猫脸关键点检测Baseline【阿水】
关键点检测是许多计算机视觉任务的基础,例如表情分析、异常行为检测。大家接触最多的可能是人脸关键点检测,广泛应用于人脸识别、美颜、换妆等。
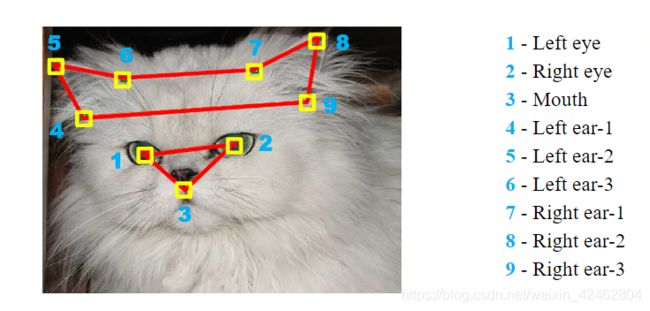
本次AI研习社举办猫脸关键点检测,训练集有10468张,测试集9526张,目标是检测猫脸的9个关键点。其实我在读书期间就看到过这个猫脸数据,来自CUHK。猫脸关键点检测也是比较新的一个方向,例子比较直接,也非常方便用于例子讲解。
猫脸关键点和人脸关键点类似,每个猫都有9个关键点信息,总共18个坐标信息。由于猫脸关键点任务中每一张图片只包含一个猫,所以在进行关键点检测的过程中并不需要加入检测的过程,只需要预测关键单坐标的位置即可。
即我将猫脸关键点检测抽象成18个坐标的回归问题,则可以直接用CNN进行回归预测:
- 将猫脸关键点进行归一化(除以图片的长宽);
- 使用CNN进行回归预测;
import os, sys, codecs
import glob
from PIL import Image
import cv2
import pandas as pd
%pylab inline
train_img = glob.glob('./train/*')
train_df = pd.read_csv('train.csv')
train_df['filename'] = train_df['filename'].apply(lambda x: './train/'+str(x)+'.jpg')
# 获取图片的长宽
train_df['shape'] = train_df['filename'].iloc[:].apply(lambda x: cv2.imread(x).shape[:2])
def show_catface(row):
img = cv2.imread(row.filename)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
cv2.circle(img, (row.left_eye_x, row.left_eye_y), 2, (0, 255, 255), 4)
cv2.circle(img, (row.right_eye_x, row.right_eye_y), 2, (0, 255, 255), 4)
cv2.circle(img, (row.mouth_x, row.mouth_y), 2, (0, 255, 255), 4)
cv2.circle(img, (row.left_ear1_x, row.left_ear1_y), 2, (0, 255, 255), 4)
cv2.circle(img, (row.left_ear2_x, row.left_ear2_y), 2, (0, 255, 255), 4)
cv2.circle(img, (row.left_ear3_x, row.left_ear3_y), 2, (0, 255, 255), 4)
cv2.circle(img, (row.right_ear1_x, row.right_ear1_y), 2, (0, 255, 255), 4)
cv2.circle(img, (row.right_ear2_x, row.right_ear2_y), 2, (0, 255, 255), 4)
cv2.circle(img, (row.right_ear3_x, row.right_ear3_y), 2, (0, 255, 255), 4)
plt.figure(figsize=(12, 12))
plt.imshow(img)
show_catface(train_df.iloc[1])
# 对关键点位置进行归一化
for col in train_df.columns:
if '_x' in col:
train_df[col] = train_df[col]*1.0 / train_df['shape'].apply(lambda x: x[1])
elif '_y' in col:
train_df[col] = train_df[col]*1.0 / train_df['shape'].apply(lambda x: x[0])
from sklearn.model_selection import train_test_split, StratifiedKFold, KFold
from efficientnet_pytorch import EfficientNet
# model = EfficientNet.from_pretrained('efficientnet-b4')
import torch
torch.manual_seed(0)
torch.backends.cudnn.deterministic = False
torch.backends.cudnn.benchmark = True
import torchvision.models as models
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.autograd import Variable
from torch.utils.data.dataset import Dataset
# 猫脸数据集
class CatDataset(Dataset):
def __init__(self, df, transform=None, train=True):
self.df = df
self.train = train
if transform is not None:
self.transform = transform
else:
self.transform = None
def __getitem__(self, index):
start_time = time.time()
img = Image.open(self.df['filename'].iloc[index]).convert('RGB')
if self.transform is not None:
img = self.transform(img)
if self.train:
return img,torch.from_numpy(np.array(self.df.iloc[index, 1:-1].values.astype(np.float32)))
else:
return img
def __len__(self):
return len(self.df)
# 猫脸关键点检测模型
class CatNet(nn.Module):
def __init__(self):
super(CatNet, self).__init__()
# model = models.resnet18(True)
# model.avgpool = nn.AdaptiveAvgPool2d(1)
# model.fc = nn.Linear(512, 18)
# self.resnet = model
model = EfficientNet.from_pretrained('efficientnet-b0')
model._fc = nn.Linear(1280, 18)
self.resnet = model
def forward(self, img):
out = self.resnet(img)
return out
def validate(val_loader, model, criterion):
model.eval()
losses = []
with torch.no_grad():
end = time.time()
for i, (input, target) in enumerate(val_loader):
input = input.cuda()
target = target.cuda()
# compute output
output = model(input)
loss = criterion(output, target)
losses.append(loss.item())
end = time.time()
# TODO: this should also be done with the ProgressMeter
print('Val: ', np.mean(losses))
return np.mean(losses)
def train(train_loader, model, criterion, optimizer, epoch):
model.train()
end = time.time()
losses = []
for i, (input, target) in enumerate(train_loader):
input = input.cuda(non_blocking=True)
target = target.cuda(non_blocking=True)
# compute output
output = model(input)
loss = criterion(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
losses.append(loss.item())
# measure elapsed time
end = time.time()
if i % 100 == 0:
print('Train, Time: {0}, Loss: {1}'.format(end, np.mean(losses)))
skf = KFold(n_splits=10, random_state=233, shuffle=True)
for flod_idx, (train_idx, val_idx) in enumerate(skf.split(train_df['filename'].values, train_df['filename'].values)):
# print(flod_idx, train_idx, val_idx)
if flod_idx in [0, 1, 2, 3]:
continue
train_loader = torch.utils.data.DataLoader(
CatDataset(train_df.iloc[train_idx],
transforms.Compose([
transforms.Resize((512, 512)),
transforms.ColorJitter(hue=.05, saturation=.05),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
), batch_size=10, shuffle=True, num_workers=10, pin_memory=True
)
val_loader = torch.utils.data.DataLoader(
CatDataset(train_df.iloc[val_idx],
transforms.Compose([
transforms.Resize((512, 512)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
), batch_size=10, shuffle=False, num_workers=10, pin_memory=True
)
model = CatNet().cuda()
# model.load_state_dict(torch.load('resnet18_pretrain_fold0.pt'))
model = model.cuda()
# model = nn.DataParallel(model).cuda()
criterion = nn.MSELoss(size_average=False)
optimizer = torch.optim.Adam(model.parameters(), 0.001)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.85)
best_acc = 10.0
for epoch in range(1):
print('Epoch: ', epoch)
train(train_loader, model, criterion, optimizer, epoch)
val_loss = validate(val_loader, model, criterion)
if val_loss < best_loss:
best_loss = val_loss
torch.save(model.state_dict(), './resnet18_fold{0}.pt'.format(flod_idx))
scheduler.step()
def predict(test_loader, model, tta=10):
model.eval()
test_pred_tta = None
for _ in range(tta):
test_pred = []
with torch.no_grad():
end = time.time()
for i, input in enumerate(test_loader):
input = input.cuda()
# compute output
output = model(input)
output = output.data.cpu().numpy()
test_pred.append(output)
test_pred = np.vstack(test_pred)
if test_pred_tta is None:
test_pred_tta = test_pred
else:
test_pred_tta += test_pred
return test_pred_tta
test_jpg = ['./test/{0}.jpg'.format(x) for x in range(0, 9526)]
test_jpg = np.array(test_jpg)
test_pred = None
for model_path in ['./resnet18_fold4.pt']:
test_loader = torch.utils.data.DataLoader(
CatDataset(pd.DataFrame({'filename':test_jpg}),
transform = transforms.Compose([
transforms.Resize((512, 512)),
# transforms.RandomHorizontalFlip(),
# transforms.RandomVerticalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
], ), train=False
), batch_size=20, shuffle=False, num_workers=10, pin_memory=True
)
model = CatNet().cuda()
model.load_state_dict(torch.load(model_path))
# model = nn.DataParallel(model).cuda()
if test_pred is None:
test_pred = predict(test_loader, model, 1)
else:
test_pred += predict(test_loader, model, 1)
# test_csv = pd.DataFrame()
# test_csv[0] = list(range(0, 1047))
# test_csv[1] = np.argmax(test_pred, 1)
# test_csv.to_csv('tmp.csv', index=None, header=None)
test_pred = pd.DataFrame(test_pred)
test_pred.columns = ['left_eye_x', 'left_eye_y', 'right_eye_x', 'right_eye_y',
'mouth_x', 'mouth_y', 'left_ear1_x', 'left_ear1_y', 'left_ear2_x',
'left_ear2_y', 'left_ear3_x', 'left_ear3_y', 'right_ear1_x',
'right_ear1_y', 'right_ear2_x', 'right_ear2_y', 'right_ear3_x',
'right_ear3_y']
test_pred = test_pred.reset_index()
img_size = []
for idx in (range(9526)):
img_size.append(cv2.imread('./test/{0}.jpg'.format(idx)).shape[:2])
img_size = np.vstack(img_size)
test_pred['height'] = img_size[:, 0]
test_pred['width'] = img_size[:, 1]
for col in test_pred.columns:
if '_x' in col:
test_pred[col]*=test_pred['width']
elif '_y' in col:
test_pred[col]*=test_pred['height']
test_pred.astype(int).iloc[:, :-2].to_csv('tmp.csv', index=None, header=None)