Win10安装YOLOv3.0
本文主要参考这个网址,本文是对这个网址所遇到错误的总结,如有侵权,请与我联系:
https://zhuanlan.zhihu.com/p/54795847?tdsourcetag=s_pcqq_aiomsg
0.
安装之前,你要知道tensorflow的安装环境,见官网:
https://tensorflow.google.cn/install/source_windows#install_visual_c_build_tools_2015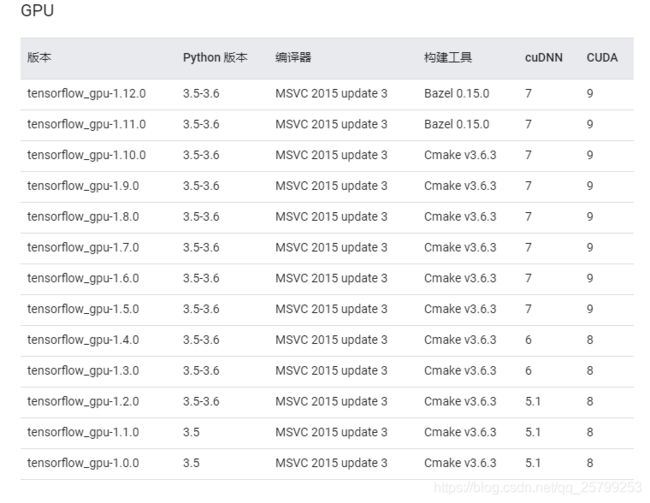
MSVC+CUDA+cuDNN+python的版本都要正确
0.1 MSVC是VS附带的软件包:Microsoft Visual C++ 2015 Redistributable和Microsoft 生成工具 2015,tensorflow官网上说可以不用下载VS可以直接单独下载它,但是你最好还是安装一个VisualStudio2015,VS会附带这两个东西。我尝试了很多次只安装Microsoft Visual C++ 2015 Redistributable和Microsoft 生成工具 2015,结果CUDA装不上。
VS2015免费版的下载可以去这个微信公众号找:软件安装管家
tensorflow官网里有单独的MSVC2015的下载地址,我这里也把它给出吧:
安装 Visual C++ 生成工具 2015。此软件包随附在 Visual Studio 2015 中,但可以单独安装:
- 转到 Visual Studio 下载页面,
- 选择“可再发行组件和生成工具”,
- 下载并安装:
- Microsoft Visual C++ 2015 Redistributable 更新 3
- Microsoft 生成工具 2015 更新 3
这里可以看到:

选择x64的,x64是给64位的系统用的,x86是给32位系统用的。
0.2 关于CUDA的安装可以参考这个网址里的CUDA安装方法:
https://zhuanlan.zhihu.com/p/37086409
关于cuDNN的安装你可以参考这个网址的安装方法:
https://blog.csdn.net/angzhangzhang123/article/details/79637346
0.3 至于python我是下载了一个anaconda3,它的默认python版本是3.5,然后我就用Anaconda Prompt当cmd用
1.
最开始的下载,
https://github.com/YunYang1994/tensorflow-yolov3.git
2.
第2步安装依赖项,
cd tensorflow-yolov3
pip install -r ./docs/requirements.txt命令行下(本人用的是Anaconda Prompt)输入:pip install -r ./docs/requirements.txt的时候遇到很多错误
(1)首先是你的命令行要到tensorflow-yolov3-master这个目录,
(2)然后要保证你的命令行下的python版本在3.5到3.6之间(直接输入python查看版本),同时pip的依赖的python版本也一样
(查看pip依赖哪个python版本看不了,但是如果你输入第二步的安装requirement命令,如果它显示py2.7要被淘汰了之类的信息
那么你的pip依赖于py2.7)
当你的计算机有2.7又有3.5那你可以转换版本,但是pip依赖的python不会变,转换使用其它python版本的pip这个操作可能不
好弄,你的pip依赖的python可能是2.7的,所以你还是卸载了python2.7比较好。
我之前试过在Anaconda Prompt的tensorflow环境下安装这个requirement里的tensorflow,因为Anaconda很容易转换
python版本,但安不了,还有requirement里面的其他的包,只是导致了我的环境越来越复杂,最后什么都安不了,之后
我索性卸载了Anaconda,重装了初始python版本为3.5的Anaconda,然后在这个环境中用Anaconda Prompt安装requirement
一举成功。所以要简单地配置下载这个requirement,当然你也可以用cmd的命令行来安装。但必须符合要求以上两点要求。
(3)这里再啰嗦一句,这个requirement.txt文件里安装的tensorflow版本是GPU,1.11.0,它对你的显卡的算力,也就是compute capability的要求是3.7以上,我的Tesla k40m的算力是3.5,每次运行demo时都不能使用GPU,都自动跑的CPU版本,所以我卸载了这个版本,换了更低的版本。关于你的显卡的compute capability可以在官网上搜。
pip uninstall tensorflow-gpu==1.11.0
pip install tensorflow-gpu==1.10.0运行这个代码看看,你的tensorflow是在GPU还是CPU上跑:
import tensorflow as tf
a = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[2, 3], name='a')
b = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[3, 2], name='b')
c = tf.matmul(a, b)
sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))
print (sess.run(c))
sess.close() 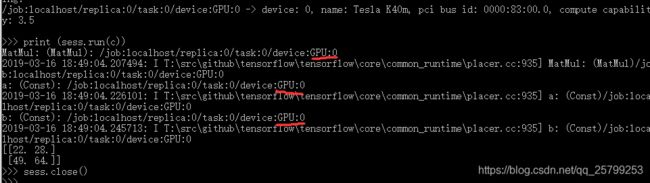
可以看到我的是在GPU上跑的。
3.
第3步把加载好的COCO权重导出为TF checkpoint (yolov3.ckpt) 和 frozen graph (yolov3_gpu_nms.pb) 。
关于这一步,它这一句话只是解释说明你现在做的事,并不是指导你去做什么,你照着它下面的指示做就好了,不用管这句话。
如果你没有yolov3.weights的话,去下载,然后放到./checkpoint目录下。下载地址是:
https://github.com/YunYang1994/tensorflow-yolov3/releases/download/v1.0/yolov3.weights
接着anaconda prompt下或cmd下输入命令:
python convert_weight.py --convert --freeze4.
第4步:然后,./checkpoint目录下就会出现一些.pb文件。现在可以跑Demo脚本了:
python nms_demo.py
python video_demo.py # if use camera, set video_path = 0输入第一个命令会报错:ModuleNotFoundError: No module named 'cv2',则输入命令安装opencv2:
pip install opencv-python
输入第二个命令时,你可能会报错:python video_demo.py # if use camera, set video_path = 0
因为你的电脑没有摄像头,这样的话可以不用管。如果你的电脑有摄像头的话,这个命令就是开启你的摄像头实时识别现实中的物体
假如你在使用摄像头时出现错误:
Traceback (most recent call last):
File "video_demo.py", line 29, in
["Placeholder:0", "concat_9:0", "mul_6:0"])
File "D:\tensorflow-yolov3-master\core\utils.py", line 220, in read_pb_return_tensors
return_elements=return_elements)
File "D:\Pro2\Anaconda3\lib\site-packages\tensorflow\python\framework\importer.py", line 283, in import_graph_def
raise ValueError('No op named %s in defined operations.' % node.op)
ValueError: No op named GatherV2 in defined operations.
说明你的tensorflow版本太低,需升级,如果出现了其他的错误,检查你的video_demo.py文件里使用的那个nms.pb文件是cpu还是gpu版本的,是否与你的tensorflow-cpu或gpu相匹配。
5.
到了这一步,如果你要弄VOC格式的数据集,你可以不往下看了,可以转到:
https://blog.csdn.net/qq_25799253/article/details/88777545
如果你要弄COCO格式的数据集:
官网:
http://cocodataset.org/
5.1下载的数据图像集是那个COCO官网的--》Dataset下的--》Download--》Images的--》2017 Train images [118K/18GB]
但是官网上的很慢,可以去这个网址下载:
https://blog.csdn.net/u014734886/article/details/78830713
或者在PanDownload里搜索train2017(不过很慢)强烈推荐用迅雷下载,因为下载到一半突然网络错误是很痛苦的。我就
踩了不用迅雷的坑。
5.2下载的标注集是COCO官网的--》Dataset下的--》Download--》Images的--》2017 Train/Val annotations [241MB]
6.
然后,就要从数据集里提取一些有用的信息了,比如边界框,拿这些信息生成你自己的.txt文件。
python core/extract_coco.py --dataset_info_path ./data/train_data/COCO/train2017.txt
在这个目录里用的cmd命令行窗口里输入上面那个命令后,报错:
python: can't open file 'core/extract_coco.py': [Errno 2] No such file or directory
于是我去scipts这个目录下找到这个缺失的文件,并把它放到指定的core目录下。
7.
根据教程输入命令:
python core/extract_coco.py --dataset_info_path ./data/train_data/COCO/train2017.txt错误:
File "core/extract_coco.py", line 30, in main
labels = json.load(open(flags.json_path, encoding='utf-8'))
FileNotFoundError: [Errno 2] No such file or directory: '/home/yang/test/COCO/annotations/instances_train2017.json
应该是这个文件里的路径不对,我去改一下路径。

可以看到源文件中有三个路径对于我的文件目录都要改
我的三个路径:
8.
生成那个train2017.txt文件后,
接下来,要把图像数据集转成.tfrecord,就是用二进制来保存数据。
python core/convert_tfrecord.py --dataset ./data/train_data/COCO/train2017.txt --tfrecord_path_prefix ./data/train_data/COCO/tfrecords/coco --num_tfrecords 100这一步会报错:
convert_tfrecord.py: error: unrecognized arguments: --num_tfrecords 100
于是我把这个--num_tfrecords 100配置参数去掉了,因为报错的这个convert_tfrecord.py文件里:

它的参数中

不包括这个--num_tfrecords
继续输入8.开头的那个命令,继续报错:
compat.as_bytes(path), compat.as_bytes(compression_type), status)
File "E:\Anaconda3-5.2.0-Windows-x86_64\lib\site-packages\tensorflow\python\framework\errors_impl.py", line 526, in __exit__
c_api.TF_GetCode(self.status.status))
tensorflow.python.framework.errors_impl.NotFoundError: Failed to create a NewWriteableFile: ./data/train_data/COCO/tfrecords/coco.tfrecords : ϵͳ\udcd5Ҳ\udcbb\udcb5\udcbdָ\udcb6\udca8\udcb5\udcc4·\udcbe\udcb6\udca1\udca3
; No such process
根据这个网址的提示:https://github.com/datitran/raccoon_dataset/issues/41
要修改输入输出路径,我觉得就是这个文件convert_tfrecord.py里的路径错误,上面那个是保存数据图片名字和标注的txt文件的路径,下面是输出打包后tfrecords文件的目录,没有这个保存目录它会自己创建:
我改成了:

继续输入8.开头的那个命令,开始生成tfrecord文件,tfrecord文件就是把那些Images数据和标注好的annotations标注打包起来,生成一个tfrecord文件:
![]()
为了好看,我把它的名字改成了tain2017.tfrecords
之后,在这下面两个网址下载用来测试的图片和标注。
http://images.cocodataset.org/zips/test2017.zip
wget http://images.cocodataset.org/annotations/image_info_test2017.zip
根据上面第7、8的步骤,用同样的方法生成tfrecord文件,我取名为test2017.tfrecords
然后打开tensorflow-yolo3下面的quick_train.py文件:
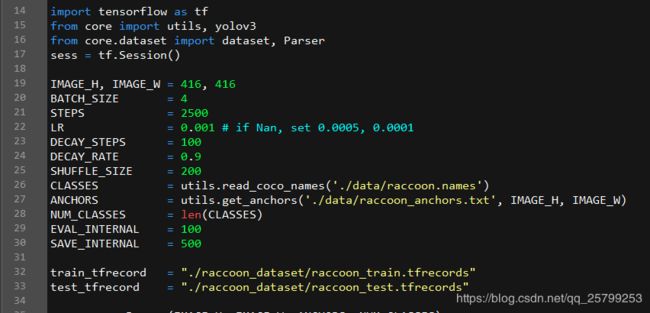
1. BATCH_SIZE是总共训练包的个数,但你训练时出现显存不够(Out of range),或是蓝屏、程序崩溃的时候可以尝试把这个参数调小。
2. STEPS是迭代次数的多少,低则识别率低,反之则否,我用3000幅左右的图片来训练并且迭代2500次用了一个半小时,我迭代50000次则用了25个小时左右。
3. CLASSES之后的路径是存放你要识别的类别的txt文件。
4. ANCHORS之后的路径是你训练的网络单元的权重文件,这个txt文件名含有anchors,我们用的是VOC格式的数据,这里要改为voc_anchors.txt。
最下面的两个train_tfrecord和test_tfrecord是之前生成的,改好路径。改为:
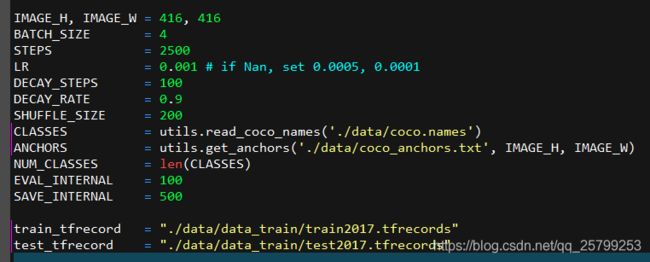
注意这两个tfrecords文件的路径,你的路径不一定和我的相同,但一定要保证你有你自己的这个路径,并且存在这两个文件。
然后在anaconda prompt中进入tensorflow-yolo3的根目录,输入命令开始训练:
python quick_train.py最后会在tensorflow-yolo3/checkpoint目录下生成三个ckpt文件,这个就是训练好的模型。

然后在anaconda prompt中输入命令生成模型应用文件:
python convert_weight.py -cf ./checkpoint/yolov3.ckpt-2500 -nc 1 -ap ./data/coco_anchors.txt --freeze此命令会利用上面的ckpt文件生成*cpu_nms.pb和*gpu_nms.pb文件。
然后打开文件:tensorflow-yolov3/quick_test.py
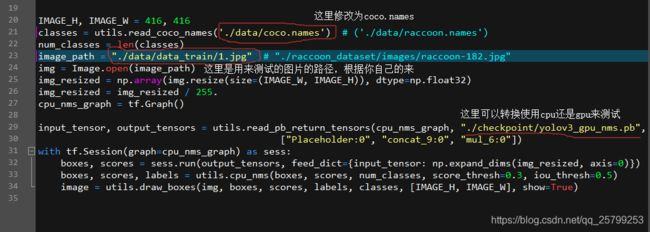
anaconda prompt下输入命令来测试:
python quick_test.py这时候等一会儿,会出现那幅测试的图片,被识别出来的物体会被框出来。
然后是评估模型,打开tensorflow-yolov3/evaluate.py:
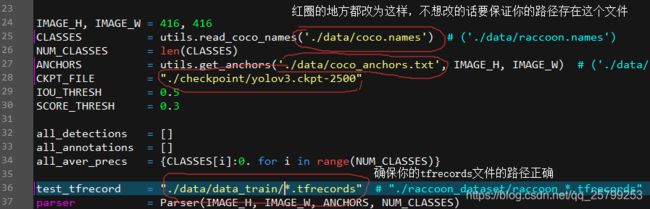
anaconda prompt下输入命令来评估:
python evaluate.py 
这个mAP就是识别率。
*****完结撒花*****
另附参考博客:
https://www.aiuai.cn/aifarm836.html?tdsourcetag=s_pcqq_aiomsg#2.YOLOV3%E9%A1%B9%E7%9B%AE%E5%85%A5%E6%89%8B