爬虫进阶 之 Scrapy 框架 3(scrapy spider 基类 实例:前程无忧招聘信息的爬取)
spiderl类
- 了解spider 类
- 实例:前程无忧爬取
- 案例升级
了解spider 类
我们先来看看这个类的一些重要的源码,具体讲解注释在代码里
# 部分源码,spider类,
class Spider(object_ref):
# 这就是我们的爬虫名,我们继承这个类的方法,
name = None
custom_settings = None
def __init__(self, name=None, **kwargs):
if name is not None:
self.name = name
elif not getattr(self, 'name', None):
raise ValueError("%s must have a name" % type(self).__name__)
self.__dict__.update(kwargs)
if not hasattr(self, 'start_urls'):
self.start_urls = []
def start_requests(self):
cls = self.__class__
if not self.start_urls and hasattr(self, 'start_url'):
raise AttributeError(
"Crawling could not start: 'start_urls' not found "
"or empty (but found 'start_url' attribute instead, "
"did you miss an 's'?)")
if method_is_overridden(cls, Spider, 'make_requests_from_url'):
warnings.warn(
"Spider.make_requests_from_url method is deprecated; it "
"won't be called in future Scrapy releases. Please "
"override Spider.start_requests method instead (see %s.%s)." % (
cls.__module__, cls.__name__
),
)
# 这就是我们定义的起始url列表,我们程序启动的时候,爬虫类就会执行这个方法,
# 生成Requests,交给Scrapy下载并返回response,该方法只调用一次
for url in self.start_urls:
yield self.make_requests_from_url(url)
else:
for url in self.start_urls:
yield Request(url, dont_filter=True)
# 这个就是生成Request, 如果我们代码里写了这个,就相当于重写了父类方法,把这个覆盖了,dont_filter = true 表示不做去重工作
def make_requests_from_url(self, url):
""" This method is deprecated. """
return Request(url, dont_filter=True)
# 用来处理响应文件,所以我们自己写一个python方法来处理,我们其实也是重写了这个东东
def parse(self, response):
raise NotImplementedError('{}.parse callback is not defined'.format(self.__class__.__name__))
#############################################################
############################################################
可以看到,这个就是另一个源码中的Request类,
class Request(object_ref):
def __init__(self, url, callback=None, method='GET', headers=None, body=None,
cookies=None, meta=None, encoding='utf-8', priority=0,
dont_filter=False, errback=None, flags=None, cb_kwargs=None):
主要属性和方法
-
name
定义我们爬虫的名称 -
allowed_domains
包含了允许爬取的域名列表,可选写 -
start_urls
起始 url 列表, 爬取就是从这里开始的 -
start_requests
该方法返回一个可以迭代的对象,该对象包含spider对象用于爬取的 第一个Request -
parse
如果响应没有指定的回调函数,就用这个来解析我们返回的response
实例:前程无忧爬取
我们爬取的就是这个网站 前程无忧
第一步还是创建项目和爬虫。
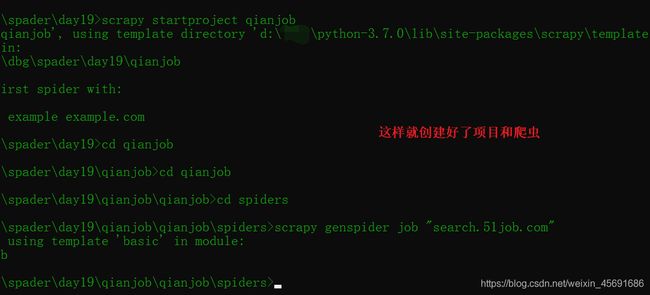
然后我们可以打开要爬取的网页,换一换页码来看看有什么规律
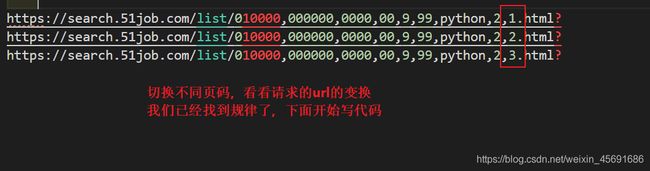
找到了规律,我们就可以用利用这个规律来翻页了。
我们一共要保存的内容是 值位名称,公司名称,工作地点,发布时间,工资。所以我们先来写我们的 item.py
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class QianjobItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# pass
# 值位名字
positionName = scrapy.Field()
# 值位详情连接
positionLink = scrapy.Field()
# 公司名
companyName = scrapy.Field()
# 工作地点
workplace = scrapy.Field()
# 工资
salary = scrapy.Field()
# 发布时间
publishTime = scrapy.Field()
再次强调一下,item 就是一个scrapy 的类,类似于python 的字典,但不完全是字典,我们用来保存信息并交给管道处理
下面可以正式写爬虫的解析了 job.py ,看图中的结构,然后如果怕写错可以再 scrapy shell 里面试一试, 这个昨天已经学过了
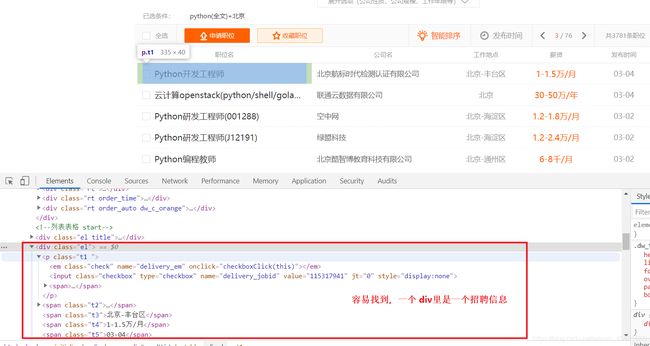
最后还有一个翻页的问题,就要用到上面说的 Request 这个类,并发送出去,
# -*- coding: utf-8 -*-
import scrapy
from qianjob.items import QianjobItem
class JobSpider(scrapy.Spider):
name = 'job'
allowed_domains = ['search.51job.com']
url = 'https://search.51job.com/list/010000,000000,0000,00,9,99,python,2,{}.html?'
page = 1
start_urls = [url.format(page)] # 起始页改为我们这个
def parse(self, response):
# pass
joblist = response.xpath('//div[@class="el"]')
for job in joblist[4:]: # 前四个空的,没有东西
item = QianjobItem()
# 值位名字
item['positionName'] = job.xpath('./p/span/a/text()').extract()[0]
# 值位详情连
item['positionLink'] = job.xpath('./p/span/a/@href').extract()[0]
# 公司名
item['companyName'] = job.xpath(
'./span[@class="t2"]/a/text()').extract()[0]
# 工作地点
item['workplace'] = job.xpath(
'./span[@class="t3"]/text()').extract()[0]
# 工资 有的公司没有写工资,所以有一个 indexerror 我们处理一下
salary = job.xpath(
'./span[@class="t4"]/text()').extract()
salary.append(' ')# 给它加个空格字段,这样就好了
item['salary'] = salary[0]
# 发布时间
item['publishTime'] = job.xpath(
'./span[@class="t5"]/text()').extract()[0]
yield item
# 给引擎后,引擎返回给管道了,现在写管道
# 我们还要遍历爬取好多页
if self.page < 10:
self.page +=1
url = self.url.format(self.page)
yield scrapy.Request(url,callback= self.parse)
# scrapy 构建了一个请求,回调函数还是 parse 用 yield 发出去给了调度器
注意 翻页是写在for 循环外面的,工作顺序就是 先爬取一页,在for循环中解析,直到解析完后,更新url 自己写一个Request,他的回调函数还是我们parse这个,即还是用这个解析但是,url 更新了。
在这个之后,就可以写我们的管道保存到本地了
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
import json
class QianjobPipeline(object):
def __init__(self):
# self.f = open("qianjob.json", 'wb')
def process_item(self, item, spider):
content = json.dumps(dict(item), ensure_ascii=False)+",\n"
self.f.write(content.encode("gbk"))
return item
def close_spider(self, spider):
self.f.close()
注意:我们用了管道后当然还要去 setting里 打开管道吖,这样才能工作。
好了,一切准备就绪,scrapy crawl job 在项目位置运行这个,成功,✌
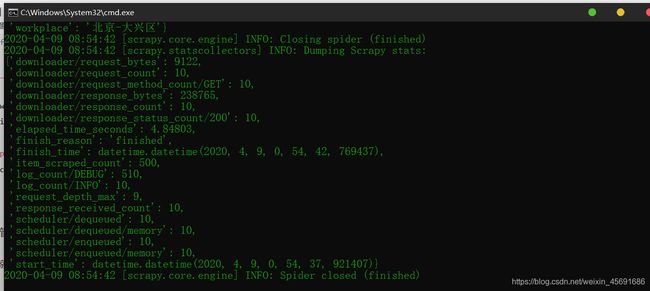
看看我们的数据

json 的好像不是很好看,有兴趣的可以保存成csv。
案例升级
这个案例就到这里了,但是,容易发现这个爬取方法有缺陷,爬的页数要我们自己指定,所以,我们下面看看,让他自动获取下一页的url 这样就高级了许多
我们正常就是点击下一页,所以我们这次获取下一页的连接,同样是用xpath就好
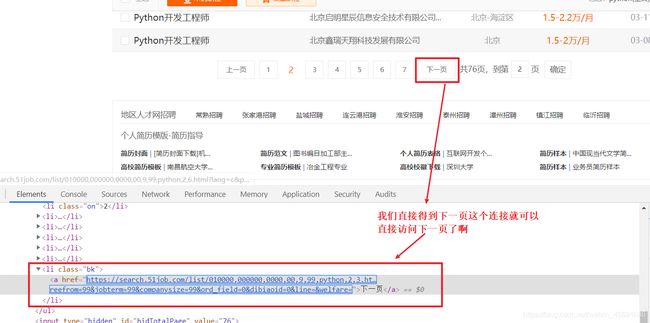
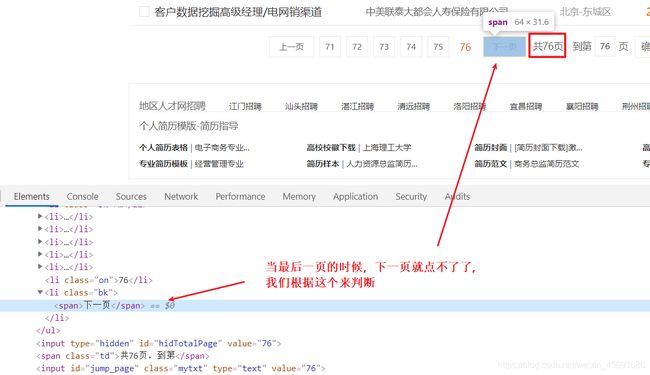
现在可以看代码了,我们只需要把刚才翻页的代码换成下面这个就可以了啊,
if len(response.xpath('//li[@class="bk"][2]/a/@href')) != 0:
url = response.xpath('//li[@class="bk"][2]/a/@href').extract()[0]
yield scrapy.Request(url, callback=self.parse)
前面只是我们粗略的学习了相关使用,后面我们会详细学习每个部分,下次我们会学习 scrapy的下载中间件
我又来要赞了,还是希望各位路过的朋友,如果觉得可以学到些什么的话,点个赞再走吧,欢迎各位路过的大佬评论,指正错误,也欢迎有问题的小伙伴评论留言,私信。每个小伙伴的关注都是我更博的动力》》》》奥里给