从零开始大数据【1.1】-- 在本地模式运行第一个mapreduce程序(简单明了!简单理论学习,直接动手写代码!)
从零开始大数据【1.1】-- 在本地模式运行第一个mapreduce程序
文章目录
- 从零开始大数据【1.1】-- 在本地模式运行第一个mapreduce程序
- 写在前面:
- 什么是map和reduce?
- mapreduce编程
- mapper
- reducer
- driver
- 运行
- 本地模式运行结果
- 下一章介绍
写在前面:
之前没有接触过linux,没有接触过java,更没有接触过hadoop,spark。但是由于专业相关,决定自学,于是开始看这一个视频(视频)跟着视频做了100+节课花了半个月,之后写论文又快半年没有看过了,现在发现都忘记了,从头开始学。但是由于hadoop的平台搭建过于麻烦,所以决定直接开始学mapreduce,在win+eclipse环境下本地运行mapreduce。
本系列文章将主要聚焦于用mapreduce完成相应的功能,通过了解mapreduce的框架,并按照每一个部分编写相应的需要自定义的程序,用于完成特定功能。
本篇将首先用mapreduce编写一个最简单的程序,展示mapreduce如何处理数据。
什么是map和reduce?

例如在如上图所示的一个计算每个单词出现次数的mapreduce过程中。
- 首先对于输入的大量数据(三行文字)进行切分,切分成相应的较小的数据(三个一行文字)。
- 这些较小的数据,然后输入到map过程中,map通过kv对(键值对)读取数据。本例子中key为每一行第一个字符的序号,value是这一行。
- 循环读取kv,对每一个读取值进行map操作,并输出自己定义的新的kv对。本例中对每一个value(一行句子)首先分割成相应单词,然后,对每一个单词输出一个kv对记作k-mapout和v-mapout形式如下(wish —1)。
- 之后输出的k-mapout和v-mapout会通过一个shffle的过程,主要就是聚集、排序和分区,然后输入到reduce过程中。输入到reduce仍然是一以kv对的形式只不过此时的v大多是一个可迭代的列表,并且kv对的类型与map过程输出的kv对类型一致。
- reduce过程对于输入的kv对再做一次处理。本例中累加每一个key对应的v的值。
上述就是一整个mapreduce的流程。可以看出整个过程就是一个先分后合的过程。
那这样一个过程该怎么编程实现呢?
mapreduce编程
要完成上述的例子,需要完成三个程序分别是一个mapper类、一个reducer类和一个用于连接整个过程的驱动driver主程序。在编写程序前首先把hadoop的jar包导入lib文件夹中,如下图所示
mapper
建立一个mapper类 继承mapper,重写其中的map方法。具体见下面程序:
package com.atguigu.mapreduce;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WordcountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
Text k = new Text();
IntWritable v = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// 1 获取一行
String line = value.toString();
// 2 切割
String[] words = line.split(" ");
// 3 输出
for (String word : words) {
k.set(word);
context.write(k, v);
}
}
}
reducer
建立 reducer继承reducer类,重写reduce函数
package com.atguigu.mapreduce.wordcount;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordcountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
int sum;
LongWritable v = new LongWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> value,
Context context) throws IOException, InterruptedException {
// 1 累加求和
sum = 0;
for (IntWritable count : value) {
}
// 2 输出
v.set(sum);
context.write(key,v);
}
}
driver
主要是一个main程序连接整个框架,主要有最基本的七个步骤:
- 获取配置信息
- 指定本程序jar包存在的本地路径
- 指定mapper/reducer
- 指定mapper的输出kv
- 指定最终输出的kv
- 指定job输入的原始文件所在目录
- 提交代码
具体操作方法如程序所示
package com.atguigu.mapreduce.wordcount;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordcountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException,
InterruptedException {
// 1 获取配置信息以及封装任务
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
// 2 设置 jar 加载路径
job.setJarByClass(WordcountDriver.class);
// 3 设置 map 和 reduce 类
job.setMapperClass(WordcountMapper.class);
job.setReducerClass(WordcountReducer.class);
// 4 设置 map 输出
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 5 设置 Reduce 输出
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 6 设置输入和输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 7 提交
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
运行
如上三个程序都写好了,在整体框架下应该如图所示
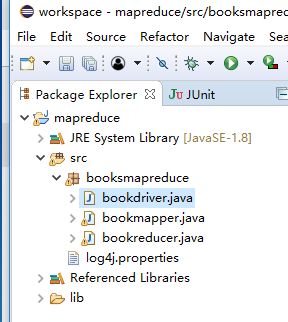
自己实际操作时没有用wordcount的例子而是使用了其他的数据自己写了程序,因此名称不一样。
然后 在driver中 配置运行信息,主要是配置文件的输入和输出如下图所示,要注意输出地址一定不能是已经存在的。
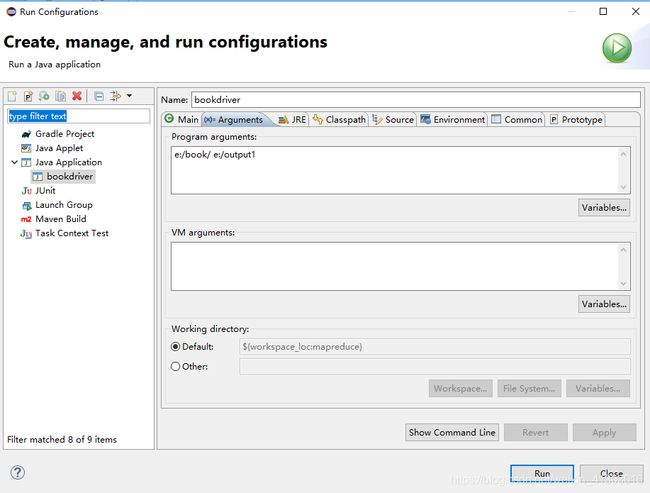
然后就可以运行啦!
本地模式运行结果
运行完成后会在再控制台输出结果,并在文件夹中生成结果,具体的可以参考视频,讲的很浅显易懂。值得注意的是,如果控制台输出不了信息即显示如下的信息
1.log4j:WARN No appenders could be found for logger (org.apache.hadoop.util.Shell).
2.log4j:WARN Please initialize the log4j system properly.
3.log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
需要在项目的src文件夹下增加一个log4j.properties文件并且在里面添加
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
下一章介绍
下一章主要总结mapreduce运行的详细框架,并总结出哪些地方可以进行编程用来完成相应功能。