《集体智慧编程》——分级聚类的实现
**(博客-单词)**
一:feeflist.txt
http://blog.csdn.net/hlx371240/rss/list
http://blog.csdn.net/sunflower606/rss/list
http://blog.csdn.net/leshami/rss/list
http://blog.csdn.net/cuit/rss/list
http://blog.csdn.net/abcjennifer/rss/list
http://blog.csdn.net/augusdi/rss/list
http://blog.csdn.net/zouxy09/rss/list
http://blog.csdn.net/yeyang911/rss/listhttp://blog.csdn.net/kewing/rss/list
自己在csdn上找的8个博客的rss
二:generatefeedvector.py
生成blogdata.txt
行代表出现的单词
列代表的是博客名
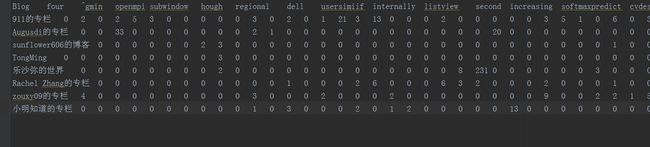
源码:
# -*- coding: utf-8 -*-
#列聚类不行,不是算法上的原因,是因为节点和线太多,像素点不够
from math import sqrt
from PIL import Image,ImageDraw,ImageFont
# 加载数据文件
def readfile(filename):
"""load data"""
with open(filename) as file:
lines = [line for line in file]
# 第一列是列标题
colnames = lines[0].strip().split('\t')
rownames = []
data = []
for line in lines[1:]:
p = line.strip().split('\t')
# 每行第一列是行名
rownames.append(p[0])
# 其余部分是数据
data.append([float(x) for x in p[1:]])
return rownames,colnames,data
#rows,cols,data = readfile(r"D:\subject\PycharmProjects\blogdata")
#上面的代码测试完毕,结果正确
# 皮尔逊算法--求相似度
def pearson(v1, v2):
"""pearson"""
# 求和
sum1 = sum(v1)
sum2 = sum(v2)
# 求平方和
sum1sq = sum([pow(v,2) for v in v1])
sum2sq = sum([pow(v,2) for v in v2])
# 求乘积之和
psum = sum([v1[i] * v2[i] for i in range(len(v1))])
# 计算pearson score
num = psum - (sum1 * sum2 / len(v1))
den = sqrt((sum1sq - pow(sum1,2) / len(v1)) * (sum2sq - pow(sum2,2) / len(v1)))
if den == 0:
return 0
return 1.0 - num / den
class bicluster:
def __init__(self,vec,left=None,right=None,distance=0.0,id=None):
self.vec = vec
self.left = left
self.right = right
self.distance = distance
self.id = id
# 聚类算法
def hcluster(rows, distancefunc = pearson):
"""cluster"""
distances = {}
currentclusterid = -1
# 最开始的聚类就是数据集中的行
clust = [bicluster(rows[i], id=i) for i in range(len(rows))]
while len(clust) > 1:
lowestpair = (0,1)
closest = distancefunc(clust[0].vec, clust[1].vec)
# 遍历每个配对,寻找最小值
for i in range(len(clust)):
for j in range(i + 1, len(clust)):
# 用distances缓存距离的计算值
if (clust[i].id, clust[j].id) not in distances:
distances[(clust[i].id, clust[j].id)] = distancefunc(clust[i].vec, clust[j].vec)
d = distances[(clust[i].id, clust[j].id)]
if d < closest:
closest = d
lowestpair = (i, j)
# 计算两个聚类的平均值
mergevec = [(clust[lowestpair[0]].vec[i] + clust[lowestpair[1]].vec[i]) / 2.0
for i in range(len(clust[0].vec))]
# 建立新的聚类
newcluster = bicluster(mergevec,left=clust[lowestpair[0]],right=clust[lowestpair[1]],distance=closest,id=currentclusterid)
# 不在原始集合中的聚类,其id为负数
currentclusterid -= 1
del clust[lowestpair[1]]
del clust[lowestpair[0]]
clust.append(newcluster)
return clust[0]
#----------------------------------------------------------------------
# 树状图
#----------------------------------------------------------------------
# 树状图 -- 树的总高度
def getheight(clust):
"""get the height of the tree"""
if clust.left == None and clust.right == None:
return 1
else:
return (getheight(clust.left) + getheight(clust.right))
#----------------------------------------------------------------------
# 树状图 -- 树的距离
def getdepth(clust):
"""the depth of the tree"""
if clust.left == None and clust.right == None:
return 0
else:
return (max(getdepth(clust.left), getdepth(clust.right)) + clust.distance)
#----------------------------------------------------------------------
# 生成图片
def drawdendrogram(clust, labels, jpeg = 'clusters.jpg'):
"""draw the picture"""
# 获得高度和宽度
h = getheight(clust)*30
w = 1400
depth = getdepth(clust)
# 由于宽度固定,因此需要对距离进行调整
scaling = float(w-150)/depth
# 创建白色背景的图片
img = Image.new('RGB', (w,h), (255,255,255))
draw = ImageDraw.Draw(img)
draw.line((0,h/2,10,h/2), fill=(255,0,0))
# 画第一个节点
drawnode(draw, clust, 10, (h/2), scaling, labels)
img.save(jpeg, 'JPEG')
#----------------------------------------------------------------------
# 画节点和连线
def drawnode(draw, clust, x, y, scaling, labels):
"""draw node and lined node"""
if clust.id < 0:
h1 = getheight(clust.left)*20
h2 = getheight(clust.right)*20
top = y - (h1+h2)/2
bottom = y + (h1+h2)/2
# 线的长度
l1 = clust.distance * scaling
# 聚类到其子节点的垂直线
draw.line((x, top + h1/2, x, bottom - h2/2), fill=(255,0,0))
# 连接左侧节点的水平线
draw.line((x, top+h1/2, x+l1, top+h1/2), fill=(255,0,0))
# 连接右侧节点的水平线
draw.line((x, bottom-h2/2, x+l1, bottom-h2/2), fill=(255,0,0))
# 绘制左右节点
drawnode(draw, clust.left, x+l1, top+h1/2, scaling, labels)
drawnode(draw, clust.right, x+l1, bottom-h2/2, scaling, labels)
else:
# 是叶节点则绘制其标签
font = ImageFont.truetype('simsun.ttc',24)
draw.text((x + 5,y - 7), unicode(labels[clust.id],'utf-8'), (0,0,0),font=font)
print labels[clust.id]
#列聚类
#矩阵的转置
def rotatematrix(data):
newdata=[]
for i in range(len(data[0])):
newrow=[data[j][i] for j in range(len(data))]
newdata.append(newrow)
return newdata
if __name__ == '__main__':
blognames,words,data = readfile(r"D:\subject\PycharmProjects\blogdata")
clust=hcluster(data)
print clust.id
drawdendrogram(clust,blognames,jpeg='blogclust.jpg')
rotatematrix(data)
'''
#列聚类
newdata=rotatematrix(data)
clustcol=hcluster(newdata)
print clustcol.id
print "........"
'''行聚类

列聚类(运行时间很长,因为节点太多,此文中3471个)
报错:
不是算法上的原因,是因为节点和线太多,像素点不够
结果:
画图中出现中文问题的解决方案:
这里写链接内容
**(物品-用户 偏好聚类的实现)**
# --coding:utf-8--
import clusters
def tanimoto(v1,v2):
c1,c2,shr = 0,0,0
for i in range(len(v1)):
if v1[i]!=0:
c1+=1
if v2[i]!=0:
c2+=1
if v1[i]!=0 and v2[i]!=0:
shr+=1
return 1.0 - (float(shr) / (c1 + c2 - shr))
wants, people,data = clusters.readfile('zebo.txt')
print "用户想要物品的总数量: %d" % len(data)
print "用户数:%d" % len(data[0])
#实现物品的聚类
clust = clusters.hcluster(data,distancefunc=tanimoto)
clusters.drawdendrogram(clust,wants,jpeg='zebocluster.jpg')
结果:
