读书笔记:“集体智慧编程”之第三章:“发现群组”的 分级聚类
聚类
这章的主旨是数据聚类:聚集关系紧密的人或者事物。
聚类有什么好处呢?从推荐的角度来看,也是一种求相似用户的方式。此外,如果我们统计消费者此前购买的物品,再做一个聚类,就能分析出什么样的消费者会想要得到什么。如此抽象的描述非常不利于学习,不过下面本章第二个例子就能很好解释上面这句抽象的话。拭目以待吧。
聚类属于无监督学习(unsupervised learning),这不知道为什么这个词会被翻译成无监督,在我了解了这个含义之后,我倒认为无监督的学习和监督学习的最大区别就是是否产生了直接的结果。书中所言:无监督学习算法不是利用带有某种正确的答案样本数据进行‘训练’,它们的目的是要在一组数据中寻找某种结构,而这些结构本身不会告诉我们正在寻找的答案。而监督学习,我认为是利用样本的输入和样本自带的输出来训练模型,训练好之后,我们再传入一个类似输入的时候,那么模型就会为我们产生结果。这个结果和之前的训练有很大的关系。
无监督学习的算法有:
- 非负矩阵因式分解
- 自组织映射
监督学习法
- 神经网络
- 决策树
- 向量支持机
- 贝叶斯过滤
对博客聚类的例子
通过例子进行学习是我认为最好的方式,空洞的理论只会让人不明觉厉。
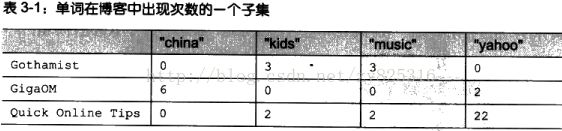
下面这个例子是要给一群博客聚类。依据也非常简单,我们根据不同的词在博客中出现的次数。词是我们规定的,我们认为这些词的在博客中出现的不同数量能够帮助我们鉴别博客的类型。本书也指出了如何构造这个数据集。最后构造出来的就是一个blogdata.txt的文档,下图是其的一个子集,第一列就是博客的名字。
分级聚类的原理
聚类的方式是多种多样的,我们第一种方式是分级聚类。
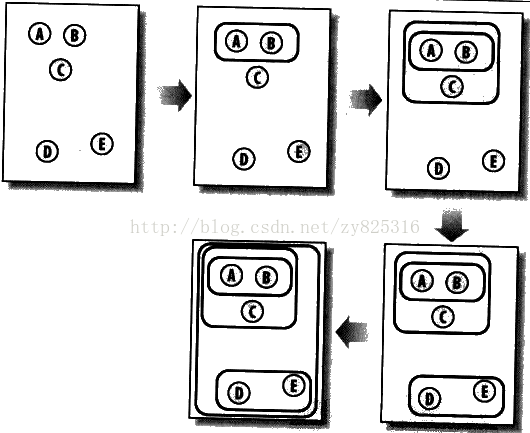
分级聚类是通过连续不断地将最为相似的群组两两合并,直到合并为一个为止。当然,最开始合并的时候只是两篇博客。下图展示了如何将5个元素合并的过程,A和B最开始最相似,所以合并成了一个。
在聚类完成后,我们会使用一种图形化的方式来展现所得到的结果。这次我们使用一种树状图的方式来表达最终聚类的情况。如下图所示:
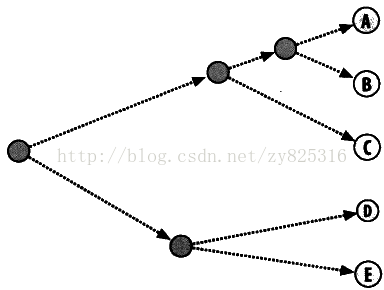
上图不仅能看出哪些元素属于一个类,还可以看出不同元素间相似的程度。比如A与B,它们合并成一个元素的距离远小于D和E合并成一个元素的距离。所以,A与B的紧密程度要大于D和E。
讲完原理就让我们开始吧。
读数据带内存
首先我们要讲blogdata.txt读入内存,代码如下:
def readfile(filename):
lines=[line for line in file(filename)]
#第一行是列标题,也就是被统计的单词是哪些
colnames=lines[0].strip().split('\t')[1:]#之所以从1开始,是因为第0列是用来放置博客名了
rownames=[]
data=[]
for line in lines[1:]:#第一列是单词,但二列开始才是对不同的单词的计数
p=line.strip().split('\t')
#每行都是的第一列都是行名
rownames.append(p[0])
#剩余部分就是该行对应的数据
data.append([float(x) for x in p[1:]])#data是一个列表,这个列表里每一个元素都是一个列表,每一列表的元素就是对应了colnames[]里面的单词
return rownames,colnames,data
计算相似度
下面我们就要计算两篇博客的相似度,在本个例子中我们使用pearson算法,这是因为每一篇博客的单词的总词数是不一样的,这就相当于在用户评价电影的体系中,某位用户打的分总是是偏高的情况,总词数偏多,那么相应地,我们想要统计的词数也会偏多,但是pearson算法完成可以修复者问题,这是因为pearson算法判断是两组数据和某一条直线的拟合程度。所以不会受到总的单词数偏多的情况下的干扰。
下面是计算代码:
def pearson(v1,v2):
#先求和
sum1=sum(v1)
sum2=sum(v2)
#求平方和
sum1Sq=sum([pow(v,2) for v in v1])
sum2Sq=sum([pow(v,2) for v in v2])
#求乘积之和
pSum=sum([v1[i]*v2[i] for i in range(len(v1))])
#计算pearson相关系数
num=pSum-(sum1*sum2/len(v1))
den=sqrt((sum1Sq-pow(sum1,2)/len(v1))*(sum2Sq-pow(sum2,2)/len(v1)))
if den==0:return 0
return 1.0-num/den#因为在本题中,我们想要相似度也大的两个元素的距离越近,所以才用1去减它们
聚类计算
为了画出图像,使用面向对象的思维来编程是非常方便的,我们将图中每一个节点都看成是一个对象。首先我们来定义一个类。
代码如下:
#图中每一个点都是一个该类的对象,而其中叶节点显然就是原始数据,而枝节点的数据主要来自其叶节点的均值。
class bicluster:
def __init__(self,vec,left=None,right=None,distance=0.0,id=None):
self.left=left
self.right=right
self.vec=vec#就是词频列表
self.id=id
self.distance=distance
接着,我们开始聚类计算,这也是一个比较耗时的过程,因为会对每一博客的相似度进行计算。实际上远不至每一对,还有新合并的节点。该函数会接受一个计算相似度的函数和一个列表数组,列表数组就是的就是所以博客的词频,词频又列表数组的形成存在,说直接一点就是上面生成的那个data列表数组。最后返回一个bicluster的对象,只有一个,但是这个对象是根节点,如果扩展其左右孩子,最后会得一个类似于上面的那副树状图。实际上最后我们就是要画出那个树状图。
代码如下:
def hcluster(rows,distance=pearson):
distances={}#每计算一对节点的距离值就会保存在这个里面,这样避免了重复计算
currentclustid=-1
#最开始的聚类就是数据集中的一行一行,每一行都是一个元素
#clust是一个列表,列表里面是一个又一个biccluster的对象
clust=[bicluster(rows[i],id=i) for i in range(len(rows))]
while len(clust)>1:
lowestpair=(0,1)#先假如说lowestpair是0和1号
closest=distance(clust[0].vec,clust[1].vec)#同样将0和1的pearson相关度计算出来放着。
#遍历每一对节点,找到pearson相关系数最小的
for i in range(len(clust)):
for j in range(i+1,len(clust)):
#用distances来缓存距离的计算值
if(clust[i].id,clust[j].id) not in distances:
distances[(clust[i].id,clust[j].id)]=distance(clust[i].vec,clust[j].vec)
d=distances[(clust[i].id,clust[j].id)]
if d
粗略的结果图
我们确实要画树状图,但是现在先写一份代码在控制台画出树状图。原来非常简单,反正每行打印一个,要么是分支,要么就是叶节点,然后就控制后缩进,越到后面缩进越大。
代码如下:
#我们急于验证上面的函数,所以先写一个简单的函数来打印节点,形式是和文件系统层级结构相关。
def printclust(clust,labels=None,n=0):
#利用缩进来建立层级布局
for i in range(n):print ' ',
if clust.id<0:
#负数代表这是一个分支
print '-'
else:
#正数代表这是一个叶节点
if labels==None: print clust.id
else:print labels[clust.id]
if clust.left!=None:printclust(clust.left,labels=labels,n=n+1)
if clust.right!=None:printclust(clust.right,labels=labels,n=n+1)
执行代码:
blognames,words,data=readfile('blogdata.txt')
clust=hcluster(data)
printclust(clust,labels=blognames)
执行结果:
>>>
-
gapingvoid: "cartoons drawn on the back of business cards"
-
-
Schneier on Security
Instapundit.com
-
The Blotter
-
-
MetaFilter
-
SpikedHumor
-
Captain's Quarters
-
Michelle Malkin
-
-
NewsBusters.org - Exposing Liberal Media Bias
-
-
Hot Air
Crooks and Liars
-
Power Line
Think Progress
-
Andrew Sullivan | The Daily Dish
-
Little Green Footballs
-
Eschaton
-
Talking Points Memo: by Joshua Micah Marshall
Daily Kos
-
43 Folders
-
TechEBlog
-
-
Mashable!
Signum sine tinnitu--by Guy Kawasaki
-
-
-
Slashdot
-
MAKE Magazine
Boing Boing
-
-
Oilman
-
Online Marketing Report
-
Treehugger
-
SimpleBits
-
Cool Hunting
-
Steve Pavlina's Personal Development Blog
-
-
ScienceBlogs : Combined Feed
Pharyngula
-
BuzzMachine
-
Copyblogger
-
-
The Viral Garden
Seth's Blog
-
-
Bloggers Blog: Blogging the Blogsphere
-
Sifry's Alerts
ProBlogger Blog Tips
-
-
Valleywag
Scobleizer - Tech Geek Blogger
-
-
O'Reilly Radar
456 Berea Street
-
Lifehacker
-
Quick Online Tips
-
Publishing 2.0
-
Micro Persuasion
-
A Consuming Experience (full feed)
-
John Battelle's Searchblog
-
Search Engine Watch Blog
-
Read/WriteWeb
-
Official Google Blog
-
Search Engine Roundtable
-
Google Operating System
Google Blogoscoped
-
-
-
-
Blog Maverick
-
Download Squad
-
CoolerHeads Prevail
-
Joystiq
The Unofficial Apple Weblog (TUAW)
-
Autoblog
-
Engadget
TMZ.com
-
Matt Cutts: Gadgets, Google, and SEO
-
PaulStamatiou.com
-
-
GigaOM
TechCrunch
-
-
Techdirt
Creating Passionate Users
-
Joho the Blog
-
-
PerezHilton.com
Jeremy Zawodny's blog
-
Joi Ito's Web
-
ongoing
-
Joel on Software
-
-
we make money not art
-
plasticbag.org
-
Signal vs. Noise
-
kottke.org
-
Neil Gaiman's Journal
-
-
The Huffington Post | Raw Feed
-
Wonkette
-
Gawker
-
The Superficial - Because You're Ugly
Go Fug Yourself
-
Deadspin
Gothamist
-
Kotaku
Gizmodo
-
Shoemoney - Skills to pay the bills
-
flagrantdisregard
-
WWdN: In Exile
-
Derek Powazek
-
lifehack.org
Dave Shea's mezzoblue
-
Wired News: Top Stories
-
Topix.net Weblog
Bloglines | News
>>>
画出树状图
实际上,到底,我们分级聚类已经学完了。但是为了使我们的结果更加易于观察,我们需要画出树状图。
准备工作:请将python画图的库文件PIL,windows下非常简单,直接下载对应版本,然后去安装即可。
第一步:就是计算出高度。书中提出的办法是,写一个函数计算有多少叶节点,一个叶节点的高度算1,如果不是叶节点肯定就是枝节点,而枝节点的高度就是叶节点之和。但是我观察了一下图,我觉得高度不就是整个叶节点之和么?每一个叶节点就是就是一个博客名字,那高度不就博客的个数么?为什么还写个函数去算呢?
代码如下:
def getheight(clust):
#这是一个叶节点吗?若是,则高度为1
if clust.left==None and clust.right ==None:return 1
#否则,高度为每个分支的高度之和
return getheight(clust.left)+getheight(clust.right)
知道高度之后就是知道宽度,之前我们提到过,每一个叶节点与枝节点的距离越远,表示两者两个元素的相似度越低。由此可见,在聚类过程中,叶节点到枝节点的距离是各不相同的,看起来肯定是没有那么工整。
代码如下:
def getdepth(clust):
#一个叶节点的距离是0.0,这是因为叶节点之后就没有了,将其放在最左边也没事
if clust.left==None and clust.right ==None:return 0
#而一个枝节点的距离等于左右两侧分支中距离较大的那一个
#加上自身距离:所谓自身距离,与就是某节点与两一节点合并时候的相似度
return max(getdepth(clust.left),getdepth(clust.right))+clust.distance
下面是画出那张大的背景图,在此,我们为每一个叶节点分配20个像素,但是整张图片的宽度,我们固定为了1200。
代码如下:
def drawdendrogram(clust,labels,jpeg='clusters.jpg'):
#高度和宽度
h=getheight(clust)*20
w=1200
depth=getdepth(clust)
#我们固定了宽度,所以需要对每一个节点的横向摆放做一个缩放,而不像高度一样,每一个叶节点都分配20
scaling=float(w-150)/depth
#新建一张白色的背景图片
img=Image.new('RGB',(w,h),(255,255,255))
draw=ImageDraw.Draw(img)
draw.line((0,h/2,10,h/2),fill=(255,0,0))#仅仅是画了一个起点
#画第一个节点
drawnode(draw,clust,10,(h/2),scaling,labels)
img.save(jpeg,'JPEG')
画布里面有一个函数叫做drawnode函数,这个函数接受的参数包括一个聚类,还有他的位置,当然画画的画笔,然后缩放因子,以及博客名称。这个函数是整个画图中的核心函数,所以请认真研究它。
def drawnode(draw,clust,x,y,scaling,labels):
if clust.id<0:
h1=getheight(clust.left)*20#两个分支的高度
h2=getheight(clust.right)*20
top=y-(h1+h2)/2#如果是第一次画点的话,top居然是最高点,也就是等于0。是上面边界。针对某一个节点,其高度就是左节点的高度加右节点的高度。
bottom=y+(h1+h2)/2#这个确实也是下边界。
#线的长度
ll=clust.distance*scaling
#聚类到其子节点的垂直线
draw.line((x,top+h1/2,x,bottom-h2/2),fill=(255,0,0))
#连接左侧节点的水平线
draw.line((x,top+h1/2,x+ll,top+h1/2),fill=(255,0,0))
#连接右侧节点的水平线
draw.line((x,bottom-h2/2,x+ll,bottom-h2/2),fill=(255,0,0))
#调用函数绘制左右节点
drawnode(draw,clust.left,x+ll,top+h1/2,scaling,labels)
drawnode(draw,clust.right,x+ll,bottom-h2/2,scaling,labels)
else:
#如果这是一个叶节点,则绘制节点的标签。其实现在突然觉得这种思路非常好。绘制的是标签,本题中绘制的博客名字
draw.text((x+5,y-7),labels[clust.id],(0,0,0))
执行代码如下所示:
blognames,words,data=readfile('blogdata.txt')
clust=hcluster(data)
drawdendrogram(clust,blognames,jpeg='分级聚类图.jpg')
最后我们可以得到一张图,如下所示。由于msdn限制的宽度的像素,真心想看的话,右键保存既可以。
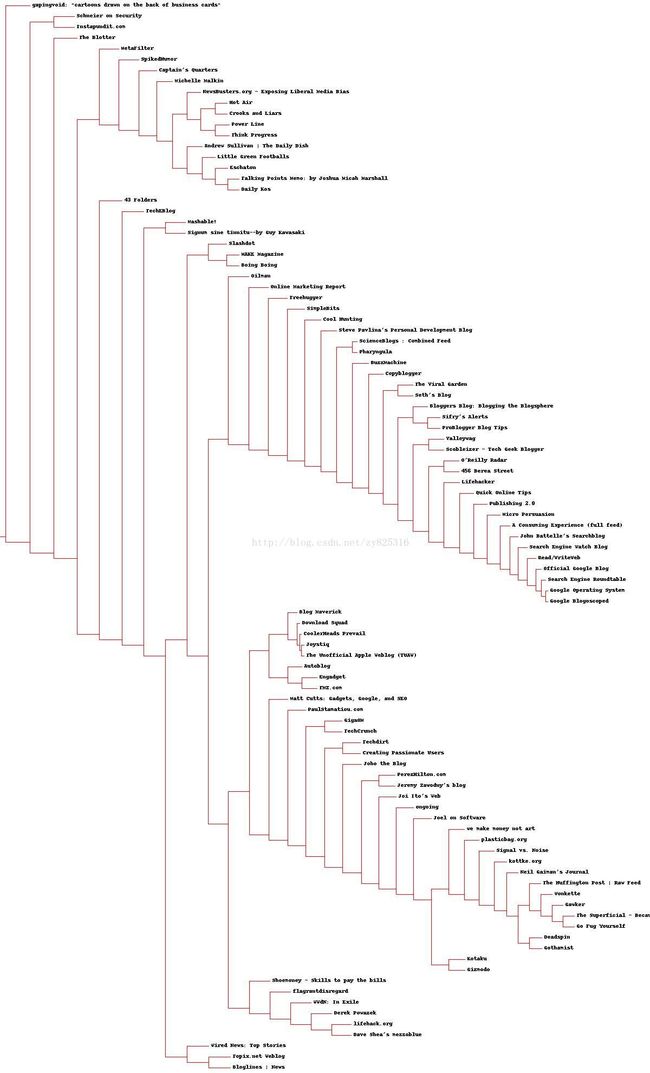
总结
内容并不难。原理不难,难在画最后那个树状图。
实际上关键的还是还是相似度计算,用相似度来判断是否属于一个类。这并不难以接受。关于分级聚类,就学习到这里吧。
由于我暂时没发现和项目的关系有多大,所以没太多思考。我唯一想到的和项目有关系的部分,就是我想在用户选艺人或者标签的时候,对出现的艺人或者标签做一个聚类分析,不让要一页里出现太多相似的艺人或者标签。
代码
from PIL import Image,ImageDraw
# -*- coding: cp936 -*-
def readfile(filename):
lines=[line for line in file(filename)]
#第一行是列标题,也就是被统计的单词是哪些
colnames=lines[0].strip().split('\t')[1:]#之所以从1开始,是因为第0列是用来放置博客名了
rownames=[]
data=[]
for line in lines[1:]:#第一列是单词,但二列开始才是对不同的单词的计数
p=line.strip().split('\t')
#每行都是的第一列都是行名
rownames.append(p[0])
#剩余部分就是该行对应的数据
data.append([float(x) for x in p[1:]])#data是一个列表,这个列表里每一个元素都是一个列表,每一列表的元素就是对应了colnames[]里面的单词
return rownames,colnames,data
from math import sqrt
def pearson(v1,v2):
#先求和
sum1=sum(v1)
sum2=sum(v2)
#求平方和
sum1Sq=sum([pow(v,2) for v in v1])
sum2Sq=sum([pow(v,2) for v in v2])
#求乘积之和
pSum=sum([v1[i]*v2[i] for i in range(len(v1))])
#计算pearson相关系数
num=pSum-(sum1*sum2/len(v1))
den=sqrt((sum1Sq-pow(sum1,2)/len(v1))*(sum2Sq-pow(sum2,2)/len(v1)))
if den==0:return 0
return 1.0-num/den#因为在本题中,我们想要相似度也大的两个元素的距离越近,所以才用1去减它们
#图中每一个点都是一个该类的对象,而其中叶节点显然就是原始数据,而枝节点的数据主要来自其叶节点的均值。
class bicluster:
def __init__(self,vec,left=None,right=None,distance=0.0,id=None):
self.left=left
self.right=right
self.vec=vec#就是词频列表
self.id=id
self.distance=distance
def hcluster(rows,distance=pearson):
distances={}#每计算一对节点的距离值就会保存在这个里面,这样避免了重复计算
currentclustid=-1
#最开始的聚类就是数据集中的一行一行,每一行都是一个元素
#clust是一个列表,列表里面是一个又一个biccluster的对象
clust=[bicluster(rows[i],id=i) for i in range(len(rows))]
while len(clust)>1:
lowestpair=(0,1)#先假如说lowestpair是0和1号
closest=distance(clust[0].vec,clust[1].vec)#同样将0和1的pearson相关度计算出来放着。
#遍历每一对节点,找到pearson相关系数最小的
for i in range(len(clust)):
for j in range(i+1,len(clust)):
#用distances来缓存距离的计算值
if(clust[i].id,clust[j].id) not in distances:
distances[(clust[i].id,clust[j].id)]=distance(clust[i].vec,clust[j].vec)
d=distances[(clust[i].id,clust[j].id)]
if d
代码、数据、结果已上传网盘:
- MyHierarchicalClusterAnalysis.py
- blogdata.txt
- 分级聚类的结果树状图图.jpg