Redis: 缓存过期、缓存雪崩、缓存穿透、缓存击穿(热点)、缓存并发(热点)、多级缓存、布隆过滤器
1.缓存过期
缓存过期:在使用缓存时,可以通过TTL(Time To Live)设置失效时间,当TTL为0时,缓存失效。
为什么要设置缓存的过期时间呢?
一、为了节省内存
例如,在缓存中存放了近3年的10亿条博文数据,但是经常被访问的可能只有10万条,其他的可能几个月才访问一次。
那么,就没有必要让所有的博文数据长期存在于缓存中。
设置一个过期时间比方说7天,超过7天未被访问的博文数据将会自动失效,如此节省大量内存。
二、时效性信息
有些信息具有时效性,设置过期时间非常合适。例如:游戏中的发言间隔为10秒钟,可以通过缓存实现。
三、用于分布式锁
参考博客:Redis: 分布式锁的官方算法RedLock以及Java版本实现库Redisson
四、其他需求
2.缓存雪崩
缓存雪崩:某一时间段内,缓存服务器挂掉,或者大量缓存失效,导致大量请求直接访问数据库,给数据库造成极大压力,甚至宕机,严重时引起整个系统的崩溃。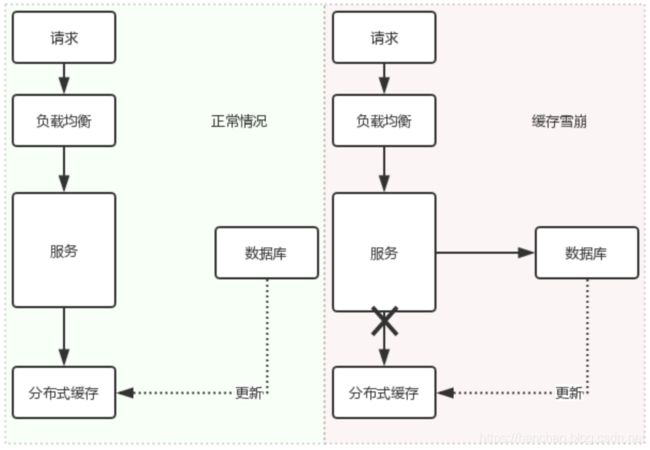
解决办法:
- 数据库访问加锁
- 随机过期时间
- 定时刷新缓存
- 缓存刷新标记
- 多级缓存
2.1.数据库访问加锁
因为短时间内大量请求访问数据库,导致后续影响,那么限制数据库的访问量不就行了吗?
限制数据库访问量的方法有很多,对数据库的访问进行加锁就是一种最直接的方式。
下面分别给出的伪代码:
/**
* 用于加锁的对象
*/
private static final byte[] LOCK_OBJ = new byte[0];
/**
* 获取商品信息
*/
public String getGoodsByLock(String key) {
//获取缓存值
String value = RedisService.get(key);
// 如果缓存有值,就直接取出来即可
if (value != null) {
return value;
} else {
//对数据库的访问进行加锁限制
synchronized (LOCK_OBJ) {
value = RedisService.get(key);
if (value != null) {
return value;
} else {
//访问数据库
value = MySqlService.select(key);
//缓存刷新
RedisService.set(key, value, 10);
}
}
return value;
}
}
分析:加锁会产生线程阻塞,导致用户长时间进行等待,体验不好,只适合并发量小的场景。
2.2.随机过期时间
缓存雪崩的主要原因是,短时间内大量缓存失效造成的,那么避免大量缓存同时失效不就行了吗?
避免大量缓存失效的最直接方法就是给缓存设置不同的过期时间。例如,原定失效时间30分钟,修改为失效时间在30~35分钟之内随机。
下面给出一种获取随机失效时间的简单实现作为参考:
/**
* 获取随机失效时间
*
* @param originExpire 原定失效时间
* @param randomScope 最大随机范围
* @return 随机失效时间
*/
public static Long getRandomExpire(Long originExpire, Long randomScope) {
return originExpire + RandomUtils.nextLong(0, randomScope);
}
**分析:**随机过期时间,虽然实现简单,但是并不能完全避免大量缓存的同时过期。
例如:大量缓存的过期时间设置在30~35分钟,但是无论如何随机,这些缓存经过40分钟后,都会过期。
造成如此结果的原因可能有很多,例如:过期时间设计不合理等。
2.3.定时刷新缓存
避免大量缓存失效的另一种策略就是:开发额外的服务,定时刷新缓存。
这样做,虽然能够保证缓存的失效,但是有个弊端:缓存可能多种多样,每种缓存都需要开发对应的定时刷新服务,相当麻烦。
2.4.缓存刷新标记
缓存失效标记,其实也是一种缓存刷新策略,只不过它更加通用化,无需针对每种缓存进行定制开发。
**思路:**不仅存储缓存数据,而且存储是否需要刷新的标记。
缓存刷新标记:
标记数据是否应该被刷新,如果存在则表示数据无需刷新,反之则表示需要刷新。
缓存刷新标记的过期时间要比缓存本身的过期时间要短,这样才能起到提前刷新的效果。可以设置为1:2,或者1:1.5。
下面给出伪代码:
/**
* 线程池:用于异步刷新缓存
*/
private static ExecutorService executorService = Executors.newCachedThreadPool();
/**
* 缓存刷新标记后缀
*/
public static final String REFRESH_SUFFIX = "_r";
/**
* 获取缓存刷新标记的key
*/
public String getRefreshKey(String key) {
return key + REFRESH_SUFFIX;
}
/**
* 判断无需刷新: 刷新标记存在,则表示不需要刷新
*/
public boolean notNeedRefresh(String key) {
return RedisService.containsKey(key + REFRESH_SUFFIX);
}
/**
* 获取商品信息
*/
public String getGoods(String key) {
//获取缓存值
String value = RedisService.get(key);
//过期时间
Long expire = 10L;
//如果无需刷新,则直接返回缓存值
if (notNeedRefresh(key)) {
//理论上:如果缓存刷新标记存在,则缓存必存在,所以可以直接返回
return value;
} else {
//如果需要刷新,则重置缓存刷新标记的过期时间
RedisService.set(getRefreshKey(key), "1", expire / 2);
//如果缓存有值,就直接返回即可
if (value != null) {
//因为有值,所以可以异步刷新缓存
executorService.submit(() -> {
//访问数据库
String newValue = MySqlService.select(key);
//缓存刷新
RedisService.set(key, newValue, expire);
});
return value;
} else {
//因为无值,所以还是要同步刷新缓存
value = MySqlService.select(key);
//缓存刷新
RedisService.set(key, value, expire);
return value;
}
}
}
分析:刷新标记本身也存在大量失效的可能。
2.5.多级缓存
所谓多级缓存,就是设置多个层级的缓存。

例如:
本地缓存 + 分布式缓存构成二级缓存,本地缓存作为第一级缓存,分布式缓存作为第二级缓存。
本地缓存可以通过多种技术实现,如:Ehcache、Caffeine等。
分布式缓存一般采用Redis实现。
由于本地缓存会占用JVM的heap空间,所以本地缓存中存放少量关键信息,其他的缓存信息存放在分布式缓存中。
下面是一个二级缓存示例的伪代码:
/**
* 是否使用一级缓存
*/
@Setter
private boolean useFirstCache;
/**
* 查询商品信息
*/
public String getGoods(String key) {
String value;
//如果使用一级缓存,则首先从一级缓存中获取数据
if (useFirstCache) {
value = LocalCacheService.get(key);
if (value != null) {
return value;
}
}
//如果一级缓存中无值,则查询二级缓存
value = RedisCacheService.get(key);
if (value != null) {
return value;
} else {
//如果二级缓存中也无值,则查询数据库
value = MySqlService.select(key);
//缓存刷新
RedisCacheService.set(key, value, 10);
return value;
}
}
3.缓存穿透
缓存穿透:大量请求查询本就不存在的数据,由于这些数据在缓存中肯定不存在,所以会直接绕过缓存,直接访问数据库,给数据库造成极大压力,甚至宕机,严重时引起整个系统的崩溃。
举例:有些黑客恶意攻击网站,制造大量请求访问不存在的缓存,直接搞垮网站。
解决办法:
空值缓存
布隆过滤器
3.1.空值缓存
空值缓存:查询数据库为空时,仍然把空设置成一种默认值进行缓存,这样后续请求继续请求这个key时,知道值不存在就不会去数据库查询了。
下面给出示例伪代码:
/**
* 缓存空值
*/
public static final String NULL_CACHE = "_";
/**
* 获取商品信息
*/
public String getGoodsByLock(String key) {
//获取缓存值
String value = RedisCacheService.get(key);
//如果缓存有值
if (value != null) {
//如果缓存的是空值,则直接返回空,无需查询数据库
if (NULL_CACHE.equals(value)) {
return null;
} else {
return value;
}
} else {
//访问数据库
value = MySqlService.select(key);
//如果数据库有值,则直接返回
if (value != null) {
//缓存刷新
RedisCacheService.set(key, value, 10);
return value;
} else {
//如果数据库无值,则设置空值缓存
RedisCacheService.set(key, NULL_CACHE, 5);
return null;
}
}
}
3.2.布隆过滤器
什么是布隆过滤器?
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的bit数组和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。
简单理解布隆过滤器
首先,我们定义一个bit数组,每个元素只占1byte。

然后,在存放每个元素时,分表对其进行若干次(例如3次)哈希函数计算,将每个哈希结果对应的bit数组元素置为1。
最后,判断一个元素是否在bit数组中,只需对其同样进行若干次(例如3次)哈希函数计算,如果计算结果对应的bit数组元素都为1,则可以判断:这个元素可能存在与bit数组中;如果有任一个哈希结果对应的元素不为1,则可以判断:这个元素必定不存在于bit数组中。
关于布隆过滤器的实现有多种,常用的有guava包和redis。
guava版本的布隆过滤器
这里给出guava版本布隆过滤器的简单使用:
//定义布隆过滤器的期望填充数量
Integer expectedInsertions = 100;
//定义布隆过滤器:默认情况下,使用5个哈希函数已保证3%的误差率。
BloomFilter userIdFilter = BloomFilter.create(Funnels.longFunnel(),expectedInsertions);
//填充布隆过滤器
//获取全部用户ID List idList = MySqlService.getAllId();
List idList = Lists.newArrayList(521L,1314L,9527L,3721L);
if (CollectionUtils.isNotEmpty(idList)){
idList.forEach(userIdFilter::put);
}
//通过布隆过滤器判断数据是否存在
log.info("521是否存在:{}",userIdFilter.mightContain(521L));
log.info("125是否存在:{}",userIdFilter.mightContain(125L));
运行结果:
INFO traceId: pers.hanchao.basiccodeguideline.redis.bloom.BloomFilterDemo:33 - 521是否存在:true
INFO traceId: pers.hanchao.basiccodeguideline.redis.bloom.BloomFilterDemo:34 - 125是否存在:false
**缺点:**是一种本地布隆过滤器,基于JVM内存,会占用heap空间,重启失效,不适用与分布式场景,不适用与大批量数据。
Redis版本的布隆过滤器
基于Redis的布隆过滤器实现,目前本人也并未深入了解,这里暂时就不班门弄斧了,各位可自行了解。
4.缓存热点并发
缓存热点并发: 大量请求查询一个热点Key,此key过期的瞬间来不及更新,导致大量请求直接访问数据库,给数据库造成极大压力,甚至宕机,严重时引起整个系统的崩溃。
解决办法:
- 缓存重建加锁
- 热点key不过期:重建缓存期间,数据不一致。
- 多级缓存。
4.1.缓存重建加锁
与章节2.1.数据库访问加锁的思路类似,伪代码如下:
/**
* 用于加锁的对象
*/
private static final byte[] LOCK_OBJ = new byte[0];
/**
* 通过某种手段(如配置中心等)判断一个值是热点key。这里为了示例直接硬编码
*/
private Set hotKeySet = Sets.newHashSet("521", "1314");
/**
* 获取商品信息
*/
public String getGoodsByLock(String key) {
//获取缓存值
String value = RedisCacheService.get(key);
// 如果缓存有值,就直接取出来即可
if (value != null) {
return value;
} else {
//如果是热点key,则对缓存重建过程进行加锁
if (hotKeySet.contains(key)) {
//对缓存重建过程进行加锁限制
synchronized (LOCK_OBJ) {
value = RedisCacheService.get(key);
if (value != null) {
return value;
} else {
//访问数据库
value = MySqlService.select(key);
//缓存刷新
RedisCacheService.set(key, value, 10);
}
}
} else {
//如果是普通Key,无需对缓存重建加锁
value = MySqlService.select(key);
//缓存刷新
RedisCacheService.set(key, value, 10);
}
return value;
}
}
虽然两者的代码类似,但是出发点不一样两者的不同:
数据库访问加锁:针对的是所有的缓存。
缓存重建加锁:针对的是热点Key。
同样的,加锁会产生线程阻塞,导致用户长时间进行等待,体验不好,只适合并发量小的场景。
4.2.热点key不过期
热点Key不过期很好理解,就是通过某种手段(查库、配置中心等等)确定某个key是热点key,则在建立缓存时,不设置过期时间。
这种方式虽然从根本上杜绝了失效的可能,但是也有其不足之处:
就算缓存不过期,也会因数据变化而进行缓存重建,缓存重构期间,可能会产生数据不一致的问题。
4.3.多级缓存
参考:章节2.5.多级缓存。
关注点:将热点Key存放在一级缓存。
5.缓存击穿
缓存击穿:大量请求查询一个热点Key,由于一个Key在分布式缓存中的节点是固定的,所以这个节点短时间内承受极大压力,可能会挂掉,引起整个缓存集群的挂掉,导致大量请求直接访问数据库,给数据库造成极大压力,甚至宕机,严重时引起整个系统的崩溃。
**举例:**现实生活中发生的一些重大新闻,会导致大量用户访问微博,导致微博直接挂掉。这些新闻可能就是缓存中的几条数据。
解决办法:
多读多写
多级缓存
5.1.多读多写
多读多写:关键在于把全部流向一个缓存节点的压力进行分担。
实施简述:
确定存在一个key为热点key。
分布式缓存的节点数为N。
通过某种算法将这个key转换成一组key:key1,key2…keyN,并且确保这些keyi分表落到不同的缓存node上。
当请求访问这个key时,通过轮训或者随机的方式,访问keyi即可获取value值。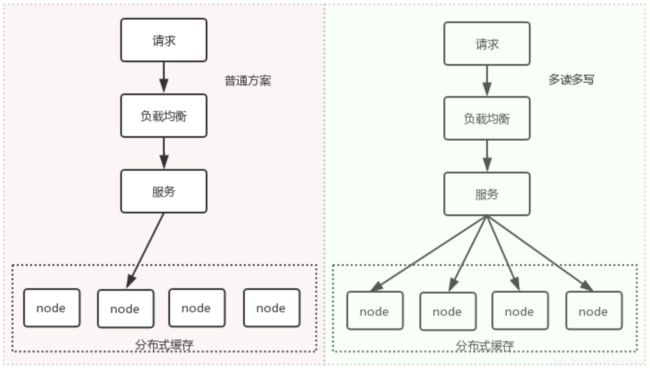
缺点
需要提供合适的算法保证拆分后的key落在不同的缓存节点上。
如果缓存节点数量发生了变化,原有算法是否继续可用?
如果缓存内容发送变化,如何保证所有keyi的强一致性?
整体来说,这个方案过重。
5.2.多级缓存
参考:章节2.5.多级缓存。
关注点:由于服务节点存在多个,本地缓存能够做到分布式缓存不易做到的事情:通过负载均衡,分散热点key的压力。
-----------------------
参考:
https://blog.csdn.net/hanchao5272/article/details/99706189