什么是Spring Cloud?
Spring Cloud 是Pivotal提供的用于简化分布式系统构建的工具集。Spring Cloud引入了云平台连接器(Cloud Connector)和服务连接器(Service Connector)的概念。云平台连接器是一个接口,需要由云平台提供者进行实现,以便库中的其他模块可以与该云平台协同工作。
Spring Boot
Spring Cloud最重要的一点是它可以和Spring Boot一起工作,Spring Boot可以帮助开发者更容易地创建基于Spring的应用程序和服务。
从Spring Boot项目名称中的Boot就可以看出来,Spring Boot的作用在于创建和启动新的基于Spring框架的项目。Spring Boot会选择最适合的Spring子项目和第三方开源库进行整合。大部分Spring Boot应用只需要非常少的配置就可以快速运行起来。Spring Boot包含的特性如下:
创建可以独立运行的Spring应用。
直接嵌入Tomcat或Jetty服务器,不需要部署WAR文件。
提供推荐的基础POM文件来简化Apache Maven配置。
尽可能的根据项目依赖来自动配置Spring框架。
提供可以直接在生产环境中使用的功能,如性能指标、应用信息和应用健康检查。
没有代码生成,也没有XML配置文件。
服务发现和智能路由
每一个服务都含有一个特定意义的微服务架构。当你在Spring Cloud上构建微服务架构时,这里有几个基本概念需要首先澄清下。首先,你需要要先创建Configuration Service和Discovery Service两个基础服务。如下图所示:
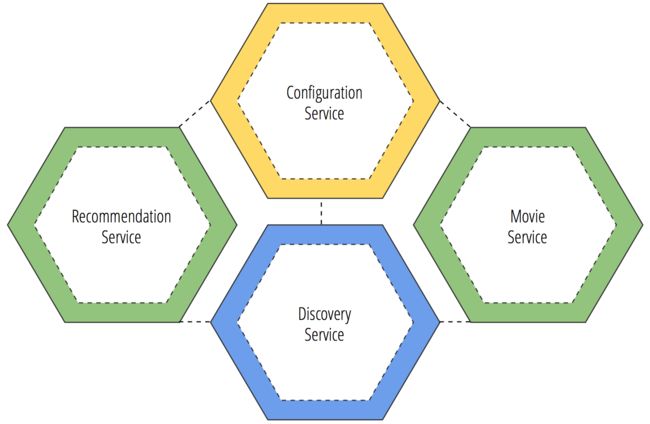
上面的图片说明了四个微服务以及各个服务之间的依赖关系。
Configuration service处于最顶端,黄色标识,而且被其它微服务所依赖。
Discovery service处于最低端,蓝色标识,同时也被其它服务所依赖。
绿色标识的两个微服务是我们本系列博文中用到的两个应用案例:电影和观影建议。
Configuration Service
Configuration Service在微服务架构中是一个非常重要的组件。如12要素应用理论所说, 微服务应用的配置应该存储在环境中,而不是本地项目中。
Configuration service(配置服务)是一个必不可少的基础组件的原因是因为它可以对所有通过点对点和检索的基础服务进行服务管理。
假设我们有多个部署环境。比如我们有一个临时环境和一个生产环境,针对每个环境的配置将会是不同的。每一个configuration service 将会由一个独立的Git仓库来存放环境配置。没有其它环境能够访问到这个配置仓库,它只是提供该环境中运行的配置服务罢了。
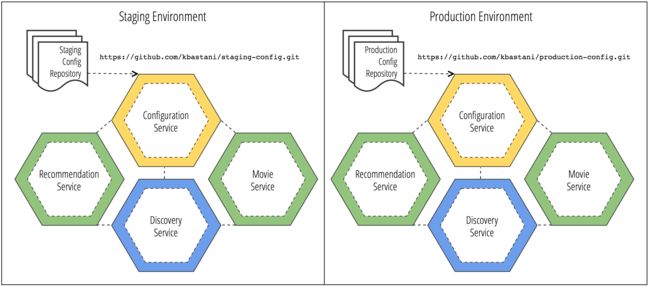
当Configuration service启动后,它将会指向那些根据配置文件配置的路径并启动对应服务。每一个微服务通过读取自己配置文件中的具体环境来运行。在这一过程中,配置是通过版本管理来进行的内部和集中化管理,更改配置不需要重启服务。
通过Spring Cloud提供的服务终端,你可以更改环境配置,并向Discovery service(发现服务)发送一个刷新信号,所有的用户都会收到新的配置通知。
Discovery Service
Discovery Service(发现服务)是另一个重要的微服务架构的组件。Discovery Service管理运行在容器中的众多服务实例,而这些实例工作在集群环境下。在这些应用中,我们使用客户端的方式称之为从服务到服务。举个例子,我使用Spring Cloud Feign ,这是一个基于Restful风格的微服务提供的客户端开源项目,它是从Netflix OSS project项目中派生出来的。
@FeignClient("movie") public interface MovieClient { @RequestMapping(method = RequestMethod.GET, value = "/movies") PagedResources findAll(); @RequestMapping(method = RequestMethod.GET, value = "/movies/{id}") Movie findById(@RequestParam("id") String id); @RequestMapping(method = RequestMethod.POST, value = "/movies", produces = MediaType.APPLICATION_JSON_VALUE) void createMovie(@RequestBody Movie movie); }
在上面的例子中,我创建了一个Feign 客户端,并映射了一个REST API方法来暴露电影服务。使用@FeignClient注解,可以声明我想要为movie微服务而创建的客户端API。接下来我声明了一个我想要实现的服务映射。通过在方法上声明一个URL规则来描述一个REST API的路由规则。
更令人兴奋的是,这一切在Spring Cloud中都很容易,我所要做的仅仅是知道service ID来创建我的Feign 客户端。服务的URL地址在运行时环境是自动配置的,因为每一个在集群中的微服务将会在启动时通过绑定serviceid的方式来进行注册。
微服务架构中的其它服务,也是通过上面提到的方式运行。我只需要知道进行通讯服务的serviceid,所有的操作都是通过Spring自动绑定的。
API Gateway
API Gateway 服务是Spring Cloud的另一个重要组件(关于它的介绍可以阅读本篇文章)。它可以用来管理集群服务中的领域实体。下图的绿色六边形是我们提供的数据驱动服务,主要用来管理自己的实体类和数据库。通过添加API Gateway服务,我们可以为通过下面绿颜色的服务为每一个API路由创建一个代理暴露接口。
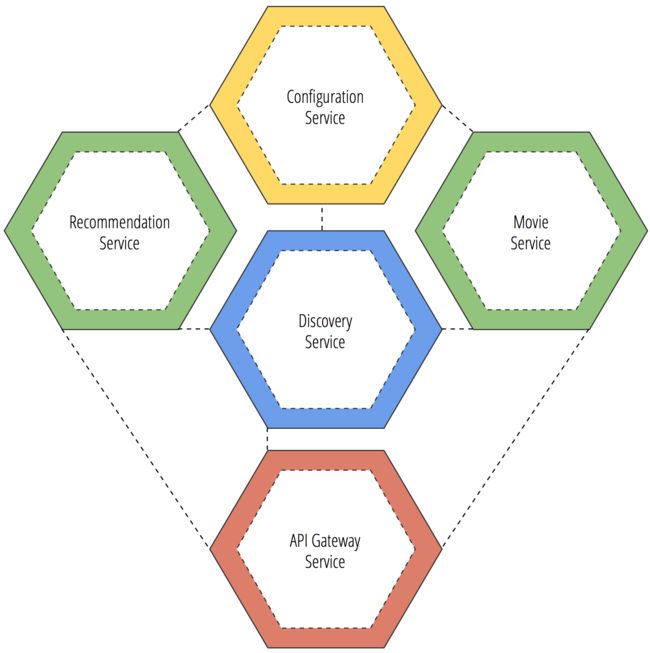
假设推荐服务和电影服务都暴露他们自己的REST API在自己管理的域实体上。API gataway通过discovery service和从其它服务注入的基于代理路由的 API方法。通过这种方式,包括推荐服务和电影服务将拥有一个完整定义的路由,通过暴露的REST API获得本地的微服务。API Gateway将会重定义路由请求到服务实例,这些请求都是基于HTTP的。
示例项目
我已经在GitHub上创建了一个实例项目:https://github.com/kbastani/spring-cloud-microservice-example,这个项目是一个端到端的原生云平台,使用Spring Cloud构建实际的微服务架构。
基本概念:
使用Docker进行集成测试
混合持久化
微服务架构
服务发现
API网关
Docker
使用Docker对每一个服务进行构建和部署。使用Docker Compose在一个开发机上进行端到端的集成测试。
混合持久化
混合持久化其实就是说使用多种数据库来存储。不同的微服务实例都会使用它们自己的数据库,并通过REST服务或者消息总线来通信,举个例子,你可以使用基于以下数据库来构建微服务:
Neo4j(图形化)
MongoDB(文档化)
MySQL(关联)
微服务架构
这个例子演示了如何使用微服务创建一个新的应用。由于在项目中的每一个微服务只有一个单一的父项目。开发者为此得到的收益是可以在本机上运行和开发每一个微服务。添加一个新的微服务非常简单,当发现微服务时将会自动发现运行时的集群环境上。
Service Discovery
项目中包含两个发现服务,一个在Netflix Eureka,另一个使用了
Consul from Hashicorp。多种发现服务提供了多种选择,一个是使用(Consul)来做DNS服务集群,另一个是(Consul)基于代理的API 网关。
API 网关
每一个微服务都关联Eureka,在整个集群中检索API路由。使用这个策略,每一个在集群上运行的微服务只需要通过一个共同的API网关进行负载均衡和暴露接口,每一个服务也会自动发现并将路由请求转发到自己的路由服务中。这个代理技术有助于开发用户界面,作为平台完整的 API通过自己的主机映射为代理服务。
Docker 实例
下面的实例将会通过Maven来构建,使用Docker为每一个微服务构建容器镜像。我们可以很优雅的使用Docker Compose在我们自己的主机上搭建全部的微服务集群。
开始构建
在这之前,请先移步至项目的GitHub 仓库。
https://github.com/kbastani/spring-cloud-microservice-example
克隆或者fork这个项目并且把源码下载到自己的电脑上。下载完毕后,你需要使用Maven和Docker来编译和构建本地的容器镜像。
下载Docker
首先,如果你还没有Docker请先下载它。可以跟随这个指南来获取Docker:https://docs.docker.com/installation/,然后在开发机上安装并运行。
当然你也需要安装Docker Compose(https//docs.docker.com/compose/),这个指南将会帮到你:https://docs.docker.com/compose/install/。
环境要求
能够运行实例程序,需要在你的开发机上安装下面的软件:
Maven 3
Java 8
Docker
Docker Compose
构建项目
通过命令行方式来构建当前项目,在项目的根目录中运行如下的命令:
$ mvn clean install
项目将会根据pom.xml中的每一个项目声明中下载相应的依赖jar包。每一个服务都将会被构建,同时Maven的Docker插件将会自动从本地Docker Registry中构建每一个容器镜像。Docker将会在构建成功后,根据命令行运行mvn clean install来清除相应的资源。
在项目成功构建后,你将会看到如下的输出:

通过Docker compose 启动集群
现在每一个镜像都成功构建完毕,我们使用Docker Compose来加速启动我们的集群。我已经将Docker Compose的yaml文件包含进了项目中,大家可以从GitHub上获取。
现在我们通过下面的命令行启动微服务集群:
$ docker-compose up
如果一切配置都是正确的,每一个容器镜像将会通过在Docker上的虚拟容器和自动发现的网络服务来运行。当他们开始顺序启动时,你将会看到一系列的日志输出。这可能需要一段时间来完成,取决于运行你实例程序的机器性能。
一旦容器启动成功,你将会通过Eureka主机看到通过Discovery service注册上来的应用服务。
通过命令行终端复制粘贴下面的命令到Docker中定义的$DOCKER_HOST环境变量中。
$ open $(echo \"$(echo $DOCKER_HOST)\"| \sed 's/tcp:\/\//http:\/\//g'| \sed 's/[0-9]\{4,\}/8761/g'| \sed 's/\"//g')
如果Eureka正确的启动,浏览器将会启动并打开Eureka服务的仪表盘,如下图所示:
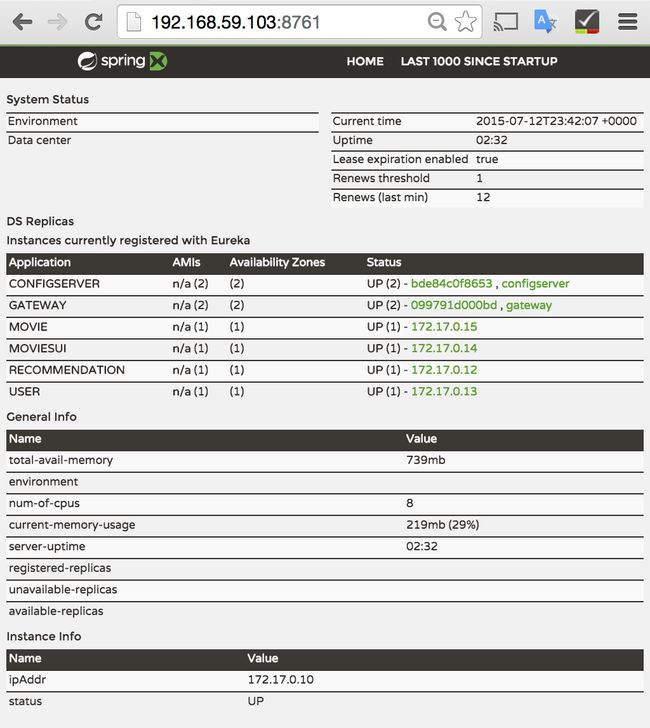
我们将会看到每一个正在运行的服务实例和状态。通过下面的命令来获取数据驱动服务,例如 movie 服务。
$ open $(echo \"$(echo $DOCKER_HOST)/movie\"| \sed 's/tcp:\/\//http:\/\//g'| \sed 's/[0-9]\{4,\}/10000/g'| \sed 's/\"//g')
这个命令将会访问根据导航网关终端提供的代理方式访问movie服务的REST API终端。这些REST API使用 HATEOAS 来配置,它是一个通过内嵌链接的方式支持自动发现服务的接口。
{ "_links" : { "self" : { "href" : "http://192.168.59.103:10000/movie" }, "resume" : { "href" : "http://192.168.59.103:10000/movie/resume" }, "pause" : { "href" : "http://192.168.59.103:10000/movie/pause" }, "restart" : { "href" : "http://192.168.59.103:10000/movie/restart" }, "metrics" : { "href" : "http://192.168.59.103:10000/movie/metrics" }, "env" : [ { "href" : "http://192.168.59.103:10000/movie/env" }, { "href" : "http://192.168.59.103:10000/movie/env" } ], "archaius" : { "href" : "http://192.168.59.103:10000/movie/archaius" }, "beans" : { "href" : "http://192.168.59.103:10000/movie/beans" }, "configprops" : { "href" : "http://192.168.59.103:10000/movie/configprops" }, "trace" : { "href" : "http://192.168.59.103:10000/movie/trace" }, "info" : { "href" : "http://192.168.59.103:10000/movie/info" }, "health" : { "href" : "http://192.168.59.103:10000/movie/health" }, "hystrix.stream" : { "href" : "http://192.168.59.103:10000/movie/hystrix.stream" }, "routes" : { "href" : "http://192.168.59.103:10000/movie/routes" }, "dump" : { "href" : "http://192.168.59.103:10000/movie/dump" }, "refresh" : { "href" : "http://192.168.59.103:10000/movie/refresh" }, "mappings" : { "href" : "http://192.168.59.103:10000/movie/mappings" }, "autoconfig" : { "href" : "http://192.168.59.103:10000/movie/autoconfig" } } }
总结
这是使用Spring Cloud和Docker构建微服务架构的系列博文的第一部分。在本文中,我们接触到了如下的概念:
Service Discovery
Externalized Configuration
API Gateway
Service Orchestration with Docker Compose
在这之后的博文中,我们将会演示如何使用后台服务来构建前端应用程序,同时也会介绍一个混合性持久化的实例,使用MySQL和Neo4j。
如何利用Spring Cloud构建起自我修复型分布式系统
利用Netflix所打造的组件及各类大家熟知的工具,我们完全可以顺利应对由微服务以及分布式计算所带来的技术挑战。
在过去一年当中,微服务已经成为软件架构领域一个炙手可热的新名词,而且我们也能轻松举出由其带来的诸多比较优势。然而,我们必须清醒意识到的是,一旦开始遵循微服务思路而对现有架构体系进行拆分,就意味着我们将不可避免地进入分布式系统领域。在之前的文章中我们曾经探讨过分布式计算的八大认识误区*,由此可见此类系统本身充满着风险,而且一旦犯下这八种错误中的任何一种、我们都将面对灾难性的后果。
在我个人看来,如果要将这些误区总结成一句观点,那就是:对于一套分布式系统来说,任何关于一致性或者可靠性的表达都毫无保障可言。我们需要假定系统当中的各种行为以及组件位置始终处于不断变化状态。由此产生的后果主要有两点:组件有时候会导致糟糕的服务质量甚至令服务直接离线,我们则只能将其统称为“故障”、而很难具体阐明到底是哪里出了问题。一旦没能得到妥善处理,此类故障将引中断与停机,这意味着系统将无法按照既定设计方案为用户提供服务项目。
有鉴于此,为了享受微服务所带来的诸多优势(包括松散耦合、自治服务、分散化治理以及易于持续交付等等),我们必须避免由单一故障依次递进而最终导致系统崩溃的恐怖状况。关于这一点,Erlang语言之父Joe Armstrong曾经在题为《如何构建永远运行、自我修复且可扩展的系统》一文中作出过透彻的表述。在他看来,此类系统看起来与我们所说的微服务架构非常相近,但其着重强调的是其作为自我修复系统的容错能力。那么对我们来说,如何才能建立起这样一套坚实可靠的系统方案?
Netflix公司在微服务架构的实施与推动方面一直扮演着先行者的角色。作为其业务构建的原则性方针之一,Netflix公司认为系统方案必须要能够承受任意组件的突发性故障,而整体系统仍能继续正常运转(这意味着我们仍然能够在该平台上观看电影,而Netflix也可以继续记录用户的观看喜好)。在尝试建立这样一套系统时,我们遭遇到以下这些常见的技术挑战:
由于需要将系统拆分成多个分布式进程,我们要如何在保证一致性与可靠性的前提下将这些配置分发至这些进程当中?
当这些配置方案需要加以修改时,我们该如何在无需重新部署全部进程的前提下对配置内容进行更新?
在这样一套系统当中,特别是对于部署于云环境内的系统,各个进程不仅内容经常变动、所在位置亦会不断转换(特别是在进行故障转移的情况下)。我们要如何准确判断那些需要进行协同的进程的具体位置?
一旦我们检测到了当前进程关联性的几种可能位置,我们该如何选择接下来要进行通信的进程实例?
假设在选定一个进程实例并与该实例进行通信的过程当中该实例出现了故障,我们该如何防止由此引发的连锁故障?
在系统综合运作行为不断给自治服务带来演进拓扑结构的情况下,我们要如何对其状态保持可视化监控、从而作出有针对性的准确调整?
事实上,大家可以部署多种样板模式及开源工具来解决上述技术挑战。Netflix公司就构建出多种组件且加以开源,并在生产环境中进行了一系列测试。从理论角度讲,我们能够利用这些工具来建立起有能力“永远运行、自我修复且实现规模化扩展”的系统。对刚刚着手建立分布式系统的朋友们来说,我们目前的第一要务在于理解这些实现模式、掌握Netflix组件并加以应用,而后将这些组件部署、管理并集成至自己的系统当中。由于采取任何新的技术依赖关系都会给软件工程方案带来前所未见的复杂性元素,因此我们建议大家最好直接采用Netflix的堆栈来尽可能减少此类潜在摩擦。
Spring工程技术团队从建立之初至今一直在努力打造出足以应对Java复杂性的强大武器。我们的早期关注重点在于消除J2EE给企业级应用程序开发者带来的生产效率影响。而着眼于最近一段时间,我们的主要精力则转移到了实现云-本地应用程序构建身上,而且这方面的大部分工作成果都被纳入或者围绕着Spring Cloud项目所展开。
Spring Cloud项目的既定目标在于为Spring开发人员提供一整套易于使用的工具集,从而保证其轻松构建起自己需要的分布式系统方案。为了实现这一目标,Spring Cloud以Netflix OSS堆栈为基础将大量实现堆栈加以整合并打包。这些堆栈而后可以通过大家所熟知的各类基于注释的配置工具、Java配置工具以及基于模板的编程工具实现交付。下面就让我们一起了解Spring Cloud当中的几类常见组件。
Spring Cloud Config Server
Spring Cloud Config Server能够提供一项具备横向扩展能力的集中式配置服务。它所使用的数据被保存在一套可插拔库层当中,后者目前能够支持本地存储、Git以及Subversion。通过利用一套版本控制系统作为配置存储方案,开发人员能够轻松实现版本与审计配置的内容调整。
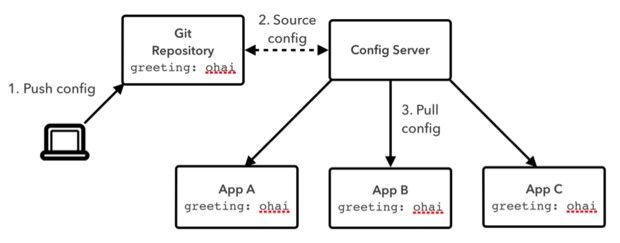
图一:Spring Cloud Config Server
配置内容会以Java属性或者YAML文件的形式体现。该Config Server会将这些文件合并为环境对象,其中包含易于理解的Spring属性模型以及作为REST API存在的配置文件。任何应用程序都能够直接调用该REST API当中所包含的配置数据,但我们也可以将智能客户端绑定方案添加到Spring Boot应用程序当中,并由后者自动将接收自Config Server的配置信息分配至任意本地配置当中。
Spring Cloud Bus
Spring Cloud Config Server是一套强大的配置分发机制,能够在保障一致性的前提下将配置内容分发到多个应用程序实例当中。然而根据其设计思路的限定,我们目前只能在应用程序启动时对其配置进行更新。在向Git中的某一属性发送新值时,我们需要以手动方式重启每个应用程序进程,从而保证该值被切实纳入应用当中。很明显,大家需要能够在无需重启的前提下完成对应用程序配置内容的更新工作。
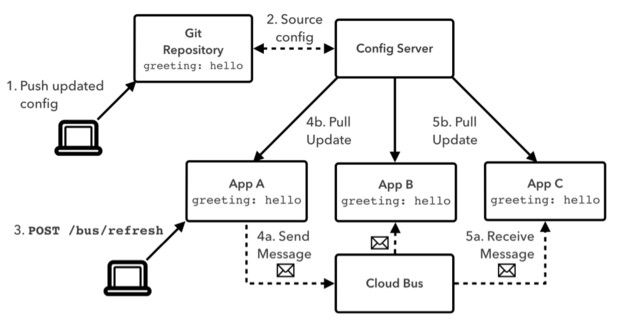
图二: 配备Spring Cloud Bus的Spring Cloud Config Server
Spring Cloud Bus的任务正是为应用程序实例添加一套管理背板。它目前依靠将一套客户端绑定至一组AMQP交换与队列当中来实现,但这一后端在设计上也实现了可插拔特性。Spring Cloud Bus为我们的应用程序带来了更多管理端点。在图二中,我们可以看到一个面向greeting属性的值被发送至Git当中,而后一条请求被发送至应用A中的/bus/refresh端点。该请求会触发以下三个事件:
应用A从Config Server处请求获取最新版本的配置内容。任意注明了@RefreshScope的Spring Bean都会被重新初始化并载入新的配置内容。
应用A向AMQP交换机制发送一条消息,表明其已经收到更新指示。
通过监听AMQP队列而被纳入Cloud Bus的应用B与应用C会获取到上述消息,并以与应用A同样的方式实现配置更新。
现在我们已经有能力在无需重启的情况下对应用程序配置进行更新了。
Spring Cloud Netflix
Spring Cloud Netflix针对多种Netflix组件提供打包方案,其中包括Eureka、Ribbon、Hystrix以及Zuul。接下来我将分别对它们作出讲解。
Eureka是一套弹性服务注册实现方案。其中服务注册属于服务发现模式的一种实现机制(如图三所示)。
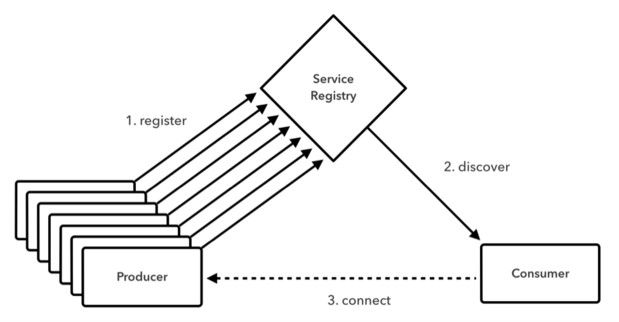
图三:利用服务注册实现服务发现
Spring Cloud Netflix通过直接将spring-cloud-starter-eureka-server关联性添加到Spring Boot应用程序、随后将该应用程序的配置类与@EnableEurekaServer相整合的方式病嵌入式Eureka服务器的部署工作。
应用程序能够通过添加spring-cloud-starter-eureka关联性并将其配置类与@EnableDiscoveryClient相整合的方式加入到服务发现流程当中。通过整合,我们能够将经过配置的适合DiscoveryClient实例注入至任意Spring Bean内。在我们所列举的实例中,DiscoveryClient作为服务发现的一种抽象机制恰好可以通过Eureka实现,不过大家也可以将其与Consul等其它备选堆栈相集成。DiscoveryClient能够通过服务的逻辑标识符提供位置信息(例如网络地址)以及其它与已注册至Eureka的服务实例相关的元数据。
Eureka提供的负载均衡机制仅支持单循环条件。而Ribbon提供的客户端IPC库则更为精巧,其同时具备可配置负载均衡机制与故障容错能力。Ribbon能够通过获取自Eureka服务器的动态服务器列表进行内容填充。Spring Cloud Netflix通过将spring-cloud-starter-ribbon关联性添加至Spring Boot应用程序的方式实现与Ribbon的集成。这套额外库允许用户将经过适当配置的LoadBalancerClient实例注入至Spring Bean当中,从而实现客户端负载均衡(如图四所示)。
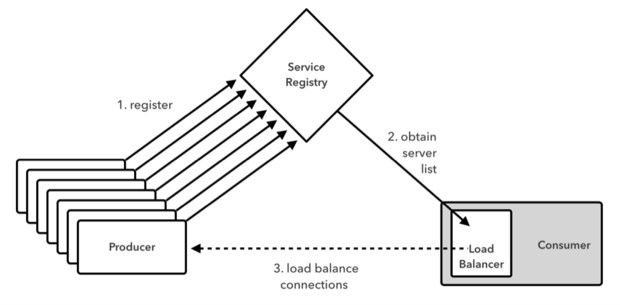
图四:使用客户端负载均衡机制
在此类任务当中,我们可以利用Ribbon实现额外负载均衡算法,包括可用性过滤、加权响应时间以及可用域亲和等。
Spring Cloud Netflix还通过自动创建能够被注入至任意Spring Bean的Ribbon强化型RestTemplate实例的方式进一步改进了Spring开发者的Ribbon使用方式。在此之后,开发人员能够轻松将URL所提供的逻辑服务名称递交至RestTemplate:
@Autowired @LoadBalanced private RestTemplate restTemplate; @RequestMapping("/") public String consume() { ProducerResponse response = restTemplate.getForObject("http://producer", ProducerResponse.class); return String.format("{\"value\": %s}", response.getValue()); }
Hystrix能够为断路器以及密闭闸门等分布式系统提供一套通用型故障容错实现模式。断路器通常会被作为一台状态机使用,具体如图五所示。
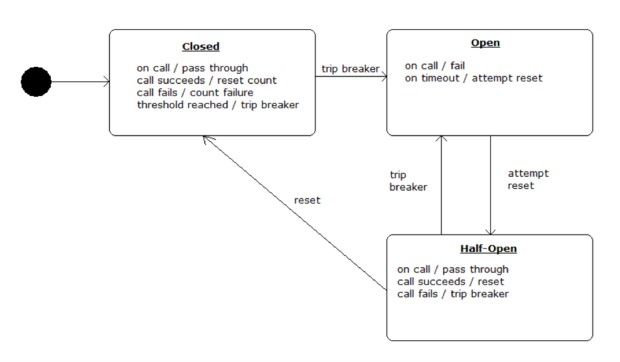
图五:断路器状态机
断路器能够介于服务及其远程关联性之间。如果该电路处于闭合状态,则所有指向该关联性的调用通常将直接通过。如果某一调用失败,则故障将被计入计数。而一旦失败次数达到可配置时间区间内的阈值,该电路将被跳闸至断开。在处于断开状态时,调用将不再被发往该关联,而由此产生的结果将可自行定制(包括报告异常、返回虚假数据或者调用其它关联等等)。
该状态机会定期进入所谓“半开”状态,旨在检测关联性是否处于健康运作状态。在这种状态下,请求一般仍将继续得以通过。当请求成功通过时,该设备会重新回归闭合状态。而如果请求失败,则该设备会重新回归断开状态。
Spring Cloud应用程序能够通过添加spring-cloud-starter-hystrix关联性并将其配置类与@EnableCircuitBreaker相整合的方式利用Hystrix。在此之后,大家可以通过与@HystrixCommand整合的方式将断路器机制纳入到任意Spring Bean方法内:
@HystrixCommand(fallbackMethod = "getProducerFallback") public ProducerResponse getValue() { return restTemplate.getForObject("http://producer", ProducerResponse.class); } 以上实例中指定了一个名为getProducerFallback的备用方法。当该断路器处于断开状态时,此方法将替代getValue接受调用: private ProducerResponse getProducerFallback() { return new ProducerResponse(42); }
除了实现状态机机制之外,Hystrix还能够提供来自各断路机制的重要遥测指标流,具体包括请求计量、响应时间直方图以及成功、失败与短路请求数量等(如图六所示)。
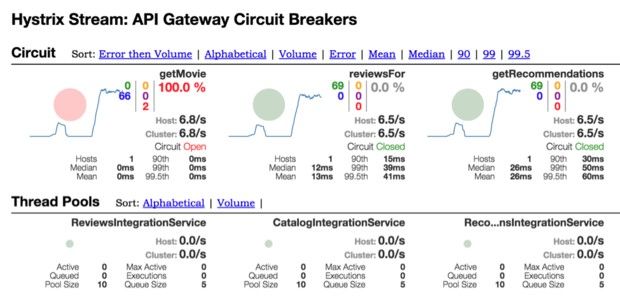
图六:Hystrix仪表板
Zuul能够处理全部指向Netflix边缘服务的输入请求。它能够与Ribbon以及Hystrix等其它Netflix组件相结合,从而提供一个灵活且具有弹性的Netflix服务路由层。
Netflix公司在Zuul当中加载动态过滤机制,从而实现以下各项功能:
验证与安全保障: 识别面向各类资源的验证要求并拒绝那些与要求不符的请求。
审查与监控: 在边缘位置追踪有意义数据及统计结果,从而为我们带来准确的生产状态结论。
动态路由: 以动态方式根据需要将请求路由至不同后端集群处。
压力测试: 逐渐增加指向集群的负载流量,从而计算性能水平。
负载分配: 为每一种负载类型分配对应容量,并弃用超出限定值的请求。
静态响应处理: 在边缘位置直接建立部分响应,从而避免其流入内部集群。
多区域弹性: 跨越AWS区域进行请求路由,旨在实现ELB使用多样化并保证边缘位置与使用者尽可能接近。
除此之外,Netflix公司还利用Zuul的功能通过金丝雀版本实现精确路由与压力测试。
Spring Cloud已经建立起一套嵌入式Zuul代理机制,从而简化常见用例当中UI应用需要将调用代理至一项或者多项后端服务处的对应开发流程。这项功能对于要求将用户界面代理至后端服务的用例而言极为便捷,其避免了管理CORS(即跨域资源共享)以及为全部后端进行独立验证等复杂流程。Zuul代理机制的一类重要应用在于实现API网关模式(如图七所示)。
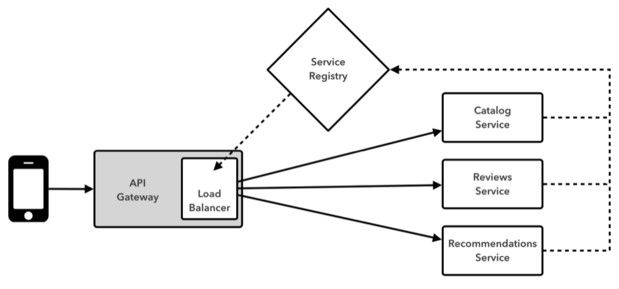
图七:API网关模式
Spring Cloud对嵌入式Zuul代理进行了强化,从而使其能够自动实现文件上传处理。而与Spring Cloud Security配合之后,其能够轻松实现OAuth2 SSO以及将令牌传递至下游服务等工作。Zuul利用Ribbon作为其客户端与全部出站请求的负载均衡机制。Ribbon的动态服务器列表内容通常由Eureka负责填充,但Spring Cloud也能够通过其它来源填充该列表。Spring Cloud Lattice项目就已经能够通过轮询Cloud Foundry Diego的Receptor API填充Ribbon的服务器列表。
跨入微服务领域的决定意味着我们将正式迎接分布式系统所带来的诸多挑战,而分布式系统绝不是那种能够“凑合使用”的方案。因此,我们必须假设系统内各组件的行为及位置始终处于不断变化当中,甚至经常表现出不可预知状态。在今天的文章中,我们已经谈到了几种能够帮助大家解决此类挑战的现成模式,而且这些模式已经在Netflix OSS与Spring Cloud得到切实验证。我个人建议大家在着手建立理想中的“永远运行、自我修复且具备可扩展能力”的系统方案之前,首先对它们进行一番尝试与体验。
*备注:这八大误区分别为:
1.网络环境是可靠的
2.延迟水平为零
3.传输带宽是无限的
4.网络环境是安全的
5.拓扑结构不会变化
6.总会有管理员帮助解决问题
7.流量成本为零
8.网络内各组成部分拥有同质性