【Linux内核数据结构】最为经典的链表list
很久之前研读过Linux的内核源码,看到其中的内核数据结构,对链表的实现叹为观止,是迄今为止我见过的最为经典的链表实现(不是数据内嵌到链表中,而是把链表内嵌到数据对象中)。现在再来回顾这个经典的数据结构。
链表代码在头文件
1、链表的初始化
struct list_head {
struct list_head *next, *prev;
};static inline void INIT_LIST_HEAD(struct list_head *list)
{
list->next = list;
list->prev = list;
}#define LIST_HEAD_INIT(name) { &(name), &(name) }
#define LIST_HEAD(name) \
struct list_head name = LIST_HEAD_INIT(name)struct list_head name = { &(name), &(name) }2、访问数据
这恐怕就是Linux内核数据结构链表的最难理解的地方了吧,前面说了,内核链表不同于普通链表的是,它是内嵌到数据对象中,这么说来,就是同类型的对象内部都嵌有这个链表,并且是通过这个链表穿针引线在一起,我们关心的是对象中的数据内容,那么究竟是如何通过对象内部的链表来访问其中的数据内容的呢?
#define list_entry(ptr, type, member) \
container_of(ptr, type, member)#define container_of(ptr, type, member) ({ \
const typeof(((type *)0)->member)*__mptr = (ptr); \
(type *)((char *)__mptr - offsetof(type, member));})#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER)#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER)所以该语句的功能是:得到TYPE类型对象中MEMBER成员的地址偏移量。
#define container_of(ptr, type, member) ({ \
const typeof(((type *)0)->member)*__mptr = (ptr); \
(type *)((char *)__mptr - offsetof(type, member));})说白了,就是定义一个member成员类型的指针变量,然后将ptr赋给它。
好,来看下一条语句:
先将__mptr强制转换为char*类型(因为char* 类型进行加减的话,加减量为sizeof(char)*offset,char占一个字节空间,这样指针加减的步长就是1个字节,实现加一减一。)实现地址的精确定位,如果不这样的话,假如原始数据类型是int,那么这减去offset,实际上就是减去sizeof(int *)*offset 的大小了。
所以整体意思就是:得到指向type的指针,已知成员的地址,然后减去这个成员相对于整个结构对象的地址偏移量,不就得到这个数据对象的地址么
最后看
#define list_entry(ptr, type, member) \
container_of(ptr, type, member)type->member,表明member是type中的成员,所以可以得知member是内嵌的链表,type则是对象指针,那么ptr是链表类型指针,并且是属于那个穿针引线的链表中的某一个链表节点,所有的对象结构都挂在ptr所在的链表上。
该宏定义可以返回ptr对应链表节点的对象的地址。关键是对应,找到的对象的地址是ptr这个链表所对应的那个对象的地址。ptr和member之间的关系就是,ptr是member类型的指针。
其实上面就是地址的强制转换,然后得到偏移量之类的,就是指针,而且上面有个特点,那就是跟结构体中的内存对齐无关。
这里额外补充一个关于指针方面的:
(*(void(*)())0)();先看最里面void(*)(),定义一个函数指针,无参无返回值,
(void(*)())0,将0强制转换为函数指针,这样0成了一个地址,而且是函数地址,就是说有个函数存在首地址为0 的一段区域内。
(*(void(*)())0),取0地址开始的一段内存里面的内容,其内容就是保存在该区域内的函数。
(*(void(*)())0)(); 调用该函数。
所以整个代码的意思就是:调用保存在0地址处的函数(初始化)。扯远了,论指针的重要性。
3、遍历链表(实际是得到指定链表节点对应的数据对象结构)
有了前面的定位某个结构地址,遍历就好办了。
得到第一个节点元素地址
#define list_first_entry(ptr, type, member) \
list_entry((ptr)->next, type, member)对象结构就是像下面这样挂载在链表上:
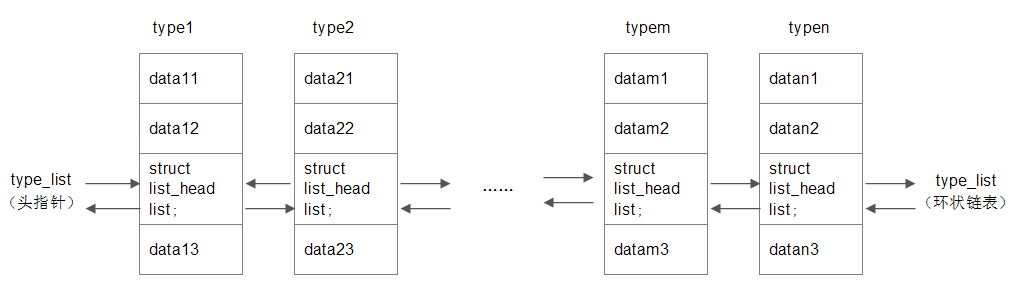
访问第一个对象就是:
type *type_first_ptr = list_first_entry(type_list, type, list);
/*
type_list为链表头指针,type为对象结构,list为type结构内的链表
*/#define list_for_each_entry(pos, head, member) \
for (pos = list_entry((head)->next, typeof(*pos), member); \
prefetch(pos->member.next), &pos->member != (head); \
pos = list_entry(pos->member.next, typeof(*pos), member))
/*
实际上就是一个for循环,循环内部由用户自己根据需要定义
初始条件:pos = list_entry((head)->next, typeof(*pos), member); pos为第一个对象地址
终止条件:&pos->member != (head);pos的链表成员不为头指针,环状指针的遍历终止判断
递增状态:pos = list_entry(pos->member.next, typeof(*pos), member) pos为下一个对象地址
所以pos就把挂载在链表上的所有对象都给遍历完了。至于访问对象内的数据成员,有多少个,用来干嘛用,则由用户
根据自己需求来定义了。
*/static inline void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next)
{
next->prev = new;
new->next = next;
new->prev = prev;
prev->next = new;
}//head是头指针
//头节点后添加元素,相当于添加头节点,可实现栈的添加元素
//new添加到head之后,head->next之前
static inline void list_add(struct list_head *new, struct list_head *head)
{
__list_add(new, head, head->next);
}
//头节点前添加元素,因为是环状链表所以相当于添加尾节点,可实现队列的添加元素
//new添加到head->prev之后,head之前
static inline void list_add_tail(struct list_head *new, struct list_head *head)
{
__list_add(new, head->prev, head);
}//prev和next两个链表指针构成双向链表关系
static inline void __list_del(struct list_head * prev, struct list_head * next)
{
next->prev = prev;
prev->next = next;
}
//删除指定元素,这是一种安全删除方法,最后添加了初始化
static inline void list_del_init(struct list_head *entry)
{
//删除entry节点
__list_del(entry->prev, entry->next);
//entry节点初始化,是该节点形成一个只有entry元素的双向链表
INIT_LIST_HEAD(entry);
}//调整指针,使new的前后指针指向old的前后,反过来old的前后指针也指向new
//就是双向链表的指针调整
static inline void list_replace(struct list_head *old,
struct list_head *new)
{
new->next = old->next;
new->next->prev = new;
new->prev = old->prev;
new->prev->next = new;
}
//替换元素,最后将old初始化一下,不然old还是指向原来的两个前后节点(虽然人家不指向他)
static inline void list_replace_init(struct list_head *old,
struct list_head *new)
{
list_replace(old, new);
INIT_LIST_HEAD(old);
}//移动指定元素list到链表的头部
static inline void list_move(struct list_head *list, struct list_head *head)
{
__list_del(list->prev, list->next);//删除list元素
list_add(list, head);//将list节点添加到head头节点
}
/**
* list_move_tail - delete from one list and add as another's tail
* @list: the entry to move
* @head: the head that will follow our entry
*/
//移动指定元素list到链表的尾部
static inline void list_move_tail(struct list_head *list,
struct list_head *head)
{
__list_del(list->prev, list->next);
list_add_tail(list, head);
}list_add(&(newobj.list), &(type_list.list));