【Python - OpenCV】数字图像项目实战(四) - 位姿估计
目录大纲
- 理论架构
- 基础知识汇总篇:
- API详解:
- 基础梗概
- 1. 仿射变换和透视变换
- 2. 图像坐标系、相机坐标系和世界坐标系的定义,及三者之间的变换关系。
- 3. 相机的内、外参数矩阵
- 4. 线性法求解相对位姿
- 5. 张氏标定方法
- 代码实践
- 相机标定
- 相机投影
理论架构
基础知识汇总篇:
https://blog.csdn.net/weixin_42237113/article/details/104500993
API详解:
https://blog.csdn.net/weixin_42237113/article/details/104488809
基础梗概
1. 仿射变换和透视变换
仿射变换
又称仿射映射,是指在几何中,一个向量空间进行一次线性变换并接上一个平移,变换为另一个向量空间。 仿射变换是在几何上定义为两个向量空间之间的一个仿射变换或者仿射映射(来自拉丁语,affine,“和…相关”)由一个非奇异的线性变换(运用一次函数进行的变换)接上一个平移变换组成。 基本表达形式如下所示:

举例说明: 一张图片,经过逆时针旋转30度图像变换,相关图片的变化可以称之为仿射变换。 实际上,平移、缩放、旋转都可以成为仿射变化的一种特殊情况。
透视变化
透视变换(Perspective Transformation)是指利用透视中心、像点、目标点三点共线的条件,按透视旋转定律使承影面(透视面)绕迹线(透视轴)旋转某一角度,破坏原有的投影光线束,仍能保持承影面上投影几何图形不变的变换。 简单来说,就是把物体的三维图像转变成二维特征的过程,称之为透视变化,用公式表示如下:

举例说明:鸟瞰铁轨是平行的,但是站在地上看向铁轨在远处相交到了一点。
2. 图像坐标系、相机坐标系和世界坐标系的定义,及三者之间的变换关系。
图像坐标系、相机坐标系和世界坐标系
图像处理、立体视觉等等方向常常涉及到四个坐标系:世界坐标系、相机坐标系、图像坐标系、像素坐标系。例如下图:

构建世界坐标系只是为了更好的描述相机的位置在哪里,在双目视觉中一般将世界坐标系原点定在左相机或者右相机或者二者X轴方向的中点。 接下来的重点,就是关于这几个坐标系的转换。也就是说,一个现实中的物体是如何在图像中成像的。
世界坐标系与相机坐标系

其中从世界坐标系到相机坐标系的沿着不同坐标轴的旋转关系关系如下所示:

加上平移矩阵,可以得到P点在相机坐标系中的坐标:

相机坐标系与图像坐标系
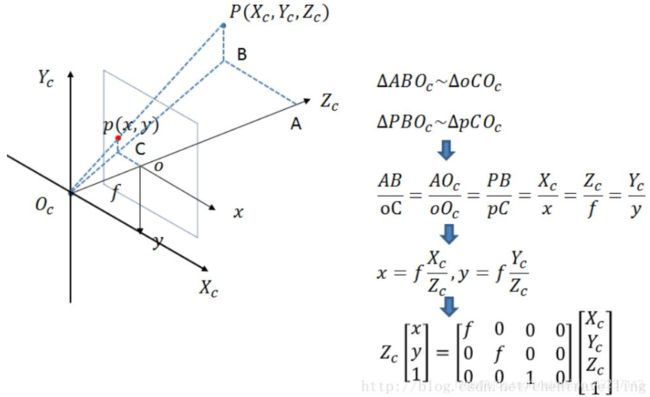
此时投影点p的单位还是mm,并不是pixel,需要进一步转换到像素坐标系。
图像坐标系与像素坐标系
像素坐标系和图像坐标系都在成像平面上,只是各自的原点和度量单位不一样。图像坐标系的原点为相机光轴与成像平面的交点,通常情况下是成像平面的中点或者叫principal point。图像坐标系的单位是mm,属于物理单位,而像素坐标系的单位是pixel,我们平常描述一个像素点都是几行几列。所以这二者之间的转换如下:其中dx和dy表示一个像素点每一列和每一行分别代表多少mm。dx,dy依据不同相机的分辨率高低而不同。

那么通过下面四个坐标系的转换就可以得到一个点从世界坐标系如何转换到像素坐标系的。

四个坐标系之间存在着下述关系 ( 矩阵依次左乘 ):

3. 相机的内、外参数矩阵
相机内参数是与相机自身特性相关的参数,比如相机的焦距、像素大小等;
相机外参数是在世界坐标系中的参数,比如相机的位置、旋转方向等。
在问题2中已经详细推导过世界坐标系下的坐标转化到图像像素坐标系下的转换公式。
在该式中,fx、fy、u0、v0只与摄像机内部参数有关,故称矩阵M1为内参数矩阵。
其中fx = f/dX ,fy = f/dY ,分别称为x轴和y轴上的归一化焦距;
f是相机的焦距,dX和dY分别表示传感器x轴和y轴上单位像素的尺寸大小。
u0和v0则表示的是光学中心,即摄像机光轴与图像平面的交点,通常位于图像中心处,故其值常取分辨率的一半。
现以Canon 70d相机为例进行求解其内参数矩阵:
焦距 f = 50mm 分辨率:1920×1080 传感器尺寸:22.5×15 mm
根据以上定义可以有:
u0 = 1920/2= 960 v0 = 1080/2 = 540
dx = 22.5/1920 =0.01171875 dy = 15/1080 = 0.013889
fu = f/dx = 4266.667 fv = f/dy = 3599.9712
4. 线性法求解相对位姿
基于空间多点相对位姿测量
通过相机标定或者相机自身参数计算获取相机内参数和畸变系数 建立世界坐标系转换为像素坐标系的方程 目的是求解外参数矩阵的旋转向量和平移向量 通过方程组的变换,消去第三维的坐标,最后得到一个关于旋转向量和平移向量的公式。 扩展到多个点的情况下,有六个或以上的特征点且非共面的时候,就可解得一个关于旋转向量和平移向量的矩阵组 利用矩阵的QR分解,得到最终的旋转矩阵和平移矩阵。 最后通过旋转矩阵计算旋转角,使得相机坐标系和世界坐标系完全平行。 注意:在实现过程中,一般使用solvePnP方法进行计算,传入参数:目标坐标系的3D点,图像平面点坐标,相机内参数,畸变系数,最后就可以得到旋转向量和平移向量
输入信息:
相机的内参数 多个空间上的特征点(非共面,>=6个)在目标坐标系(3D)和相平面坐标系(2D)坐标。
输出信息:
目标坐标系相对相机坐标系的位置和姿态。
基于平面多特征点相对位姿测量
通过相机标定或者相机自身参数计算获取相机内参数和畸变系数 建立世界坐标系转换为像素坐标系的方程 目的是求解外参数矩阵的旋转向量和平移向量 通过方程组的变换,消去第三维的坐标,最后得到一个关于旋转向量和平移向量的公式。 扩展到多个点的情况下,有四个或以上的特征点且非共面的时候,就可解得一个关于旋转向量和平移向量的矩阵组 利用矩阵的QR分解,得到最终的旋转矩阵和平移矩阵。 最后通过旋转矩阵计算旋转角,使得相机坐标系和世界坐标系完全平行。 注意:在实现过程中,一般使用solvePnP方法进行计算,传入参数:目标坐标系的3D点,图像平面点坐标,相机内参数,畸变系数,最后就可以得到旋转向量和平移向量
输入信息:
相机内参数 多个平面上的特征点(>=4个)在目标坐标系(3D)和相平面坐标系(2D)坐标
输出信息:
目标坐标系相对相机坐标系的位置和姿态。
5. 张氏标定方法
输入条件
目标物体的多个pose的图片数据,一般最少10张。
通过图片数据,获取目标坐标系的3D点和图像平面点坐标。
输出量
相机内参数矩阵
畸变系数
旋转变量
平移变量
主要步骤
设定标定板
旋转标定板或相机,采集标定板图像的不同pose
对一个pose,计算单应矩阵(类似M矩阵)
有三个以上Pose,根据各单应矩阵计算线性相机参数
使用非线性优化方法计算非线性参数
最后得到相机内参数、矩阵畸变系数以及每张图片的旋转变量和平移变量。
代码实践
相机标定
1.利用棋盘格图案和你身边能找到的相机(笔记本或台式机的摄像头,手机相机等均可)完成相机标定,并给出结果的可信性分析。(使用python-opencv实现)
1.1.2 step1 准备工作
本次作业使用设备:
(1) 自制A4纸大小的标定板 (10 x 7 黑白棋盘, 棋盘格 13mm x 13mm)
(2) 普通手机一部 (像素为2448 x 3264, 竖拍)
共拍摄照片12张

1.1.3 step2 输入数据获取
棋盘格是10x8个格子组成,但是相关API读取的是里面的内部角点(不包含最外边的角点,否则会报错),所以是9X6。 根据像素坐标和3维世界坐标系相关矩阵计算公式:
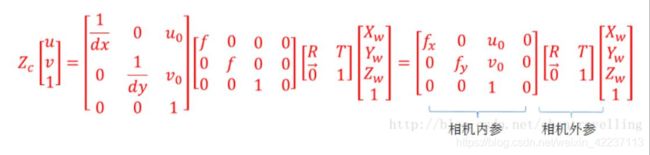
上面矩阵关系简写为 :
I = M1M2W
根据张氏标定方法,通过带入多个角点矩阵I, 世界坐标点W(Z=0,默认图片处于X,Y轴平面,减少变量),可以反算出相机内矩阵M1、相机外矩阵M2=[R|T]内各个变量。同时也会求出相关畸变参数矩阵。
因此只需要获取实际图片的世界坐标W,还有对应角点坐标矩阵I。 角点坐标通过findChessboardCorners粗提取,然后使用cornerSubPix生成亚像素点;世界坐标点,默认设定Z=0,按照棋盘角点从左到右,一次生成
(0,0,0), (113,0,0), (213,0,0) ,.
(13,0,0),(13,113,0), (13,213)…
…
注:如果不知道棋盘实际尺寸,可以设定成
(0,0,0), (1,0,0), (2,0,0) ,…, (8,5,0)
所求的相机内参数矩阵M1不变,但是外参数M2不同。
#coding:utf-8
import cv2
import numpy as np
import glob
from tqdm import tqdm
#定义棋盘大小: 注意此处是内部的行、列角点个数,不包含最外边两列,否则会出错
chessboard_size = (9,6)
# 生成54×3的矩阵,用来保存棋盘图中9*6个内角点的3D坐标,也就是物体点坐标
objp = np.zeros((np.prod(chessboard_size),3),dtype=np.float32)
# 通过np.mgrid生成对象的xy坐标点,每个棋盘格大小是130mm
# 最终得到z=0的objp为(0,0,0), (1*13,0,0), (2*13,0,0) ,...
objp[:,:2] = np.mgrid[0:chessboard_size[0], 0:chessboard_size[1]].T.reshape(-1,2)*13
# print("object is %f", objp)
# 定义数组,来保存监测到的点
obj_points = [] # 保存世界坐标系的三维点
img_points = [] # 保存图片坐标系的二维点
# 设置终止条件: 迭代30次或者变动 < 0.001
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 30, 0.001)
# 读取目录下的所有图片
calibration_paths = glob.glob('./calibaration/*.jpg')
# 为方便显示,使用tqdm显示进度条
for image_path in tqdm(calibration_paths):
# 读取图片
img = cv2.imread(image_path)
# 图像二值化
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 找到棋盘格内角点位置
ret, corners = cv2.findChessboardCorners(gray, chessboard_size, None)
if ret == True:
obj_points.append(objp)
# 亚像素级角点检测,在角点检测中精确化角点位置
corners2 = cv2.cornerSubPix(gray, corners, (5, 5), (-1, -1), criteria)
img_points.append(corners2)
# 在图中标注角点,方便查看结果
# img = cv2.drawChessboardCorners(img, chessboard_size, corners2, ret)
# img = cv2.resize(img, (400,600))
# cv2.imshow('img', img)
# cv2.waitKey(0)
cv2.destroyAllWindows()
print("finish all the pic count")
1.1.4 step3 相机参数获取¶
可以通过calibrateCamera获取相机相关内参数(fx, fy,u0, v0)[此处alpha=0,可能略有偏差]、外参数(R,T)、畸变参数(k1,k2,p1,p2,s1,s2)
# 相机标定
ret, mtx, dist, rvecs, tvecs = cv2.calibrateCamera(obj_points, img_points, gray.shape, None, None)
# 显示和保存参数
print("#######相机内参#######")
print(mtx)
print("#######畸变系数#######")
print(dist)
print("#######相机旋转矩阵#######")
print(rvecs)
print("#######相机平移矩阵#######")
print(tvecs)
np.savez('C.npz', mtx=mtx, dist=dist, rvecs=rvecs, tvecs=tvecs) #分别使用mtx,dist,rvecs,tvecs命名数组

1.1.5 step3 相机参数获取(非必要项)
可以选择使用一张图片,查看一下去除畸变之后图片效果。 在这之前,我们需要使用getOptimalNewCameraMatrix来重新生成相机矩阵,从而减少原图的有效 像素的丢失。 它有一个参数alpha,叫做尺度因子,取值0~1。 如果alpha=0,原图像会损失最多的有效像素;如果alpha=1,原图像中的所有像素都能够得到保留。 getOptimalNewCameraMatrix还返回一个图像ROI,可以用来裁剪结果。
最终效果图参见calibresult.jpg
# 使用一张图片看看去畸变之后的效果
img2 = cv2.imread('./calibaration/left_01.jpg')
print("orgininal img_point array shape",img.shape)
# img2.shape[:2]取图片 高、宽;
h, w = img2.shape[:2]
print("pic's hight, weight: %f, %f"%(h, w))
# img2.shape[:3]取图片的 高、宽、通道
# h, w ,n= img2.shape[:3]
# print("PIC shape", (h, w, n))
newcameramtx, roi = cv2.getOptimalNewCameraMatrix(
mtx, dist, (w, h), 1, (w, h)) # 自由比例参数
dst = cv2.undistort(img2, mtx, dist, None, newcameramtx)
# 根据前面ROI区域裁剪图片
x,y,w,h = roi
dst = dst[y:y+h, x:x+w]
cv2.imwrite('calibresult.jpg', dst)
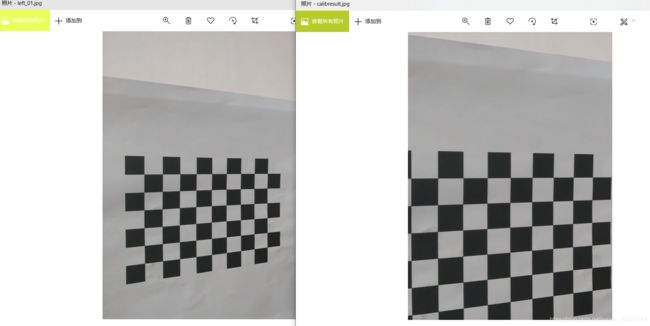
畸变比较小,消除后也进行了图片裁剪
1.1.6 step4 重投影误差
重投影误差是一个判别畸变参数准确度的参考指标,它越接近于0越好。 给定畸变矩阵,旋转矩阵和平移矩阵,首先将物体点坐标变换到图像点坐标,可以使用projectPoints 函数实现。 然后计算变换后得到的图像点和我们之前检测到的角点坐标的l2范数平均值(即加和开方求平均)。
# 计算所有图片的平均重投影误差
total_error = 0
for i in range(len(obj_points)):
img_points2, _ = cv2.projectPoints(obj_points[i], rvecs[i], tvecs[i], mtx, dist)
error = cv2.norm(img_points[i], img_points2, cv2.NORM_L2)/len(img_points2)
total_error += error
print("total error: {}".format(total_error/len(obj_points)))
1.1.7 1.3 图像数据结果分析¶
手机相关参数如下:
f = 4
分辨率:2448 x 3264
手机单个像素尺寸像素大小约为 Δx=Δy:1.4um
手动计算,预计相关参数如下:
u0'=2448/2=1224,
v0'=3264/2=1632
fx'=fy'=f/Δx=4/1.4*10^3 = 2857.14286
而通过step1-step4实际计算相关内参数:
fx = 2.69528836e+03
fy = 2.69629880e+03
u0 = 1.23297127e+03
v0 = 1.61522815e+03
相关内参计算大致都在正常误差内,比较合理。
相机投影
- 在1基础上,使用同一相机,将棋盘格放在前方1m左右固定,然后使用线性方法进行相对位姿估计,然后评价结果的合理性。
实验条件:
还是使用同样的相机:(像素为2448 x 3264, 竖拍)
将自制标定板(10 x 7, 格子大小13mm)放置在大约1000mm(1m)处,摆拍一张照片。
理论原理:
由推导过程可知,旋转变量R、位移变量T是世界坐标系变化到相机坐标系的旋转,平移变量。当标定板(世界坐标系xy平面)和相机平面(相机坐标系xy平面)大致平行的时候,二者的z轴大致平行,所以T在z轴上的位移距离大致等于两者的在现实场景中的真实距离,即大致等于1000mm。
另外可以通过事先选定世界坐标系下的3个点,利用3D->2D投影,在图像坐标系的原点处画出相关点的映射图像,也可以侧面说明相关的线性方法的相对位姿估计的正确性。
import cv2
import numpy as np
from math import degrees as dg
# 加载相机标定的内参数、外参数矩阵
with np.load('C.npz') as X:
mtx, dist, _, _ = [X[i] for i in ('mtx', 'dist', 'rvecs', 'tvecs')]
print(mtx, dist)

#定义棋盘大小
chessboard_size = (9,6)
# 世界坐标系下的物体位置矩阵(Z=0)
objp = np.zeros((np.prod(chessboard_size),3),dtype=np.float32)
objp[:,:2] = np.mgrid[0:chessboard_size[0], 0:chessboard_size[1]].T.reshape(-1,2)*13
# 像素坐标
test_img = cv2.imread("./test/100cm.jpg")
gray = cv2.cvtColor(test_img, cv2.COLOR_BGR2GRAY)
# 找到图像平面点角点坐标
ret, corners = cv2.findChessboardCorners(gray, chessboard_size, None)
if ret:
_, R, T, _, = cv2.solvePnPRansac(objp, corners, mtx, dist)
print("旋转向量",R)
print("平移向量",T)
sita_x = dg(R[0][0])
sita_y = dg(R[1][0])
sita_z = dg(R[2][0])
print("sita_x is ", sita_x)
print("sita_y is ", sita_y)
print("sita_z is ", sita_z)
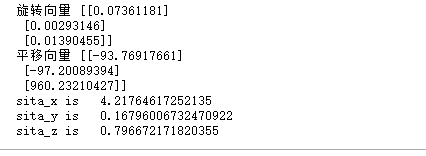
分析:
由上面计算可知:
位移变量沿着z轴的运动位移为960.23210427,沿着x,y,z旋转角度(角度制)分别为4.21度,0.167度, 0.796度 ;
可见世界坐标和相机坐标之间,基本没有怎么旋转,x,y,z轴基本处于平行状态,都是通过平移实现的。而且世界坐标和像极坐标之间距离为960.232,与实际现实中所处的1000mm基本相符。所以相对位姿基本计算正确。
2.2 3D->2D投影
import cv2
import numpy as np
import glob
# 加载相机标定的数据
with np.load('C.npz') as X:
mtx, dist, _, _ = [X[i] for i in ('mtx', 'dist', 'rvecs', 'tvecs')]
def draw(img, corners, imgpts):
"""
在图片上画出三维坐标轴
:param img: 图片原数据
:param corners: 图像平面点坐标点
:param imgpts: 三维点投影到二维图像平面上的坐标
:return:
"""
# corners[0]是图像坐标系的坐标原点;imgpts[0]-imgpts[3] 即3D世界的坐标系点投影在2D世界上的坐标
corner = tuple(corners[0].ravel())
# 沿着3个方向分别画3条线
cv2.line(img, corner, tuple(imgpts[0].ravel()), (255, 0, 0), 5)
cv2.line(img, corner, tuple(imgpts[1].ravel()), (0, 255, 0), 5)
cv2.line(img, corner, tuple(imgpts[2].ravel()), (0, 0, 255), 5)
return img
#定义棋盘大小
chessboard_size = (9,6)
# 初始化目标坐标系的3D点
objp = np.zeros((np.prod(chessboard_size),3),dtype=np.float32)
objp[:,:2] = np.mgrid[0:chessboard_size[0], 0:chessboard_size[1]].T.reshape(-1,2)
# 初始化三维坐标系
axis = np.float32([[3, 0, 0], [0, 10, 0], [0, 0, -50]]).reshape(-1, 3) # 坐标轴
# 加载打包所有图片数据
images = glob.glob('test/100cm.jpg')
for fname in images:
img = cv2.imread(fname)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 找到图像平面点坐标点
ret, corners = cv2.findChessboardCorners(gray, chessboard_size, None)
if ret:
# PnP计算得出旋转向量和平移向量
_, rvecs, tvecs, _ = cv2.solvePnPRansac(objp, corners, mtx, dist)
print("旋转变量", rvecs)
print("平移变量", tvecs)
# 计算三维点投影到二维图像平面上的坐标
imgpts, jac = cv2.projectPoints(axis, rvecs, tvecs, mtx, dist)
# 把坐标显示图片上
img = draw(img, corners, imgpts)
cv2.imwrite("3d_2d_project.jpg",img)
cv2.destroyAllWindows()
在图像中,相关3D投影的坐标系如下所示:
