【数据分析】预测泰坦尼克号存活率 -- Python决策树
此博客仅为我业余记录文章所用,发布到此,仅供网友阅读参考,如有侵权,请通知我,我会删掉。

前言
最近学习了 预测泰坦尼克号存活率,是一个烂大街的项目了,它是kaggle科学竞赛网站上一个入门的数据分析案例。
下图引用于kaggle-泰坦尼克号存活率预测项目。

文章流程
考虑到文章篇幅的原因,这里就不去预测哪些人更可能存活下来,将写另外一篇文章去做它。
-
数据概览
-
清洗数据
2.1 数据预处理
2.2 特征选择
-
决策树建模(至于什么是决策树,参考百度百科–决策树。)
-
预测结果
-
决策树可视化
1. 数据概览
数据从数据科学竞赛平台kaggle获取。kaggle-泰坦尼克号存活率预测项目。
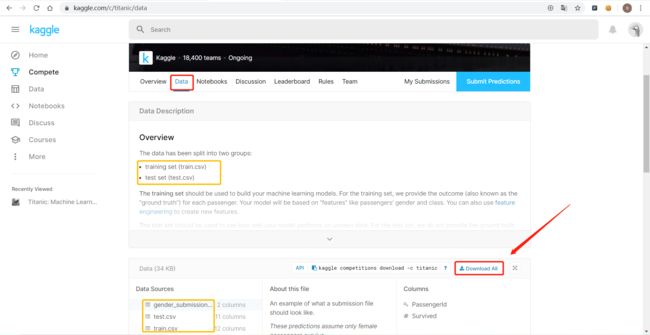
如下图所示,点击下载即可。
下载的数据有gender_submission.csv和test.csv以及train.csv三个文件。
- train为训练集,是用来分析和构建机器学习模型,包含有存活情况信息;
- test为测试集,不提供存活信息,项目目的就是预测该文档中的乘客的存活率;
- gender_submission文档是没用的,可以忽略。
两个文档的数据概览如下:
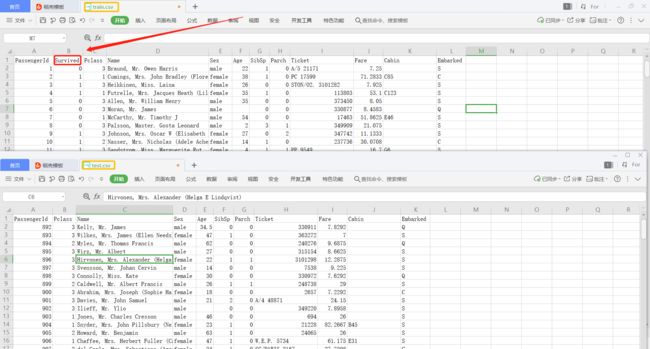
可以看到数据整体上都一样,唯一不同的地方在于 train.csv多了Survived这一列(即存活)。
那文档中各个字段代表的是什么意思呢?
| 字段 | 定义 | Key |
|---|---|---|
| Passengerld | 乘客编号 | |
| Survival | 存活与否 | 0 = No, 1 = Yes |
| Pclass | 船票级别 | class 1 = 1st, 2 = 2nd, 3 = 3rd |
| Name | 乘客姓名 | |
| Sex | 性别 | |
| Age | 年龄 | |
| Sibsp | 乘客兄妹 / 配偶 | |
| Parch | 乘客父母 / 子女 | |
| Ticket | 船票号码 | |
| Fare | 船票价格 | |
| Cabin | 船舱号 | |
| Embarked | 登船港口 | C = Cherbourg, Q = Queenstown, S = Southampton |
2. 清洗数据
2.1 数据预处理
导入数据:
import pandas as pd
test_pd = pd.read_csv('test.csv')
train_pd = pd.read_csv('train.csv')
查看数据集基本信息:
# 查看数据几行几列
print('train数据集的行数和列数:',train_pd.shape)
# 间隔
print('- ' * 20)
# 查看索引dtype和列dtype,非空值和内存使用情况
print(train_pd.info())
# 查看文档中各列的缺失值总数
print('- ' * 20)
print(train_pd.isnull().sum())
result:
- 可以看到train文档是(891行,12列)
- Age、Cabin、Embarked字段都存在空值,这个后面是需要填充的。
train数据集的行数和列数: (891, 12)
- - - - - - - - - - - - - - - - - - - -
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
None
- - - - - - - - - - - - - - - - - - - -
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64
Age可以用平均值填充;
# 使用平均年龄来填充年龄中的nan值
train_pd['Age'].fillna(train_pd['Age'].mean(), inplace=True)
Cabin缺失太多,不好补充,遂填充为unknown,意为未知的;
# 填充缺失值为unknown
train_pd['Cabin'].fillna('unknown', inplace=True)
Embarked缺失2个,可选择删除对应行或者填充处出现次数最高的值。
# 查看Embarked的值出现的次数
print(train_pd['Embarked'].value_counts())
result:
S 646
C 168
Q 77
Name: Embarked, dtype: int64
# 填充缺失值为S
train_pd['Embarked'].fillna('S', inplace=True)
填充缺失之后,可以看到已经没有空值了。

2.2 特征选择
该项目的主要目的是预测乘客存活率,所以这一步需要从数据集中选择特征,作为预测存活率的关键。
除了画框的这一列(存活率),还有剩余11个特征。
根据我不成熟的思考后判断得出:
- PassengerId为乘客编号,与存活率相关性不大,可去掉;
- Name为乘客姓名,对分类不起什么作用,可去掉;
- Ticket为船票号码,并且无命名规律,可去掉;
- Cabin为船舱号,缺失值太多,也去掉。
最后剩下 Pclass、Sex、Age、SibSp、Parch 和 Fare,Embarked 7个特征,他们可能和乘客的存活率的分类有关,但具体是什么关系,这个交给机器学习去头疼吧!
(1)将上面说的可去掉的特征删除:
train_pd.drop(["PassengerId","Cabin","Name","Ticket"],inplace=True,axis=1)
这时候的数据是这样的。

特征值里有一些不是数值类型,为方便后续的运算这里需要将他转换为数值类型。
Sex 字段,的男和女,用 0 或 1 来表示。
Embarked 的 S、C、Q ,用数值 0、1和2 来表示。
(2)将’Age’改成数值类型。
train_pd['Sex'] = train_pd['Sex'].map({'male': 0, 'female': 1}).astype(int)
(3)将’Embarked’改成数值类型。
# 方法一
train_pd['Embarked'] = train_pd['Embarked'].map( {'S': 0, 'C': 1,'Q':2},).astype(int)
# 方法二
#用unique将Embarked的唯一值转化为list, 然后用索引进行数字替换
labels = train_pd["Embarked"].unique().tolist()
train_pd["Embarked"] = train_pd["Embarked"].apply(lambda x: labels.index(x))
处理后的数据如下:
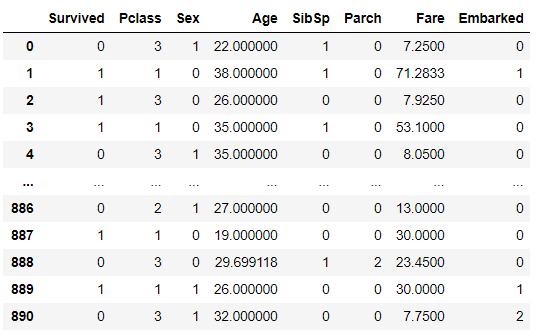
3. 决策树建模
到这一步,只需要将特征矩阵和标签塞到决策树模型里面就完事了。
特征矩阵是不包括存活率的,所以这里要删除Survived这一行。
分类标识也就是Survived这一列。
# 特征矩阵
train_labels = train_pd["Survived"]
# 分类标识
train_pd = train_pd.drop(['Survived'], axis=1)
导入决策树模块
from sklearn.tree import DecisionTreeClassifier
# 构建决策树
clf = DecisionTreeClassifier(criterion="entropy")
# 决策树训练
clf.fit(train_pd, train_labels)
百度百科–交叉验证

简单来说,K折交叉验证可以提高决策树的准确度。
cross_val_score 函数中的参数 cv 代表对原始数据划分成多少份,也就是K值,这里使用cv=10
from sklearn.model_selection import cross_val_score
print(cross_val_score(clf, train_pd, train_labels, cv=10).max()) # 最大值
print(cross_val_score(clf, train_pd, train_labels, cv=10).min()) # 最小值
print(cross_val_score(clf, train_pd, train_labels, cv=10).mean()) # 平均值
# 0.8539325842696629
# 0.6853932584269663
# 0.7744569288389513
然后接下来还可以使用GridSearchCV 调参,它存在的意义就是自动调参,只要把参数输进去,就能给出最优化的结果和参数。感兴趣的可以从网上学习。
因为这个不熟悉,不敢误人子弟。遂直接采用别人的答案!
经GridSearchCV 调参后,得出决策树的 criterion=‘gini’,max_depth=9,min_samples_leaf=6 的时候,准确度最高。
这里也可以明显看到,准确度是有所提高的。
clf = DecisionTreeClassifier(criterion='gini', min_samples_leaf=5, max_depth=9)
print(cross_val_score(clf, train_pd, train_labels, cv=10).max())
print(cross_val_score(clf, train_pd, train_labels, cv=10).min())
print(cross_val_score(clf, train_pd, train_labels, cv=10).mean())
# 0.8876404494382022
# 0.7528089887640449
# 0.8317103620474408
4. 预测结果
对测试集进行数据清洗。
# 导入数据集
test_pd = pd.read_csv('test.csv')
# 填充缺失值
test_pd ["Age"] = test_pd ["Age"].fillna(test_pd ["Age"].mean())
test_pd ["Fare"] = test_pd ["Fare"].fillna(test_pd ["Fare"].mean())
test_pd ['Embarked'] = test_pd ['Embarked'].fillna('S')
# 删除不需要的特征
test_pd.drop(["PassengerId","Cabin","Name","Ticket"],inplace=True,axis=1)
#
test_pd['Sex'] = test_pd['Sex'].map({'male': 0, 'female': 1}).astype(int)
test_pd['Embarked'] = test_pd['Embarked'].map( {'S': 0, 'C': 1,'Q':2},).astype(int)
预估结果:
test_pd['Survived']=pd.DataFrame(clf.predict(test_pd))
此时的数据如下:
看看存活率如何:
# 训练集存活率
Survived = train_pd['Survived'].value_counts(normalize=True)
print(f'训练集:死亡率{Survived[0]:.3%} ,存活率{Survived[1]:.3%}')
# 测试集存活率
Survived = df_test['Survived'].value_counts(normalize=True)
print(f'测试集:死亡率{Survived[0]:.3%} ,存活率{Survived[1]:.3%}')
result:
- 可以看到,训练集和测试集的差别是不大的。
训练集:死亡率61.616% ,存活率38.384%
测试集:死亡率62.679% ,存活率37.321%
5. 决策树可视化
后面再补上。
后话
分类树预测经典实例——泰坦尼克号幸存者预测,部分参考该文章。
如上,因为学习的不够深入,所以分享出来的也很菜。
文章多有不通之处,还请各位不吝赐教。
本次分享到此结束。纯当个人笔记,不可做为系统学习以及学习参考!!!