【数说·大数据圈】机器学习在生物大数据应用的一个例子 文/飞扬
下面不是我写的我只是做了点笔记。
作者:飞扬,生物圈女博士一枚,数说工作室特约撰稿人,关注领域:生物、健康、图像识别、大数据
前不久,华大基因宣布前CEO王俊“辞职但未离职”,将转战“基因测序+人工智能”领域。
撇开阴谋论和各种传言不谈,让我们把焦点放在科学上——基因测序和人工智能可以擦出怎样的火花?也是在几天前,有一家生物大数据的创业公司出现在媒体和公众的视线中——Deep Genomics。这个公司是干嘛的呢?简单来说就是:
利用机器学习的方法,预测基因组上的变化会对人体的特征/疾病/表型产生怎样的影响。
这就是本文要说的,机器学习在生物大数据上应用的一个例子。那么它是如何实现的呢?可以概括为两步:
(1)确定与某个特征/疾病/表型相关的基因易感位点。
我们每个人所带的基因是差不多的,之所以有的人卷发,有的人直发,有这么丰富多彩的变化,就是因为基因发生了改变,所以严格来说,我们要找的是基因的“多态性”。
(2)以这些基因易感位点数据作为输入变量,相关的特征/疾病/表型为响应变量,训练机器学习模型。
简单两步,但却蕴含着大数据、机器学习、统计学的精粹利用,现在逐一来分析。
1. 确定与某个特征/疾病/表型相关的基因易感位点。
这一步如何做?目前较流行的当属GWAS,所谓GWAS,是指全基因组关联分析(Genome-wide association study),是一种对全基因组范围内的常见遗传变异基因总体关联分析的方法。
目前,科学家已经对糖尿病、冠心病、肺癌、前列腺癌、肥胖、精神病等多种复杂疾病进行了GWAS分析,并找到了疾病相关的多个易感位点。看一下下面的图: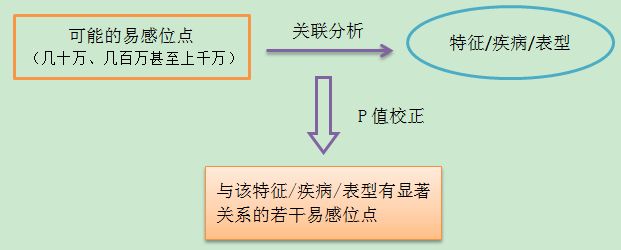
简单来说,塞一大堆的基因易感位点数据(几十万、几百万也可能上千万个易感位点),和要分析的这个特征/疾病/表型数据,然后建立模型分析找到存在显著关系的那个易感位点。
这有点类似于,我们有身高、学历、职业三个潜在影响变量,要从这三个变量中找出:哪个变量与收入存在显著关系、进而可能决定了收入。这里身高、学历、职业三个变量就相当于易感位点(只不过我们的潜在易感位点有几十万甚至几百万,所以才是生物大数据嘛),收入就相当于特征/疾病/表型。
模型可以选择卡方检验,或者logistic模型等等(模型的选择取决于你的表型)。值得注意的是,这里的显著性水平不再是0.05了,因为几百万个位点的分析,5%的显著性水平太低,此时要做P值的校正(在微信公众号shushuojun中回复“校正”)。
最终,我们选出来了对这个特征/疾病/表型有决定作用的一个或多个基因易感位点。
举一个例子,我们知道高血压是有遗传性的,既然有遗传学,就说明一定有基因的作用在里面,2009年,在nature genetics的一篇论文中,作者就是用GWAS找到了和高血压相关的几个SNP。这篇论文的名字也很直白:
“Genome-wideassociation study identifies eight loci associated with blood pressure”。
2. 用机器学习模拟特征/疾病/表型的变化
通过第一步的GWAS分析,我们知道哪些基因组的变化会一起一些特征/疾病/表型的改变。
在此基础上,我们就可以构建机器学习的算法,以基因组数据为输入变量、以特征/疾病/表型的数据为输出变量,利用大规模的训练数据去训练模型,以预测基因组的突变会如何改变细胞,进而改变动物和人体的表现。
前面说到的生物创业公司DeepGenomics,他们的第一个产品是SPIDEX,就是预测基因组突变对RNA剪切的影响。
基因组突变→ RNA剪切
再举一个例子,有的人天生能喝酒,有的人一沾酒就脸红。这也是有基因在起作用的,酒精在人体先分解成有毒的乙醛,再通过乙醛脱氢酶分解成无害的乙酸。因此,乙醛脱氢酶的活性就决定了解酒能力。为什么每个人的乙醛脱氢酶活性能力不一样?这是因为人体ALDH2基因的rs641这个点发生了改变。同样,我们或许可以利用机器学习的算法,训练大规模数据去预测乙醛脱氢酶的活性能力的表现。
综上所述,我们用GWAS找到了跟某个特征/疾病/表型相关的基因,然后在大规模样本数据中训练机器学习算法,用基因的突变去预测细胞层面的改变。
【1】Deep Genomics:http://www.deepgenomics.com/
【2】GWAS:如果在患者中某基因型的变异很频繁,那么就说该变异与该疾病“相关”。相关的遗传变异所在的人类基因组区域被视为标示点,基因组的该区域可能是致病原因的所在。有两种方法用来寻找疾病相关的突变:假说驱动和非假设驱动的方法。假设驱动的方法为一开始假设一个特殊的基因可能与某种疾病有关,并试图找出关联。非假设驱动的研究用蛮力的方法来扫描整个基因组,看哪些基因与该病有关联。GWAS一般采用非假说驱动。
【3】SNP:有的人吸烟喝酒却长寿,也有人自幼就病痛缠身;同一种治疗肿瘤的药物对一些人非常有效,对另一些人则完全无效。这是为什么?答案是他们基因组中存在的差异。这种差异很多表现为单个碱基上的变异,也就是单核苷酸的多态性(SNP)。
【4】SNV与SNP:
SNV仅在一些个体发现
SNP在人群中有一定概率