《从零开始学架构》三:高性能数据库
1 高性能数据库集群
1.1 读写分离
目的:分散数据库读写操作的压力
基本原理:将数据库读写操作分散到不同的节点上
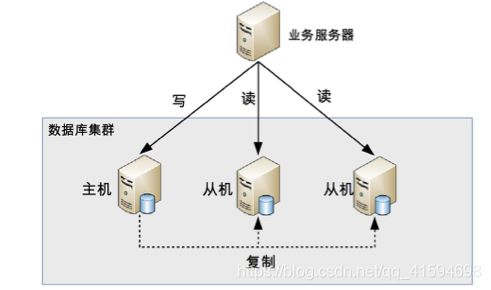
复杂度:主从复制延迟和分配机制
1.1.1 主从复制延迟
带来的问题:
如果业务服务器将数据写入到数据库主服务器后立刻(1 秒内)进行读取,此时读操作访问的是从机,主机还没有将数据复制过来,到从机读取数据是读不到最新数据的,业务上就可能出现问题。
常见解决方法:
1 写操作后的读操作指定发给数据库主服务器
2 读从机失败后再读一次主机
这就是“二次读取”;
二次读取和业务无绑定,只需要对底层数据库访问的 API 进行封装即可,实现代价较小;
不足之处在于如果有很多二次读取,将大大增加主机的读操作压力,也会一定的危险性,例如,黑客暴力破解账号,会导致大量的二次读取操作,主机可能顶不住读操作的压力从而崩溃。3 关键业务读写操作全部指向主机,非关键业务采用读写分离
1.1.2 分配机制
将读写操作区分开来,然后访问不同的数据库服务器,一般有两种方式:程序代码封装和中间件封装。
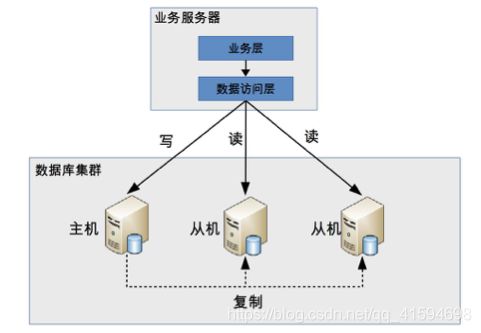
- 程序代码封装(中间层封装)
程序代码封装指在代码中抽象一个数据访问层,实现读写操作分离和数据库服务器连接的管理
基本架构:
特点:
1 实现简单,而且可以根据业务做较多定制化的功能。
2 每个编程语言都需要自己实现一次,无法通用,如果一个业务包含多个编程语言写的多个子系统,则重复开发的工作量比较大。
3 故障情况下,如果主从发生切换,则可能需要所有系统都修改配置并重启。
著名开源实现:TDDL
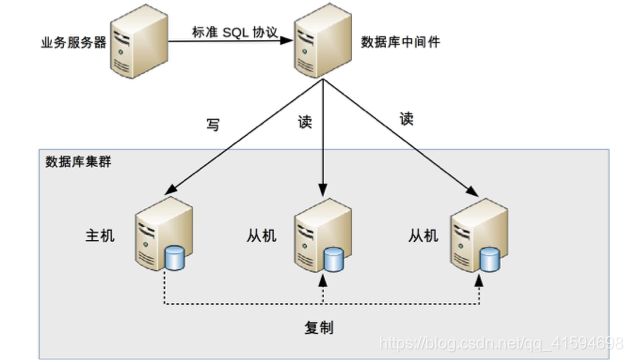
- 中间件封装
中间件封装指的是独立一套系统出来,实现读写操作分离和数据库服务器连接的管理;
中间件对业务服务器提供 SQL 兼容的协议,业务服务器无须自己进行读写分离;
对于业务服务器来说,访问中间件和访问数据库没有区别,也就是说在业务服务器看来,中间件就是一个数据库服务器:
基本架构:
特点:
1 能够支持多种编程语言,因为数据库中间件对业务服务器提供的是标准 SQL 接口。
2 数据库中间件要支持完整的 SQL 语法和数据库服务器的协议(例如,MySQL 客户端和服务器的连接协议),实现比较复杂,细节特别多,很容易出现 bug,需要较长的时间才能稳定。
3 数据库中间件自己不执行真正的读写操作,但所有的数据库操作请求都要经过中间件,中间件的性能要求也很高。
4 数据库主从切换对业务服务器无感知,数据库中间件可以探测数据库服务器的主从状态;
例如,向某个测试表写入一条数据,成功的就是主机,失败的就是从机。
著名开源实现:MySQL Router、Atlas
1.2 分库分表
目的:分散存储压力
方法:分库和分表
1.2.1 分库
按照业务模块将数据分散到不同的数据库服务器
复杂度:
1 join操作问题:需要跨库,可以使用ER或全局表来解决
2 事务问题:需要分布式事务来解决
3 成本
1.2.2 分表
分为垂直分表和水平分表:
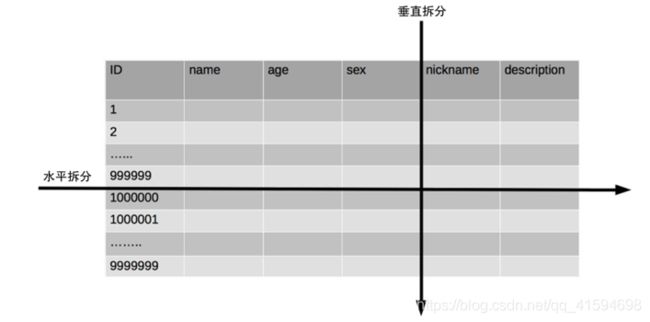
垂直分表会把表切分为两个表,一个表包含 ID、name、age、sex 列,另外一个表包含 ID、nickname、description 列。
水平切分会把表分为两个表,两个表都包含 ID、name、age、sex、nickname、description 列,但是一个表包含的是 ID 从 1 到 999999 的行数据,另一个表包含的是 ID 从 1000000 到 9999999 的行数据。
实际操作中可以切多次
垂直分表复杂度:主要体现在表操作的数量要增加
水平分布复杂度:
1路由:水平分表后,某条数据具体属于哪个切分后的子表,需要增加路由算法进行计算,这个算法会引入一定的复杂性常见路由算法:范围路由、Hash路由、配置路由
范围路由选取有序的数据列(例如,整形、时间戳等)作为路由的条件,不同分段分散到不同的数据库表中;
复杂点主要体现在分段大小的选取上:
分段太小会导致切分后子表数量过多,增加维护复杂度;
分段太大可能会导致单表依然存在性能问题;
一般建议分段大小在 100 万至 2000 万之间,具体需要根据业务选取合适的分段大小。Hash 路由选取某个列(或者某几个列组合也可以)的值进行 Hash 运算,然后根据 Hash 结果分散到不同的数据库表中;
复杂点主要体现在初始表数量的选取上:
表数量太多维护比较麻烦;
表数量太少可能导致单表性能存在问题;
增加表数量非常麻烦,所有数据都要重分布。Hash 路由的优缺点和范围路由基本相反:Hash 路由的优点是表分布比较均匀,缺点是扩充新的表很麻烦,所有数据都要重分布。
配置路由就是路由表,用一张独立的表来记录路由信息;
复杂点主要体现在必须多查询一次,会影响整体性能;
而且路由表本身如果太大(例如,几亿条数据),性能同样可能成为瓶颈,如果再次将路由表分库分表,则又面临一个死循环式的路由算法选择问题。
2跨库join 操作通过ER分片或全局表来解决
3count() 的计算**count() 相加:**在业务代码或者数据库中间件中对每个表进行 count() 操作,然后将结果相加。
优点:实现简单。
缺点:性能比较低。
**记录数表:**新建一张表,假如表名为“记录数表”,包含 table_name、row_count 两个字段,每次插入或者删除子表数据成功后,都更新“记录数表”。
优点:性能要大大优于 count() 相加的方式,因为只需要一次简单查询就可以获取数据。
缺点:增加了复杂度。
对子表的操作要同步操作“记录数表”,如果有一个业务逻辑遗漏了,数据就会不一致;
针对“记录数表”的操作和针对子表的操作无法放在同一事务中进行处理,异常的情况下会出现操作子表成功了而操作记录数表失败,同样会导致数据不一致;
增加了数据库的写压力,因为每次针对子表的 insert 和 delete 操作都要 update 记录数表定时更新:对于一些不要求记录数实时保持精确的业务可以通过后台定时更新记录数表。
定时更新实际上就是“count() 相加”和“记录数表”的结合,即定时通过 count() 相加计算表的记录数,然后更新记录数表中的数据。
4order by 操作水平分表后,数据分散到多个子表中,排序操作无法在数据库中完成,只能由业务代码或者数据库中间件分别查询每个子表中的数据,然后汇总进行排序。
1.2.3 实现方法
分库分表具体的实现方式也是“程序代码封装”和“中间件封装”,但实现会更复杂。
读写分离的实现只要识别 SQL 操作是读操作还是写操作,通过简单的判断 SELECT、UPDATE、INSERT、DELETE 几个关键字就可以做到。
分库分表的实现除了要判断操作类型外,还要判断 SQL 中具体需要操作的表、操作函数(例如 count 函数)、order by、group by 操作等,然后再根据不同的操作进行不同的处理;
1.2.4 引入分库分表的时机
1 硬件优化
2 对数据库服务器进行优化,例如增加索引,参数调整等
3 引入缓存来减少数据库压力,例如redis
4 表设计的优化,重构,还有代码的优化,如根据业务逻辑对程序逻辑做优化,减少不必要的查询;
5 进行SQL语句的优化
在这些操作都不能大幅度优化性能的情况下再考虑分库分表,当然也要对业务有一定的预估,尽量做到可扩展
2 高性能NoSQL
2.1 关系型数据库的缺点
- 关系数据库存储的是行记录,无法存储数据结构
以微博的关注关系为例,“我关注的人”是一个用户 ID 列表,使用关系数据库存储只能将列表拆成多行,然后再查询出来组装,无法直接存储一个列表。
- 关系数据库的 schema 扩展很不方便
关系数据库的表结构 schema 是强约束,操作不存在的列会报错,业务变化时扩充列也比较麻烦,需要执行 DDL(data definition language,如 CREATE、ALTER、DROP 等)语句修改,而且修改时可能会长时间锁表(例如,MySQL 可能将表锁住 1 个小时)。
- 关系数据库在大数据场景下 I/O 较高
如果对一些大量数据的表进行统计之类的运算,关系数据库的 I/O 会很高,因为即使只针对其中某一列进行运算,关系数据库也会将整行数据从存储设备读入内存。
- 关系数据库的全文搜索功能比较弱
关系数据库的全文搜索只能使用 like 进行整表扫描匹配,性能非常低,在互联网这种搜索复杂的场景下无法满足业务要求。
2.2 解决方案
- K-V 存储:解决关系数据库无法存储数据结构的问题,以 Redis 为代表。
- 文档数据库:解决关系数据库强 schema 约束的问题,以 MongoDB 为代表。
- 列式数据库:解决关系数据库大数据场景下的 I/O 问题,以 HBase 为代表。
- 全文搜索引擎:解决关系数据库的全文搜索性能问题,以 Elasticsearch 为代表。
3 高性能缓存架构
在某些复杂的业务场景下,单纯依靠存储系统的性能提升不够的,典型的场景有:
需要经过复杂运算后得出的数据,存储系统无能为力,如count(*)
读多写少的数据,存储系统有心无力
为了弥补存储系统在这些复杂业务场景下的不足,缓存出现了
基本原理:将可能重复使用的数据放到内存中,一次生成、多次使用,避免每次使用都去访问存储系统。
复杂性:架构设计时如果没有针对缓存的复杂性进行处理,某些场景下甚至会导致整个系统崩溃,如缓存穿透、缓存雪崩、缓存热点,需要使用对应的方案来解决
实现方式:由于缓存的各种访问策略和存储的访问策略是相关的,因此上面的各种缓存设计方案通常情况下都是集成在存储访问方案中,可以采用“程序代码实现”的中间层方式,也可以采用独立的中间件来实现。