python爬虫技术 使用redis搭建ip池代理
前言
爬虫爬取网页数据时由于频繁访问会被锁定IP,返回错误响应码以及验证字母验证,可以动态使用ip代理解决。
代理服务可以自己搭建,也可以购买收费的强力代理服务更靠谱。
这里是爬取的ip池示例:

项目来源GITHUB项目:jhao104/proxy_pool
下面示例win10下搭建项目
下载
安装redis:
windows下载地址:https://github.com/MicrosoftArchive/redis/releases
#下载zip解压即可
启动redis:运行redis-server.exe
Linux安装:sudo apt-get install redis-server
启动redis:运行redis-server启动成功:
安装项目:
#下载源码
git clone [email protected]:jhao104/proxy_pool.git
或者直接到
https://github.com/jhao104/proxy_pool
下载zip文件,解压出来安装依赖:
#进入项目目录执行pip命令 也可以手动安装
pip install -r requirements.txt
配置项目:
# Config/setting.py 为项目配置文件
# 配置DB
DATABASES = {
"default": {
"TYPE": "SSDB", # 如果使用SSDB或redis数据库,均配置为SSDB
"HOST": "127.0.0.1", # db host
"PORT": 6379, # db port redis默认6379
"NAME": "proxy", # 默认配置
"PASSWORD": "" # db password
}
}
# 配置 ProxyGetter
PROXY_GETTER = [
"freeProxyFirst", # 这里是启用的代理抓取函数名,可在ProxyGetter/getFreeProxy.py 扩展
"freeProxySecond",
....
]
# 配置 API服务
SERVER_API = {
"HOST": "0.0.0.0", # 监听ip, 0.0.0.0 监听所有IP
"PORT": 5010 # 监听端口
}
# 上面配置启动后,代理池访问地址为 http://127.0.0.1:5010启动项目:
# 如果你的依赖已经安全完成并且具备运行条件,可以直接在Run下运行main.py
# 到Run目录下:
>>>python main.py
# 如果运行成功你应该看到有4个main.py进程
# 你也可以分别运行他们,
# 依次到Api下启动ProxyApi.py,Schedule下启动ProxyRefreshSchedule.py和ProxyValidSchedule.py即可.启动查看抓取的ip:http://127.0.0.1:5010/get_all/
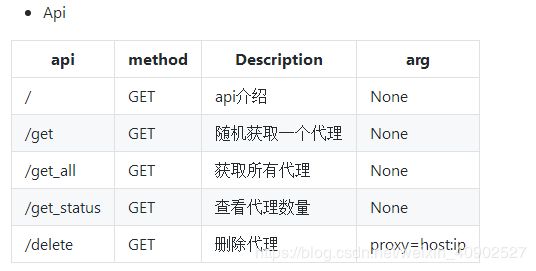
项目有提供api使用:
爬虫动态代理:
def get_proxy():
#可以换成我的Api
return requests.get("http://127.0.0.1:5010/get/").text
def getURL(self, url, redirects=False, tries_num=6, sleep_time=0.5, time_out=1000, max_retry=6, ):
#从ip池动态获取一个ip
proxy = get_proxy()
try:
res = requests.Session()
# res = requests.get(url,headers=self.randHeader(), allow_redirects=redirects, timeout=time_out)
res = requests.get(url,headers=self.randHeader(), allow_redirects=redirects, timeout=time_out, proxies={"http": "http://{}".format(proxy), "https": "https://{}".format(proxy)})
res.raise_for_status() # 如果响应状态码不是 200,就主动抛出异常
except requests.RequestException as e:
sleep_time_p = sleep_time_p + 10
time_out_p = time_out_p + 10
tries_num_p = tries_num_p - 1
# 设置重试次数,最大timeout 时间和 最长休眠时间
if tries_num_p > 0:
time.sleep(sleep_time_p)
print (self.getCurrentTime(), url, 'URL Connection Error: 第', max_retry - tries_num_p, u'次 Retry Connection', e)
return self.getURL(url, 'False', tries_num_p, sleep_time_p, time_out_p, max_retry)
return res