EL之Bagging:kaggle比赛之利用泰坦尼克号数据集建立Bagging模型对每个人进行获救是否预测
EL之Bagging:kaggle比赛之利用泰坦尼克号数据集建立Bagging模型对每个人进行获救是否预测
目录
输出结果
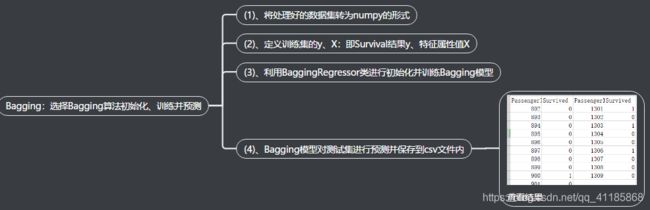
设计思路
核心代码
输出结果
设计思路
核心代码
bagging_clf = BaggingRegressor(clf_LoR, n_estimators=10, max_samples=0.8, max_features=1.0, bootstrap=True, bootstrap_features=False, n_jobs=-1)
bagging_clf.fit(X, y)
#BaggingRegressor
class BaggingRegressor Found at: sklearn.ensemble.bagging
class BaggingRegressor(BaseBagging, RegressorMixin):
"""A Bagging regressor.
A Bagging regressor is an ensemble meta-estimator that fits base
regressors each on random subsets of the original dataset and then
aggregate their individual predictions (either by voting or by averaging)
to form a final prediction. Such a meta-estimator can typically be used as
a way to reduce the variance of a black-box estimator (e.g., a decision
tree), by introducing randomization into its construction procedure and
then making an ensemble out of it.
This algorithm encompasses several works from the literature. When
random
subsets of the dataset are drawn as random subsets of the samples, then
this algorithm is known as Pasting [1]_. If samples are drawn with
replacement, then the method is known as Bagging [2]_. When random
subsets
of the dataset are drawn as random subsets of the features, then the
method
is known as Random Subspaces [3]_. Finally, when base estimators are
built
on subsets of both samples and features, then the method is known as
Random Patches [4]_.
Read more in the :ref:`User Guide `.
Parameters
----------
base_estimator : object or None, optional (default=None)
The base estimator to fit on random subsets of the dataset.
If None, then the base estimator is a decision tree.
n_estimators : int, optional (default=10)
The number of base estimators in the ensemble.
max_samples : int or float, optional (default=1.0)
The number of samples to draw from X to train each base estimator.
- If int, then draw `max_samples` samples.
- If float, then draw `max_samples * X.shape[0]` samples.
max_features : int or float, optional (default=1.0)
The number of features to draw from X to train each base estimator.
- If int, then draw `max_features` features.
- If float, then draw `max_features * X.shape[1]` features.
bootstrap : boolean, optional (default=True)
Whether samples are drawn with replacement.
bootstrap_features : boolean, optional (default=False)
Whether features are drawn with replacement.
oob_score : bool
Whether to use out-of-bag samples to estimate
the generalization error.
warm_start : bool, optional (default=False)
When set to True, reuse the solution of the previous call to fit
and add more estimators to the ensemble, otherwise, just fit
a whole new ensemble.
n_jobs : int, optional (default=1)
The number of jobs to run in parallel for both `fit` and `predict`.
If -1, then the number of jobs is set to the number of cores.
random_state : int, RandomState instance or None, optional
(default=None)
If int, random_state is the seed used by the random number generator;
If RandomState instance, random_state is the random number
generator;
If None, the random number generator is the RandomState instance
used
by `np.random`.
verbose : int, optional (default=0)
Controls the verbosity of the building process.
Attributes
----------
estimators_ : list of estimators
The collection of fitted sub-estimators.
estimators_samples_ : list of arrays
The subset of drawn samples (i.e., the in-bag samples) for each base
estimator. Each subset is defined by a boolean mask.
estimators_features_ : list of arrays
The subset of drawn features for each base estimator.
oob_score_ : float
Score of the training dataset obtained using an out-of-bag estimate.
oob_prediction_ : array of shape = [n_samples]
Prediction computed with out-of-bag estimate on the training
set. If n_estimators is small it might be possible that a data point
was never left out during the bootstrap. In this case,
`oob_prediction_` might contain NaN.
References
----------
.. [1] L. Breiman, "Pasting small votes for classification in large
databases and on-line", Machine Learning, 36(1), 85-103, 1999.
.. [2] L. Breiman, "Bagging predictors", Machine Learning, 24(2), 123-140,
1996.
.. [3] T. Ho, "The random subspace method for constructing decision
forests", Pattern Analysis and Machine Intelligence, 20(8), 832-844,
1998.
.. [4] G. Louppe and P. Geurts, "Ensembles on Random Patches", Machine
Learning and Knowledge Discovery in Databases, 346-361, 2012.
"""
def __init__(self,
base_estimator=None,
n_estimators=10,
max_samples=1.0,
max_features=1.0,
bootstrap=True,
bootstrap_features=False,
oob_score=False,
warm_start=False,
n_jobs=1,
random_state=None,
verbose=0):
super(BaggingRegressor, self).__init__(base_estimator,
n_estimators=n_estimators, max_samples=max_samples,
max_features=max_features, bootstrap=bootstrap,
bootstrap_features=bootstrap_features, oob_score=oob_score,
warm_start=warm_start, n_jobs=n_jobs, random_state=random_state,
verbose=verbose)
def predict(self, X):
"""Predict regression target for X.
The predicted regression target of an input sample is computed as
the
mean predicted regression targets of the estimators in the ensemble.
Parameters
----------
X : {array-like, sparse matrix} of shape = [n_samples, n_features]
The training input samples. Sparse matrices are accepted only if
they are supported by the base estimator.
Returns
-------
y : array of shape = [n_samples]
The predicted values.
"""
check_is_fitted(self, "estimators_features_")
# Check data
X = check_array(X, accept_sparse=['csr', 'csc'])
# Parallel loop
n_jobs, n_estimators, starts = _partition_estimators(self.n_estimators,
self.n_jobs)
all_y_hat = Parallel(n_jobs=n_jobs, verbose=self.verbose)(
delayed(_parallel_predict_regression)(
self.estimators_[starts[i]:starts[i + 1]],
self.estimators_features_[starts[i]:starts[i + 1]],
X) for
i in range(n_jobs))
# Reduce
y_hat = sum(all_y_hat) / self.n_estimators
return y_hat
def _validate_estimator(self):
"""Check the estimator and set the base_estimator_ attribute."""
super(BaggingRegressor, self)._validate_estimator
(default=DecisionTreeRegressor())
def _set_oob_score(self, X, y):
n_samples = y.shape[0]
predictions = np.zeros((n_samples, ))
n_predictions = np.zeros((n_samples, ))
for estimator, samples, features in zip(self.estimators_,
self.estimators_samples_,
self.estimators_features_):
# Create mask for OOB samples
mask = ~samples
predictions[mask] += estimator.predict(mask:])[(X[:features])
n_predictions[mask] += 1
if (n_predictions == 0).any():
warn("Some inputs do not have OOB scores. "
"This probably means too few estimators were used "
"to compute any reliable oob estimates.")
n_predictions[n_predictions == 0] = 1
predictions /= n_predictions
self.oob_prediction_ = predictions
self.oob_score_ = r2_score(y, predictions)