"Batch,Batch,Batch":What does it really mean?
作者:i_dovelemon
日期:2016 / 06 / 18
来源:CSDN
主题:batch, drawl call, performance
引言
最近,有个问题为什么在3D图形编程中,总是以draw call的数量来估测性能,draw call到底做了什么?它与GPU,CPU到底是什么关系?带着这个疑问,上网搜索了下相关的文章,发现在 Stackoverflow上有关于这个的讨论。在详细阅读了他们的讨论之后,发现有人给出了Nvidia的一篇文章“"Batch,Batch,Batch":What does it really mean?”。本篇文章将主要记录一些对该篇文章的理解。正如作者提出的那样,这篇文章很老,是否与现在的实际情况有出入,不得而知,但是整体上能够给我一个对draw call的初步了解。好了,废话不多说,开始正文吧!!!
Let's go

图1

图2
开篇,文章中就提出了Batch是什么,每当我们在API中调用DrawPrimitive之类的函数的时候,实际上就是向GPU提交三角形(一般来说)数据,一个Batch,具有同样的渲染状态,同样的纹理,同样的Transform。

图3
这里,他提出了一个问题,游戏绘制1百万个物体,而每一个物体具有10个三角形的性能和绘制10个物体,每一个物体具有1百万个三角形,哪个性能好,哪个速度更快?从书上或者其他途径,我们都了解后面一种实际上效率高。但是高的原因是什么,文中提出了一些常见的错误猜测:
(1)在GPU上进行状态切换不够快(错)
(2)在GPU上组织建立三角形很占用资源(错)
(3)内核中传输数据很慢(错)
看完这个之后,我就知道以前我的理解原来是错误的。除了上面的错误猜测之外,还提出了疑问“未来的GPU能够解决在两种绘制情况下都同样高效绘制的问题吗?”

图4
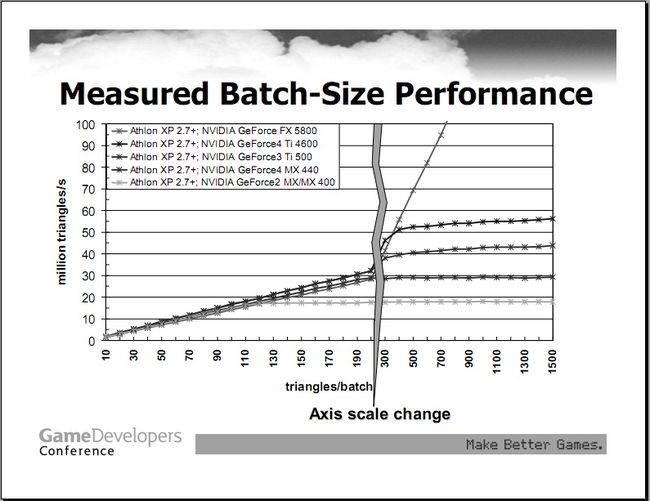
图5
作者说,不要进行猜测,我们实际编写代码,测试看看,答案就知道了。通过编写一个测试代码,仅仅绘制一些非常简单的三角形数据,没有光照,没有纹理,去掉任何不必要的开销,仅仅提交batch。图5中,给出了测量的结果。从中,我们能够了解一些基本参数,横轴是triangles/batch,表示每一个batch中所容纳的triangles数量。纵轴是million triangles/s,表示1s能够绘制的百万级三角形数据。不同的GPU,相同的CPU,在具有不同尺寸的batch时,绘制的效率明显不同,并且不是我们想象中的线性关系,而是在某个点的时候,突变,绘制瞬间提高。
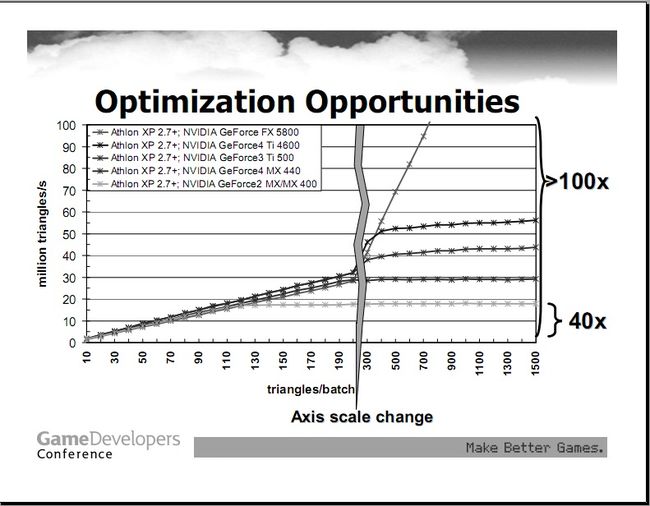
图6
据此,我们能够得出一些优化的方案,选择合适batch尺寸,能够大大的提升性能。
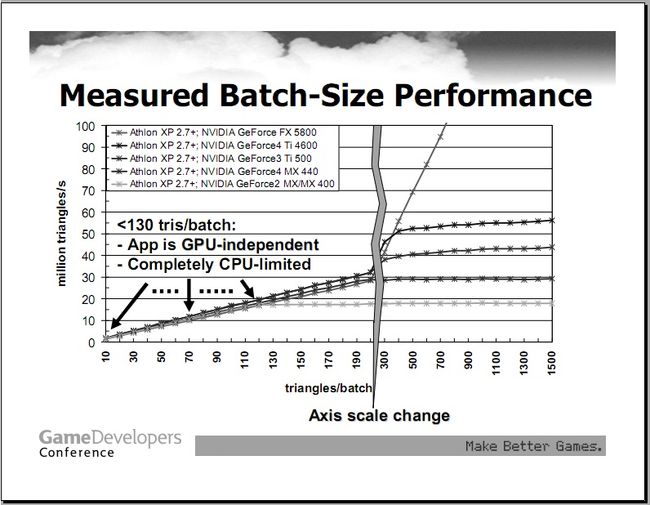
图7
图7给出了一个结论,从中可以看出,当batch的尺寸小于130的时候,GPU其实远没有满载,效率低下的原因在CPU这边,CPU没有办法提交更多的batch让GPU进行处理。

图8
从前面的实验,以及得出的结果中可以看到,整个绘制的效率瓶颈在CPU这边,而不是在GPU。也就是说,CPU没有处理足够多的数据,是绘制效率瓶颈的直接原因,而不是因为我们的batch尺寸的关系。下面,我们来统计下每一秒,能够提交的batch数量。

图9

图10

图11
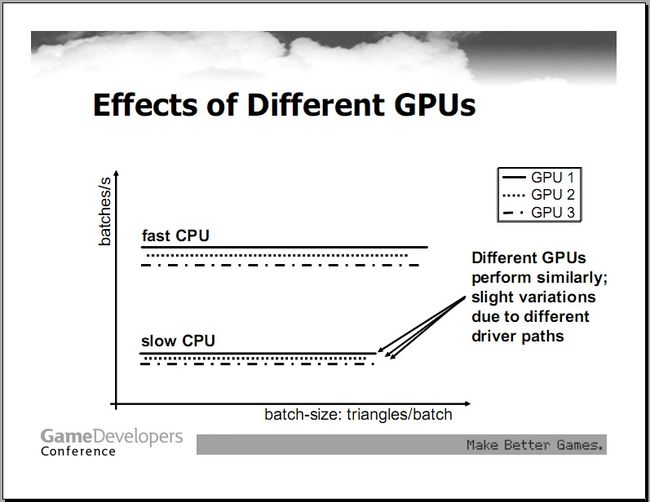
图12

图13
从上面的统计图中能够得出,同一个CPU在不同的GPU,不同的batch尺寸下,每秒能够提交的batch数量实际上是恒定的。不同的CPU每秒提交的batch数不相同。也就是说整个系统每秒能够绘制的batch数,只和CPU有关,而和batch的尺寸,GPU的种类等等无关。

图14
从前面的分析,我们就能够知道,瓶颈真的完完全全在CPU这端。CPU一直在忙着向GPU提交batch。

图15
这张图给出了一个CPU在处理batch尺寸在2个三角形时的CPU资源分布,78%的资源被驱动占用了,另外的14%被D3D占用,剩下的东西被其他部分占用。驱动实际上在每一次的draw和状态改变的时候,都进行很少的工作,但是如果工作的很频繁,这个部分也会占用非常大的资源。图形驱动一直在被优化,但是不管怎么优化,都需要耗费十分多的资源。对CPU来说,CPU耗费的周期与batch数的提交数量是呈现线性关系的。CPU处理batch的时间复杂度很难降低到常量级。
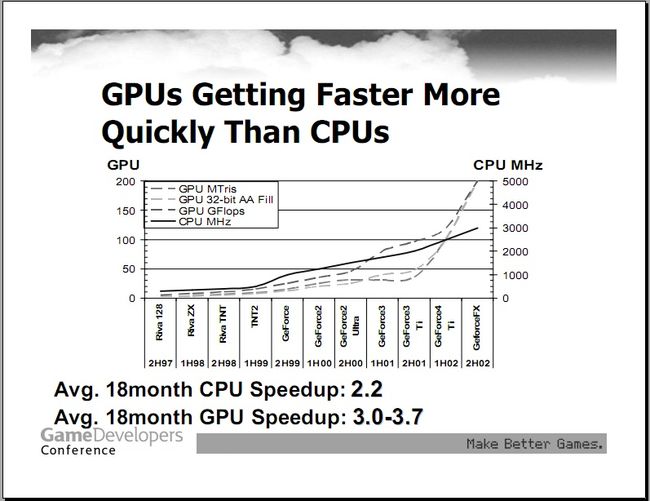
图16
前面说过,整个绘制系统的瓶颈在CPU这端,而不在GPU。从上图可以看出,GPU的本身的计算速度和发展速度都要比CPU高的多。如果你的batch尺寸很小,而CPU提交该batch在驱动上花费的时间不会减少,GPU速度又过快的处理了这些数据,就会导致GPU处在空闲状态,整体每秒绘制的三角形当然就会减少很多。如果你的游戏需要的三角形数目是固定的,那么只有花费更多的时间才能够绘制完毕,自然就导致了帧率下降。所以,为了不让CPU在驱动上面花的时间浪费掉,我们尽量给每一个batch提供更多的三角形数据,由于GPU更快,不会导致CPU等待GPU处理完毕数据的情况(本实验而言,如果有很复杂的shader计算,也会出现这种情况),那么整个系统能够绘制的三角形数量自然就会提高好多,游戏场景就能够更快的被绘制出来。

图17
由于CPU提交batch所花费的时间主要在驱动和D3D的Runtime上面,所以,当我们优化了驱动和D3D Runtime,提高了CPU的计算,我们每秒能够提交的batch数量自然就会提高好多。GPU实际上处理最终传递过来的三角形数据,也就是说batch的尺寸实际上影响的是GPU,当GPU速度提升了之后,我们自然就能够使用更大尺寸的batch了。同时还要明白一点,GPU的速度远远的高于CPU,这也是为什么batch的尺寸不会影响到CPU的原因所在。

图18

图19
所以Batch的尺寸和性能实际上没有太大的关系。我们在编写游戏的时候,也不可能将所有的物体都用很大的batch组织起来,少量的小尺寸的batch,也不会影响到什么。batch尺寸的大小应该依据游戏最终需要绘制场景的三角形数量,每帧提交的batch数目以及GPU的速度,来合理的设置它。而每帧提交的batch数目依赖与CPU的速度,目标帧率,以及我们给提交batch所预留的CPU周期。

图20
那么,当我们知道了一个CPU满载的时候每秒能够提交的Batch数N,以及预留的CPU资源比例R,和目标FPS,F,我们就能够通过公式
X = N * R / F
得到每一帧应该提交的batch数量。并且,我们就能够依此设计我们的游戏,合理安排数据,提交合适大小的batch,完成场景的绘制。

图21

图22

图23
那么Batch的尺寸该怎么决定了,这要依赖与我们自己的决定。如果GPU还有空闲的资源,那么我们可以通过增大batch的尺寸来提供更平滑,更精细的场景,人物模型。如果模型以及场景以及足够,那么我们可以将空闲的GPU资源用于提升shader,可以进行更加精细的shader计算,以得出更真实,更有吸引力的场景。

图24
依据前面的计算公式,我们能够得出在本实验环境下,每一帧能够提交的batch数量在300左右。一般来说,一个batch即是游戏中的一个物体,那么每一帧就只能花300个物体,还是在不考虑复杂效果的情况下,这很难让我们做出好玩的游戏内容出来。那么,如果想要花很多的物体,我们就需要借助与GPU将不同物体的batch包装成一个batch,然后提交,以减少batch数量。

图25
那么,是什么阻止了我们将一个多个物理打包成一个batch了:纹理。从前面我们知道,一个batch,它的渲染状态要是一致的,如果不同的物理具有不同的纹理,那么通常手段是没有办法把它们放在一个batch里面进行绘制。为此,我们可以想出其他具有技巧的方法,传递更多的纹理,同时能够让不同物理的三角形能够识别各自的纹理。比如说,对于顶点数据来说,通常位置是XYZW,而W总是为1,那么我们是不是就可以在W中保存一个该顶点所对应的纹理索引了,然后将所有的纹理都传递到纹理单元中去(注:这只是我猜想的一种方案,实际可能不会成功,因为顶点数据会进行插值,从而导致在Pixel shader中,w也可能被改变,在此仅仅是说明能够通过某些技巧来实现)。除此之外,我们还能够将不同物体的纹理,打包放在一个贴图中,然后只要给这些顶点数据赋值正确的纹理坐标就能够实现一次batch提交,而描绘所有的物体。这种方法的确有效,而且经常被使用。比如人物模型的贴图,通常都会放在一个纹理里面,然后人物的不同部分分别对应不同的纹理坐标,就能够通过一次draw call绘制完毕整个模型。

图26
另外一个会破坏batch无法合并的东西,就是transform矩阵。同样的,我们也能够通过技巧将它保存,然后通过一次draw call绘制N个物体。

图27
材质也会导致batch无法合并。更多关于这方面的优化手段,请自行搜索,或者在GPU GEMS中的Graphics Pipeline Performace一章中能够找到你想要的答案。可能有人会觉得这些优化手段不是会导致GPU变得非常慢吗?的确,这些操作会占用GPU的资源,但是正如我们前面所知道的那样,GPU的速度远远高于CPU,大部分时候都没有让它满载,我们的任务就是要让GPU满负荷的运行,从而实现更加快速的绘制。
总结
Batch指得就是一次draw call调用。GPU的速度要远远的高于CPU,绘制的瓶颈往往是CPU没有提交足够大的batch。CPU耗费了大量的时间在驱动和3D Runtime上面,而这些耗费和Batch的尺寸并没有直接关系,为了绘制更多的三角形,想尽所有的办法整合batch,绘制更多的物体。
希望能够通过本篇文章,了解到3D游戏编程优化的基础知识,同时也希望能够让更多的人喜欢上游戏开发,能够做出更加优秀的作品!