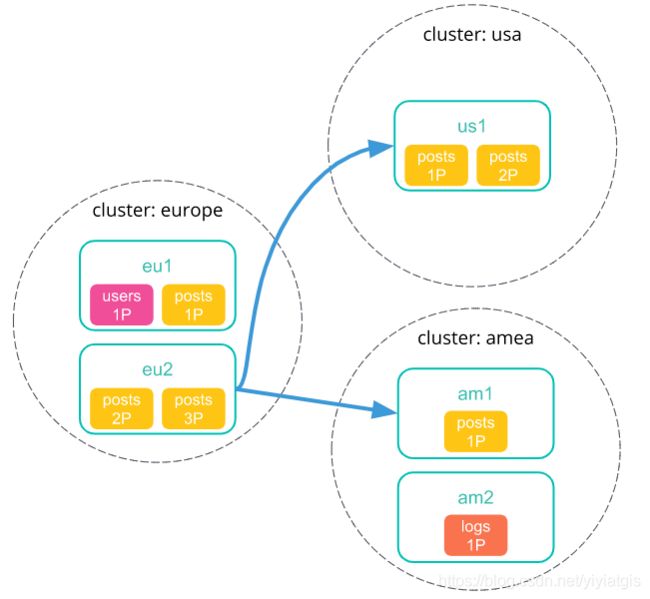
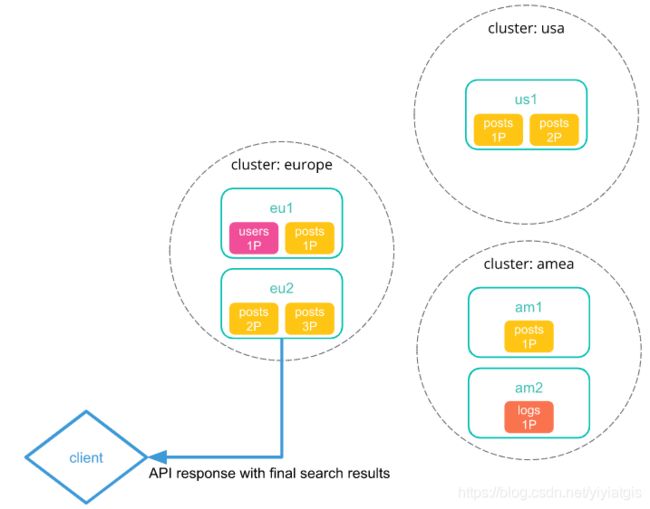
3) 每个远程集群将其搜索结果发送回协调节点.

4) 从每个集群收集结果后,协调节点在跨集群搜索响应中返回最终结果.
Don’t minimize network roundtrips:
对于包含滚动或内联查询的搜索请求,Elasticsearch向每个远程集群发送多个传出和传入请求。
也可以通过将ccs_minimize_roundtrips参数设置为false来选择此选项。虽然通常速度较慢,但这种方法对于低延迟的网络可能很有效
Don’t minimize network roundtrips(非最小化网络往返)原理如下:
1) 向本地群集发送跨群集搜索请求。集群中的协调节点接收并解析请求。
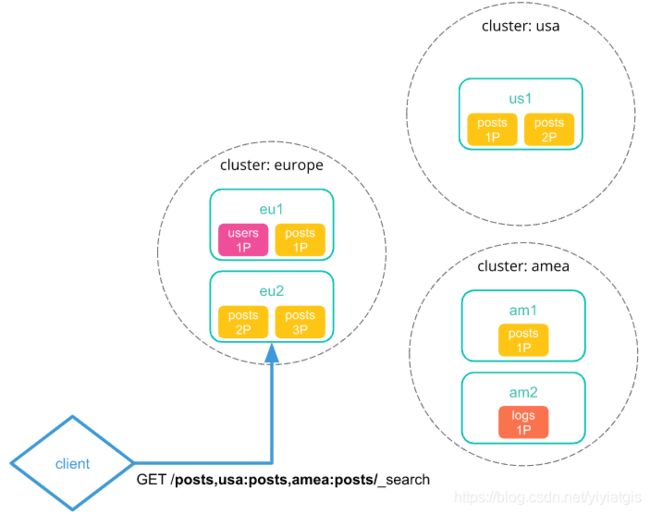
2) 协调节点向每个远程集群发送一个搜索碎片API请求。

3) 每个远程集群将其响应发送回协调节点。此响应包含有关跨群集搜索请求将要在其上执行的索引和碎片的信息。
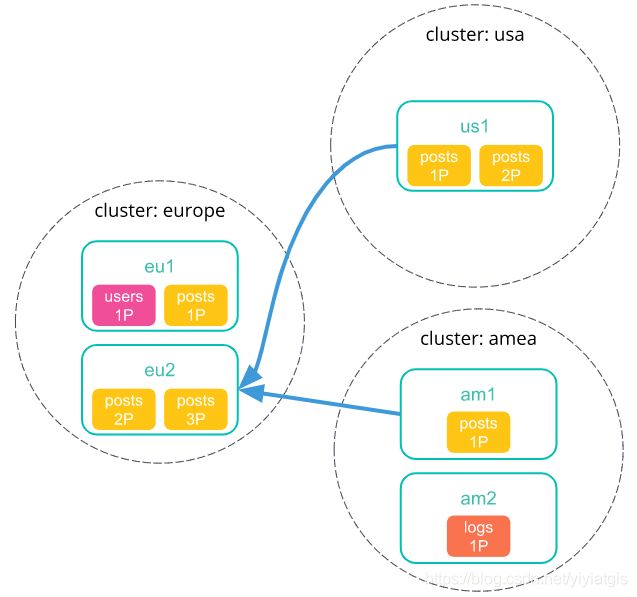
4) 协调节点向每个shard发送一个搜索请求,包括它自己集群中的那些shard。每个shard独立地执行搜索请求。

当网络往返不最小化时,将执行搜索,就像所有数据都在协调节点的集群中一样。ElasticSearch建议更新限制搜索的群集级别设置,例如action.search.shard_count.limit、pre_filter_shard_size和max_concurrent_shard_requests,以解决此问题。如果这些限制太低,搜索可能会被拒绝。
5) 每个shard将其搜索结果发送回协调节点。
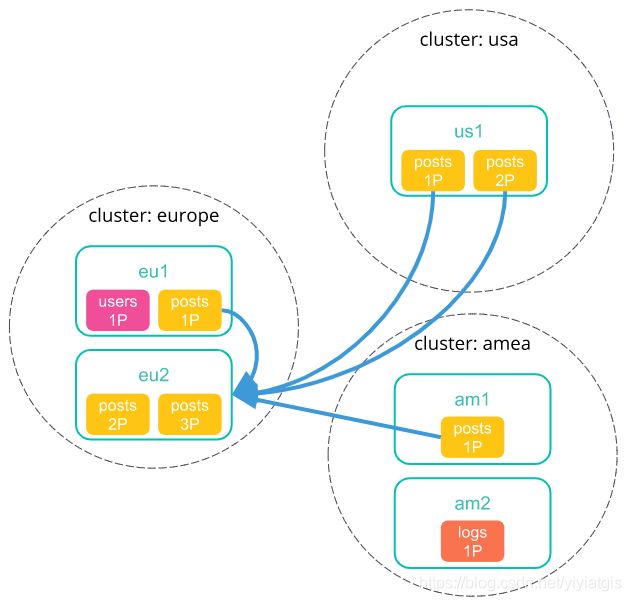
6) 从每个集群收集结果后,协调节点在跨集群搜索响应中返回最终结果。

由此可见非最小化网络往返会带来很大的网络开销,协调节点的压力也会变得很大,瓶颈会在协调节点。
因此对跨集群模式,我们要尽量避免进行滚动和内联查询。
滚动:
滚动类似于传统数据库的游标查询,用来便利单次请求的所有结果。为了使用滚动,初始搜索请求应该在查询字符串中指定scroll参数,
它告诉Elasticsearch它应该保持“搜索上下文”活动多长时间(参见保持搜索上下文活动),例如?滚动1分钟(m表示分钟,d表示天,h表示小时,s表示秒,ms表示毫秒,micros表示微秒,naos表示纳秒)。
关于滚动详细介绍:
https://www.elastic.co/guide/en/elasticsearch/reference/current/search-request-body.html#scroll-search-context
内联查询:
内联查询是Document类型的数据库提供的一种操作,如下例子comments.number 是一个内联查询的案例。
PUT test
{
"mappings": {
"properties": {
"comments": {
"type": "nested"
}
}
}
}
PUT test/_doc/1?refresh
{
"title": "Test title",
"comments": [
{
"author": "kimchy",
"number": 1
},
{
"author": "nik9000",
"number": 2
}
]
}
POST test/_search
{
"query": {
"nested": {
"path": "comments",
"query": {
"match": {"comments.number" : 2}
},
"inner_hits": {}
}
}
}关于内联查询的详细介绍参考如下链接:
https://www.elastic.co/guide/en/elasticsearch/reference/current/search-request-body.html#request-body-search-inner-hits
也可通过API进行跨集群查询,详细说明参考链接:
https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-cross-cluster-search.html
下篇文章重点介绍ElasticSearch集群的优化。
ElasticSearch 中文版的权威指南:
https://www.elastic.co/guide/cn/elasticsearch/guide/current/index.html
建议大家先阅读中文版本的指南,中文指南是基于2.X进行的介绍,新特性虽然没有写进去,但是对基础的概念和设计理念还是做了很详细的说明。
ElasticSearch GitHub代码地址:
https://github.com/elastic/elasticsearch
ElasticSearch Contributing 社区地址:
https://github.com/elastic/elasticsearch/blob/master/CONTRIBUTING.md
中文社区:
https://elasticsearch.cn/
Apache Lucene官网:
https://lucene.apache.org/core/