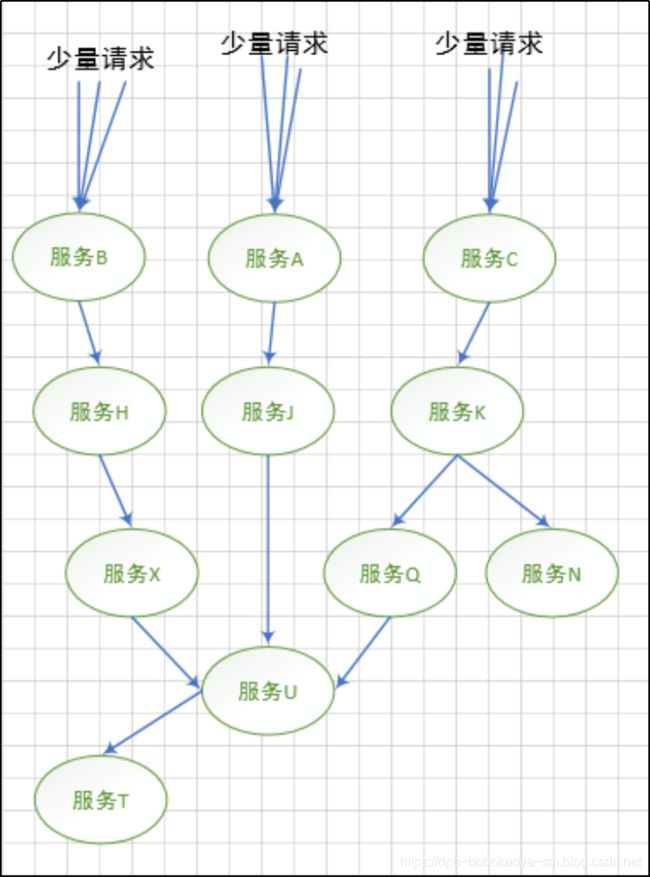
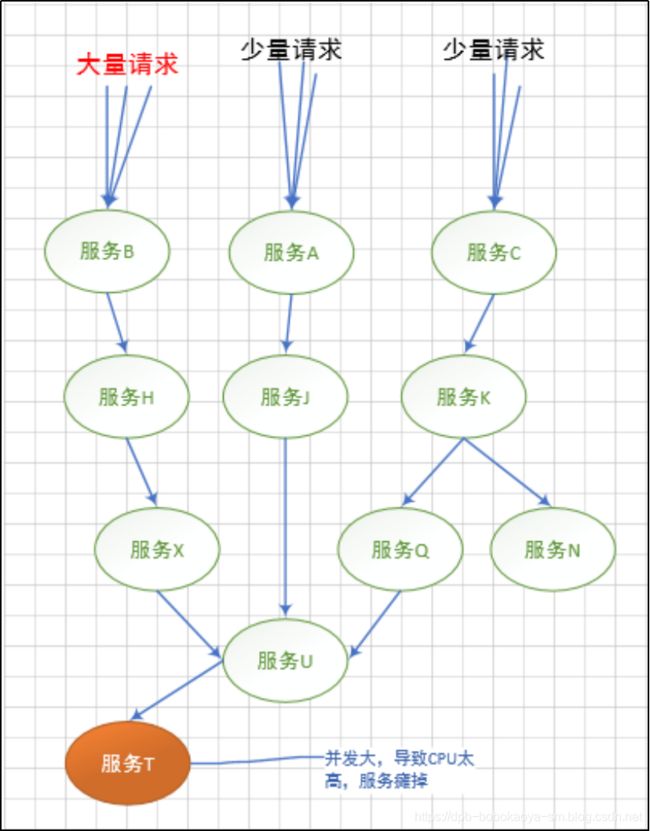
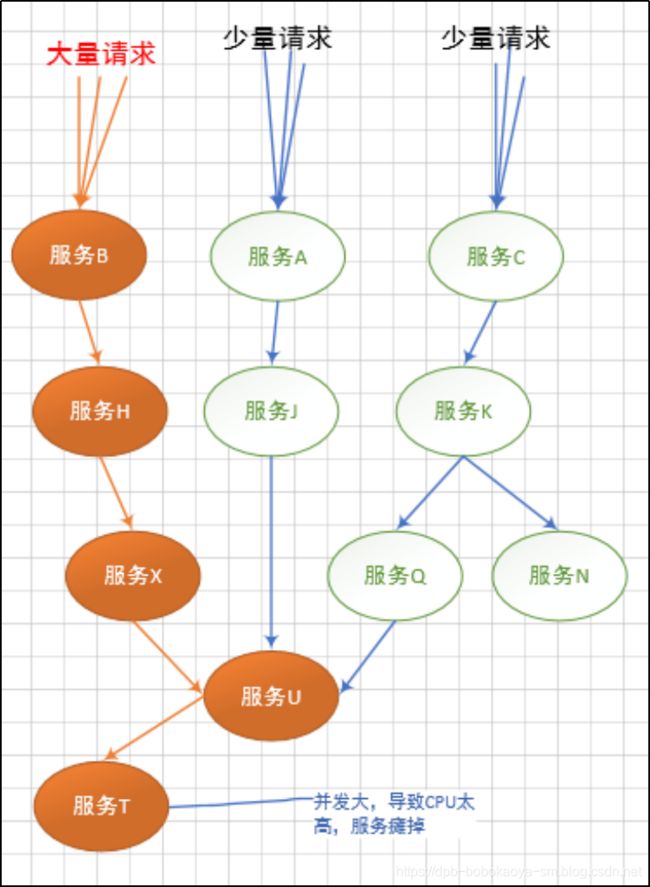
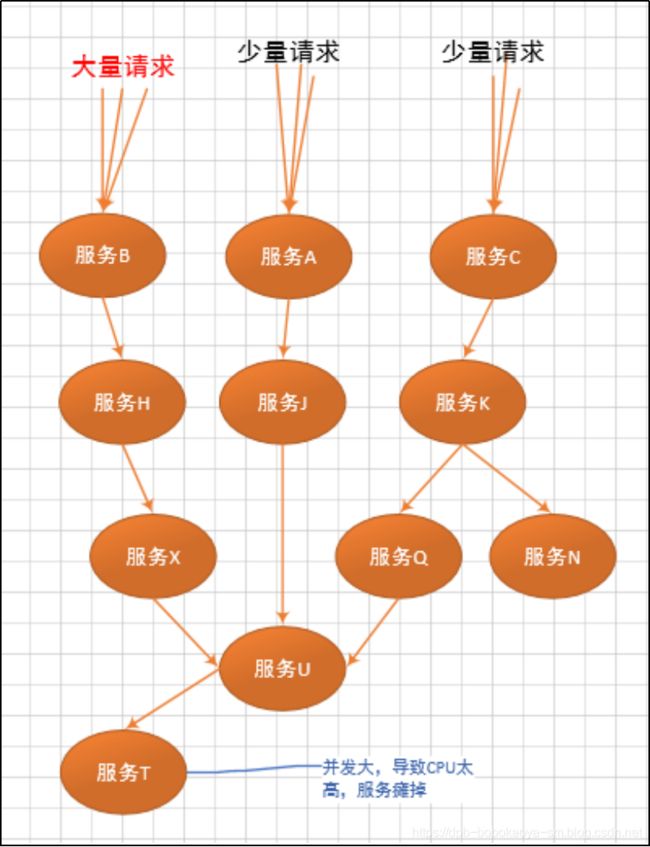
- 【树莓派入门系列】opencv安装
^Mark_Zhang^
pythonopencv人工智能
树莓派入门之Opencv库安装提示:本文树莓派4B所搭载的系统是Raspi11本教程不需要任何换源,直接用树莓派自带的源就行文章目录一、树莓派版本查看二、Opencv库安装1.扩大系统文件(常规操作)2.安装aptitude软件包3.CMake工具安装4.基础库安装5.opencv-python库5.注意点一、树莓派版本查看代码如下:uanme-a或lsb_release-a二、Opencv库安装
- Spring注解09——BeanPostProcessor后置处理器深度剖析
大黄奔跑
Spring注解驱动
该系列文章主要学习雷丰阳老师的《Spring注解驱动》课程总结。原课程地址:课程地址包括了自己阅读其他书籍《Spring揭秘》《SpringBoot实战》等课程。该系列文档会不断的完善,欢迎大家留言及提意见。文章目录1.写在之前2.BeanPostProcessor是什么3.xxxBeanPostProcessor源码分析4.Spring框架用该接口干嘛呢?总结1.写在之前本篇会有一些源码的分析,
- 【Nginx系列】Nginx配置超时时间
m0_74824552
面试学习路线阿里巴巴nginx运维
???欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。推荐:kwan的首页,持续学习,不断总结,共同进步,活到老学到老导航檀越剑指大厂系列:全面总结java核心技术,jvm,并发编程redis,kafka,Spring,微服务等常用开发工具系列:常用的开发工具,IDEA,Mac,Alfred,G
- C/C++教程 第十四章 —— MFC控件详解
余识-
C/C++实战入门到精通mfcc++c语言
注意本系列文章已升级、转移至我的自建站点中,本章原文为:MFC控件详解目录注意一、前言二、项目建立三、Comboxbox四、ListBox五、GroupBox六、Picturecontrol七、ScrollBar八、SpinControl九、ProgressControl十、hotkey十一、ListControl十二、TreeControl十三、TabControl一、前言通过前面两章的学习,现
- 基于Python的自然语言处理系列(2):Word2Vec(负采样)
会飞的Anthony
自然语言处理人工智能信息系统自然语言处理word2vec人工智能
在本系列的第二篇文章中,我们将继续探讨Word2Vec模型,这次重点介绍负采样(NegativeSampling)技术。负采样是一种优化Skip-gram模型训练效率的技术,它能在大规模语料库中显著减少计算复杂度。接下来,我们将通过详细的代码实现和理论讲解,帮助你理解负采样的工作原理及其在Word2Vec中的应用。1.Word2Vec(负采样)原理1.1负采样的背景在Word2Vec的Skip-g
- 大模型GUI系列论文阅读 DAY4:《PREDICT: Multi-Agent-based Debate Simulation for Generalized Hate Speech Detecti》
feifeikon
论文阅读
摘要虽然已经提出了一些公共基准用于训练仇恨言论检测模型,但这些基准之间的标注标准差异为模型的泛化学习带来了挑战,限制了其适用性。先前的研究提出了通过数据整合或扩充来泛化模型的方法,但在克服数据集之间的标注标准差异方面仍然存在局限性。为了解决这些挑战,我们提出了PREDICT,一种基于多代理(multi-agent)概念的仇恨言论检测新框架。PREDICT包括两个阶段:(1)PRE(基于视角的推理)
- 图神经网络系列论文阅读DAY1:《Predicting Tweet Engagement with Graph Neural Networks》
feifeikon
神经网络论文阅读人工智能
摘要翻译:社交网络是全球范围内分享内容的重要在线渠道之一。在这种背景下,预测一篇帖子在互动方面是否会产生影响,对于推动这些媒体的盈利利用至关重要。在现有研究中,许多方法通过利用帖子的直接特征来解决这一问题,这些特征通常与文本内容以及发布该帖子的用户相关。在本文中,我们认为互动的增加还与另一个关键因素相关,即社交媒体用户发布的帖子之间的语义关联。因此,我们提出了一种基于图神经网络(GraphNeur
- 关于Jedis和lettuce以及springDataRedis的一些区别
追光的人(陈聪)
第三阶段redis相关redisjedisjava
1:三者其实都是用来操作redis的2:springDataRedis是对Jedis和lettuce的一系列封装,简化了很多方法3:公司里面之所以不怎么用Jedis也是因为其指令比较繁琐难以记忆,不如就用简化了的springDataRedis4:使用springDataRedis时,首先要导入springDataRedis的依赖,然后导入Jedis或者lettuce,如果是Jedis,需要再导入s
- Python3【字符串】:文本操作的瑞士军刀
李智 - 重庆
Python精讲精练-从入门到实战python开发语言经验分享编程实战趣味编程编程技巧
Python3【字符串】:文本操作的瑞士军刀内容简介本系列文章是为Python3学习者精心设计的一套全面、实用的学习指南,旨在帮助读者从基础入门到项目实战,全面提升编程能力。文章结构由5个版块组成,内容层层递进,逻辑清晰。基础速通:n个浓缩提炼的核心知识点,夯实编程基础;经典范例:10个贴近实际的应用场景,深入理解Python3的编程技巧和应用方法;避坑宝典:10个典型错误解析,提供解决方案,帮助
- 学习ESP32系列一个超级有用的网站
LS_learner
嵌入式嵌入式硬件
学习ESP32ESP32简介ESP32ArduinoIDEESP32ArduinoIDE2.0VSCode和PlatformIOESP32引脚分布ESP32输入输出ESP32PWMESP32模拟输入ESP32中断定时器ESP32深度睡眠协议ESP32Web服务器ESP32LoRaESP32BLEESP32BLE客户端-服务器ESP32蓝牙ESP32MQTTESP32ESP-NOWESP32Wi-F
- Python3 字典:解锁高效数据存储的钥匙
李智 - 重庆
Python精讲精练-从入门到实战python经验分享编程实战趣味编程编程技巧
Python3字典:解锁高效数据存储的钥匙内容简介本系列文章是为Python3学习者精心设计的一套全面、实用的学习指南,旨在帮助读者从基础入门到项目实战,全面提升编程能力。文章结构由5个版块组成,内容层层递进,逻辑清晰。基础速通:n个浓缩提炼的核心知识点,夯实编程基础;经典范例:10个贴近实际的应用场景,深入理解Python3的编程技巧和应用方法;避坑宝典:10个典型错误解析,提供解决方案,帮助读
- Spring Clound + Spring Clound Alibaba 全家桶
更容易记住我
SpringCloundjavaspringcloudalibaba
官方网站:https://spring.io/projects/spring-cloud/一、服务注册中心Eureka服务注册中心EurekaZookeeperZookeeperConsul服务注册中心ConsulNacos(推荐)服务注册中心Nacos二、服务调用1Ribbon+LoadBalancer服务调用Ribbon三、服务调用2OpenFegin服务调用OpenFeign四、服务降级Hy
- 【业界新闻】浪潮高端存储系统技术发展及展望(上篇)
nicole-cao
业界新闻浪潮高端存储raid
转自:http://news.watchstor.com/corp-147547.htm[导读]从“9.11事件”之后大量的企业因为数据丢失而宣告破产可以看出数据的重要地位。随着计算机技术的发展,实现了数据计算和数据存储的分离,而数据存储由存储系统完成。存储系统的出现,尤其是高端存储系统的出现使得数据存储变得专业化,存储系统可以为用户提供更高性能、可用性和可靠性的数据存储功能。本系列文章,从高端存
- Agent实战系列:快速自定义Agent在业务线落地:从入门到高级[实现tool串联、多轮对话、多Agent动态编排、静态编排等]
汀、人工智能
AIAgentLLM工业级落地实践人工智能AIAgent多智能体协作知识问答智能问答RAGAI编排流
Agent实战系列:快速自定义Agent在业务线落地:从入门到高级[实现tool串联、多轮对话、多Agent动态编排、静态编排等]本系列涵盖了多个关键功能的实现,包括tool串联、多轮对话、多Agent动态编排以及静态编排等。通过这些功能的学习与实践,用户将能够构建出功能丰富、灵活多变的Agent系统。tool串联让Agent能够调用多种工具和服务,多轮对话则让Agent能够与用户进行更加自然和深
- 第9章 空闲任务与阻塞延时的实现--总结
LS·Cui
freeRtosc语言物联网
整理野火《FreeRTOS内核实现与应用开发实战指南》—基于野火STM32全系列(M3/4/7)开发板文章目录第9章空闲任务与阻塞延时的实现9.1实现空闲任务9.1.1定义空闲任务的栈9.1.2定义空闲任务的任务控制块9.1.3创建空闲任务9.2实现阻塞延时9.2.1vTaskDelay()函数9.2.2修改vTaskSwitchContext()函数9.3SysTick中断服务函数9.3.1xT
- LogicFlow 一款流程图编辑框架
小毛驴850
流程图
LogicFlow是什么LogicFlow是一款流程图编辑框架,提供了一系列流程图交互、编辑所必需的功能和灵活的节点自定义、插件等拓展机制。LogicFlow支持前端自定义开发各种逻辑编排场景,如流程图、ER图、BPMN流程等。在工作审批流配置、机器人逻辑编排、无代码平台流程配置都有较好的应用。官方网站更多资料请查看LogicFlow系列文章特性可视化模型:通过LogicFlow提供的直观可视化界
- [预训练语言模型专题] 百度出品ERNIE合集,问国产预训练语言模型哪家强
yang191919
朴素人工智能百度编程语言机器学习人工智能深度学习
本文为预训练语言模型专题系列第七篇系列传送门[萌芽时代]、[风起云涌]、[文本分类通用技巧]、[GPT家族]、[BERT来临]、[BE
- web开发工具之:二、加密和解密工具类,学习加密算法和非加密算法(哈希算法)知识,Java支持MD5和SHA系列的哈希算法。使用UUID作为盐进行增强哈希算法加密的数据完整性验证
java冯坚持
web开发前端学习哈希算法
文章目录前言一、加密算法/非加密算法-了解和学习为主1、加密算法和秘钥a、介绍b、常用加密算法-对称加密算法c、常用加密算法-对称加密算法2、非加密算法:哈希算法(MD5、SHA系列)a、哈希算法介绍b、MD5和SHA系列介绍二、哈希算法应用场景概念介绍1.数据完整性验证2.密码存储(借助数据完整性验证来进行密码存储)3.数字签名4.总结三、注册和登录-采用哈希算法进行密码存储和验证流程1.加密过
- (三)python网络爬虫(理论+实战)——爬虫与反爬虫
阳光宅男xxb
30天学会python网络爬虫python大数据爬虫
系列文章目录(1)python网络爬虫—快速入门(理论+实战)(一)(2)python网络爬虫—快速入门(理论+实战)(二)序言本人从事爬虫相关工作已8年以上,从一个小白到能够熟练使用爬虫,中间也走了些弯路,希望以自身的学习经历,让大家能够轻而易举的,快速的,掌握爬虫的相关知识并熟练的使用它,避免浪费更多的无用时间,甚至走
- 【C++基础】多线程并发场景下的同步方法
kucupung
C++c++开发语言
如果在多线程程序中对全局变量的访问没有进行适当的同步控制(例如使用互斥锁、原子变量等),会导致多个线程同时访问和修改全局变量时发生竞态条件(racecondition)。这种竞态条件可能会导致一系列不确定和严重的后果。在C++中,可以通过使用互斥锁(mutex)、原子操作、读写锁来实现对全局变量的互斥访问。一、缺乏同步控制造成的后果1.数据竞争(DataRace)数据竞争发生在多个线程同时访问同一
- Hive面试题汇总
大数据侠客
hive相关问题汇总及解决hivehadoop数据仓库面试
Hive定义Hive是建立在Hadoop上的数据仓库基础构架。可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种
- 电商商业平台技术架构系列教程之:电商平台系统架构设计
AI天才研究院
AI大模型企业级应用开发实战大数据人工智能语言模型JavaPython架构设计
作者:禅与计算机程序设计艺术1.背景介绍1.1电商背景简介电商俗称网上购物,是一种通过网络直接进行商品交易的一种服务方式。在电商平台的运作中,消费者可以选择浏览、搜索和购买自己需要的产品或服务。通过平台发布的产品及其信息,用户可以方便地找到相关的产品和服务,从而提高效率和效益。而电商平台则是提供交易平台、管理后台、销售数据分析等功能。1.2电商系统架构概述电商平台通常由后端服务(API服务)、数据
- openlayers添加按钮_OpenLayers系列(4)——使用控制器 | 学步园
weixin_39689394
openlayers添加按钮
控制器可以使用在地图上,也可以使用在地图之外的元素如中。添加控制器有两种方式:1.在map对象初始化时以js数组的形式把OpenLayers控制器传入2.在map对象初始化后,调用addControl()来添加单个控制器或者addControls()传入一个控制器数组对象当一个map对象被初始化后,默认会有4种控制器:1.OpenLayers.Control.Navigation:用来控制地图与鼠
- 国内外大模型免费访问入口汇总
SmallerFL
NLP&机器学习大模型nlp自然语言处理深度学习gpt
1.前言2024年4月18日,清华大学基础模型研究中心发布了《SuperBench大模型综合能力评测报告》,评测涉及到的国内外大模型如下:文中从多个方面进行评测,具体包含:语义评测、代码评测、对齐评测、智能体评测、安全评测等五大方面,见下图:结论:GPT-4系列模型和Claude-3**等国外模型在多个能力上依然处于领先地位**,国内头部大模型表现亮眼,与国际一流模型水平接近,且差距已经逐渐缩小。
- 基于深度学习的鸟类识别系统详解(UI界面 + YOLOv10 + 数据集)
2025年数学建模美赛
深度学习uiYOLO人工智能python计算机视觉
引言鸟类识别是计算机视觉领域中一个独具挑战性的任务,尤其是在复杂的自然环境中,识别不同种类的鸟类需要非常强大的模型和丰富的数据集。随着深度学习技术的发展,基于YOLO(YouOnlyLookOnce)系列模型的目标检测系统展现了卓越的性能,特别是在速度和精度上的平衡方面。本博客将详细讲解如何利用YOLOv10模型来构建一个基于深度学习的鸟类识别系统。该系统会结合自定义鸟类数据集,设计一个简洁直观的
- 自动驾驶系统研发系列—追尾风险不再隐形:解密后碰撞预警系统(RCW)的技术与应用
学步_技术
自动驾驶系统研发自动驾驶人工智能机器学习RCW
欢迎来到我的技术小筑,一个专为技术探索者打造的交流空间。在这里,我们不仅分享代码的智慧,还探讨技术的深度与广度。无论您是资深开发者还是技术新手,这里都有一片属于您的天空。让我们在知识的海洋中一起航行,共同成长,探索技术的无限可能。探索专栏:学步_技术的首页——持续学习,不断进步,让学习成为我们共同的习惯,让总结成为我们前进的动力。技术导航:人工智能:深入探讨人工智能领域核心技术。自动驾驶:分享自动
- Kafka的Partition故障恢复机制与HW一致性保障-Epoch更新机制详解
大树~~
#Kafkajavakafka分布式后端
在分布式系统中,节点的故障是不可避免的。为了确保系统的高可用性和数据的一致性,Kafka设计了一系列机制来应对Broker或Partition的故障。本文将详细解析Kafka的Partition故障恢复机制和HW一致性保障-Epoch更新机制,帮助深入理解Kafka在面对故障时的处理逻辑和一致性保障手段。一、Partition故障恢复机制1.概述Kafka中的每个Topic被划分为多个Partit
- 【Java】已解决:java.util.concurrent.ExecutionException
HoRain云小助手
java开发语言
HoRain云小助手:个人主页个人专栏:《Linux系列教程》《c语言教程》⛺️生活的理想,就是为了理想的生活!⛳️推荐前些天发现了一个超棒的服务器购买网站,性价比超高,大内存超划算!忍不住分享一下给大家。点击跳转到网站。专栏介绍专栏名称专栏介绍《C语言》本专栏主要撰写C干货内容和编程技巧,让大家从底层了解C,把更多的知识由抽象到简单通俗易懂。《网络协议》本专栏主要是注重从底层来给大家一步步剖析网
- 【Java】已解决:jorg.springframework.beans.factory.BeanDefinitionStoreException
HoRain云小助手
java开发语言
HoRain云小助手:个人主页个人专栏:《Linux系列教程》《c语言教程》⛺️生活的理想,就是为了理想的生活!⛳️推荐前些天发现了一个超棒的服务器购买网站,性价比超高,大内存超划算!忍不住分享一下给大家。点击跳转到网站。专栏介绍专栏名称专栏介绍《C语言》本专栏主要撰写C干货内容和编程技巧,让大家从底层了解C,把更多的知识由抽象到简单通俗易懂。《网络协议》本专栏主要是注重从底层来给大家一步步剖析网
- 自动驾驶系列—自动驾驶MCU架构全方位解析:从单核到多核的选型指南与应用实例
学步_技术
自动驾驶自动驾驶单片机架构MCU
欢迎来到我的技术小筑,一个专为技术探索者打造的交流空间。在这里,我们不仅分享代码的智慧,还探讨技术的深度与广度。无论您是资深开发者还是技术新手,这里都有一片属于您的天空。让我们在知识的海洋中一起航行,共同成长,探索技术的无限可能。探索专栏:学步_技术的首页——持续学习,不断进步,让学习成为我们共同的习惯,让总结成为我们前进的动力。技术导航:人工智能:深入探讨人工智能领域核心技术。自动驾驶:分享自动
- SAX解析xml文件
小猪猪08
xml
1.创建SAXParserFactory实例
2.通过SAXParserFactory对象获取SAXParser实例
3.创建一个类SAXParserHander继续DefaultHandler,并且实例化这个类
4.SAXParser实例的parse来获取文件
public static void main(String[] args) {
//
- 为什么mysql里的ibdata1文件不断的增长?
brotherlamp
linuxlinux运维linux资料linux视频linux运维自学
我们在 Percona 支持栏目经常收到关于 MySQL 的 ibdata1 文件的这个问题。
当监控服务器发送一个关于 MySQL 服务器存储的报警时,恐慌就开始了 —— 就是说磁盘快要满了。
一番调查后你意识到大多数地盘空间被 InnoDB 的共享表空间 ibdata1 使用。而你已经启用了 innodbfileper_table,所以问题是:
ibdata1存了什么?
当你启用了 i
- Quartz-quartz.properties配置
eksliang
quartz
其实Quartz JAR文件的org.quartz包下就包含了一个quartz.properties属性配置文件并提供了默认设置。如果需要调整默认配置,可以在类路径下建立一个新的quartz.properties,它将自动被Quartz加载并覆盖默认的设置。
下面是这些默认值的解释
#-----集群的配置
org.quartz.scheduler.instanceName =
- informatica session的使用
18289753290
workflowsessionlogInformatica
如果希望workflow存储最近20次的log,在session里的Config Object设置,log options做配置,save session log :sessions run ;savesessio log for these runs:20
session下面的source 里面有个tracing
- Scrapy抓取网页时出现CRC check failed 0x471e6e9a != 0x7c07b839L的错误
酷的飞上天空
scrapy
Scrapy版本0.14.4
出现问题现象:
ERROR: Error downloading <GET http://xxxxx CRC check failed
解决方法
1.设置网络请求时的header中的属性'Accept-Encoding': '*;q=0'
明确表示不支持任何形式的压缩格式,避免程序的解压
- java Swing小集锦
永夜-极光
java swing
1.关闭窗体弹出确认对话框
1.1 this.setDefaultCloseOperation (JFrame.DO_NOTHING_ON_CLOSE);
1.2
this.addWindowListener (
new WindowAdapter () {
public void windo
- 强制删除.svn文件夹
随便小屋
java
在windows上,从别处复制的项目中可能带有.svn文件夹,手动删除太麻烦,并且每个文件夹下都有。所以写了个程序进行删除。因为.svn文件夹在windows上是只读的,所以用File中的delete()和deleteOnExist()方法都不能将其删除,所以只能采用windows命令方式进行删除
- GET和POST有什么区别?及为什么网上的多数答案都是错的。
aijuans
get post
如果有人问你,GET和POST,有什么区别?你会如何回答? 我的经历
前几天有人问我这个问题。我说GET是用于获取数据的,POST,一般用于将数据发给服务器之用。
这个答案好像并不是他想要的。于是他继续追问有没有别的区别?我说这就是个名字而已,如果服务器支持,他完全可以把G
- 谈谈新浪微博背后的那些算法
aoyouzi
谈谈新浪微博背后的那些算法
本文对微博中常见的问题的对应算法进行了简单的介绍,在实际应用中的算法比介绍的要复杂的多。当然,本文覆盖的主题并不全,比如好友推荐、热点跟踪等就没有涉及到。但古人云“窥一斑而见全豹”,希望本文的介绍能帮助大家更好的理解微博这样的社交网络应用。
微博是一个很多人都在用的社交应用。天天刷微博的人每天都会进行着这样几个操作:原创、转发、回复、阅读、关注、@等。其中,前四个是针对短博文,最后的关注和@则针
- Connection reset 连接被重置的解决方法
百合不是茶
java字符流连接被重置
流是java的核心部分,,昨天在做android服务器连接服务器的时候出了问题,就将代码放到java中执行,结果还是一样连接被重置
被重置的代码如下;
客户端代码;
package 通信软件服务器;
import java.io.BufferedWriter;
import java.io.OutputStream;
import java.io.O
- web.xml配置详解之filter
bijian1013
javaweb.xmlfilter
一.定义
<filter>
<filter-name>encodingfilter</filter-name>
<filter-class>com.my.app.EncodingFilter</filter-class>
<init-param>
<param-name>encoding<
- Heritrix
Bill_chen
多线程xml算法制造配置管理
作为纯Java语言开发的、功能强大的网络爬虫Heritrix,其功能极其强大,且扩展性良好,深受热爱搜索技术的盆友们的喜爱,但它配置较为复杂,且源码不好理解,最近又使劲看了下,结合自己的学习和理解,跟大家分享Heritrix的点点滴滴。
Heritrix的下载(http://sourceforge.net/projects/archive-crawler/)安装、配置,就不罗嗦了,可以自己找找资
- 【Zookeeper】FAQ
bit1129
zookeeper
1.脱离IDE,运行简单的Java客户端程序
#ZkClient是简单的Zookeeper~$ java -cp "./:zookeeper-3.4.6.jar:./lib/*" ZKClient
1. Zookeeper是的Watcher回调是同步操作,需要添加异步处理的代码
2. 如果Zookeeper集群跨越多个机房,那么Leader/
- The user specified as a definer ('aaa'@'localhost') does not exist
白糖_
localhost
今天遇到一个客户BUG,当前的jdbc连接用户是root,然后部分删除操作都会报下面这个错误:The user specified as a definer ('aaa'@'localhost') does not exist
最后找原因发现删除操作做了触发器,而触发器里面有这样一句
/*!50017 DEFINER = ''aaa@'localhost' */
原来最初
- javascript中showModelDialog刷新父页面
bozch
JavaScript刷新父页面showModalDialog
在页面中使用showModalDialog打开模式子页面窗口的时候,如果想在子页面中操作父页面中的某个节点,可以通过如下的进行:
window.showModalDialog('url',self,‘status...’); // 首先中间参数使用self
在子页面使用w
- 编程之美-买书折扣
bylijinnan
编程之美
import java.util.Arrays;
public class BookDiscount {
/**编程之美 买书折扣
书上的贪心算法的分析很有意思,我看了半天看不懂,结果作者说,贪心算法在这个问题上是不适用的。。
下面用动态规划实现。
哈利波特这本书一共有五卷,每卷都是8欧元,如果读者一次购买不同的两卷可扣除5%的折扣,三卷10%,四卷20%,五卷
- 关于struts2.3.4项目跨站执行脚本以及远程执行漏洞修复概要
chenbowen00
strutsWEB安全
因为近期负责的几个银行系统软件,需要交付客户,因此客户专门请了安全公司对系统进行了安全评测,结果发现了诸如跨站执行脚本,远程执行漏洞以及弱口令等问题。
下面记录下本次解决的过程以便后续
1、首先从最简单的开始处理,服务器的弱口令问题,首先根据安全工具提供的测试描述中发现应用服务器中存在一个匿名用户,默认是不需要密码的,经过分析发现服务器使用了FTP协议,
而使用ftp协议默认会产生一个匿名用
- [电力与暖气]煤炭燃烧与电力加温
comsci
在宇宙中,用贝塔射线观测地球某个部分,看上去,好像一个个马蜂窝,又像珊瑚礁一样,原来是某个国家的采煤区.....
不过,这个采煤区的煤炭看来是要用完了.....那么依赖将起燃烧并取暖的城市,在极度严寒的季节中...该怎么办呢?
&nbs
- oracle O7_DICTIONARY_ACCESSIBILITY参数
daizj
oracle
O7_DICTIONARY_ACCESSIBILITY参数控制对数据字典的访问.设置为true,如果用户被授予了如select any table等any table权限,用户即使不是dba或sysdba用户也可以访问数据字典.在9i及以上版本默认为false,8i及以前版本默认为true.如果设置为true就可能会带来安全上的一些问题.这也就为什么O7_DICTIONARY_ACCESSIBIL
- 比较全面的MySQL优化参考
dengkane
mysql
本文整理了一些MySQL的通用优化方法,做个简单的总结分享,旨在帮助那些没有专职MySQL DBA的企业做好基本的优化工作,至于具体的SQL优化,大部分通过加适当的索引即可达到效果,更复杂的就需要具体分析了,可以参考本站的一些优化案例或者联系我,下方有我的联系方式。这是上篇。
1、硬件层相关优化
1.1、CPU相关
在服务器的BIOS设置中,可
- C语言homework2,有一个逆序打印数字的小算法
dcj3sjt126com
c
#h1#
0、完成课堂例子
1、将一个四位数逆序打印
1234 ==> 4321
实现方法一:
# include <stdio.h>
int main(void)
{
int i = 1234;
int one = i%10;
int two = i / 10 % 10;
int three = i / 100 % 10;
- apacheBench对网站进行压力测试
dcj3sjt126com
apachebench
ab 的全称是 ApacheBench , 是 Apache 附带的一个小工具 , 专门用于 HTTP Server 的 benchmark testing , 可以同时模拟多个并发请求。前段时间看到公司的开发人员也在用它作一些测试,看起来也不错,很简单,也很容易使用,所以今天花一点时间看了一下。
通过下面的一个简单的例子和注释,相信大家可以更容易理解这个工具的使用。
- 2种办法让HashMap线程安全
flyfoxs
javajdkjni
多线程之--2种办法让HashMap线程安全
多线程之--synchronized 和reentrantlock的优缺点
多线程之--2种JAVA乐观锁的比较( NonfairSync VS. FairSync)
HashMap不是线程安全的,往往在写程序时需要通过一些方法来回避.其实JDK原生的提供了2种方法让HashMap支持线程安全.
- Spring Security(04)——认证简介
234390216
Spring Security认证过程
认证简介
目录
1.1 认证过程
1.2 Web应用的认证过程
1.2.1 ExceptionTranslationFilter
1.2.2 在request之间共享SecurityContext
1
- Java 位运算
Javahuhui
java位运算
// 左移( << ) 低位补0
// 0000 0000 0000 0000 0000 0000 0000 0110 然后左移2位后,低位补0:
// 0000 0000 0000 0000 0000 0000 0001 1000
System.out.println(6 << 2);// 运行结果是24
// 右移( >> ) 高位补"
- mysql免安装版配置
ldzyz007
mysql
1、my-small.ini是为了小型数据库而设计的。不应该把这个模型用于含有一些常用项目的数据库。
2、my-medium.ini是为中等规模的数据库而设计的。如果你正在企业中使用RHEL,可能会比这个操作系统的最小RAM需求(256MB)明显多得多的物理内存。由此可见,如果有那么多RAM内存可以使用,自然可以在同一台机器上运行其它服务。
3、my-large.ini是为专用于一个SQL数据
- MFC和ado数据库使用时遇到的问题
你不认识的休道人
sqlC++mfc
===================================================================
第一个
===================================================================
try{
CString sql;
sql.Format("select * from p
- 表单重复提交Double Submits
rensanning
double
可能发生的场景:
*多次点击提交按钮
*刷新页面
*点击浏览器回退按钮
*直接访问收藏夹中的地址
*重复发送HTTP请求(Ajax)
(1)点击按钮后disable该按钮一会儿,这样能避免急躁的用户频繁点击按钮。
这种方法确实有些粗暴,友好一点的可以把按钮的文字变一下做个提示,比如Bootstrap的做法:
http://getbootstrap.co
- Java String 十大常见问题
tomcat_oracle
java正则表达式
1.字符串比较,使用“==”还是equals()? "=="判断两个引用的是不是同一个内存地址(同一个物理对象)。 equals()判断两个字符串的值是否相等。 除非你想判断两个string引用是否同一个对象,否则应该总是使用equals()方法。 如果你了解字符串的驻留(String Interning)则会更好地理解这个问题。
- SpringMVC 登陆拦截器实现登陆控制
xp9802
springMVC
思路,先登陆后,将登陆信息存储在session中,然后通过拦截器,对系统中的页面和资源进行访问拦截,同时对于登陆本身相关的页面和资源不拦截。
实现方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23