数据结构&算法-----(10)手撕LRU算法
数据结构&算法-----(10)手撕LRU算法
- LRU算法原理解析
- 几种思路
- ① LinkedHashMap实现
- ② 双向链表+哈希表实现
- 题目描述:LeetCode146,LRU缓存机制
- 算法设计
- 代码实现
- 拓展
- 1.LRU-K
- 2.two queue
- 3.Multi Queue(MQ)
- LRU算法对比
LRU算法原理解析
LRU是Least Recently Used的缩写,即最近最少使用,常用于页面置换算法,是为虚拟页式存储管理服务的。
现代操作系统提供了一种对主存的抽象概念虚拟内存,来对主存进行更好地管理。他将主存看成是一个存储在磁盘上的地址空间的高速缓存,在主存中只保存活动区域,并根据需要在主存和磁盘之间来回传送数据。虚拟内存被组织为存放在磁盘上的N个连续的字节组成的数组,每个字节都有唯一的虚拟地址,作为到数组的索引。虚拟内存被分割为大小固定的数据块虚拟页(Virtual Page,VP),这些数据块作为主存和磁盘之间的传输单元。类似地,物理内存被分割为物理页(Physical Page,PP)。
虚拟内存使用页表来记录和判断一个虚拟页是否缓存在物理内存中:
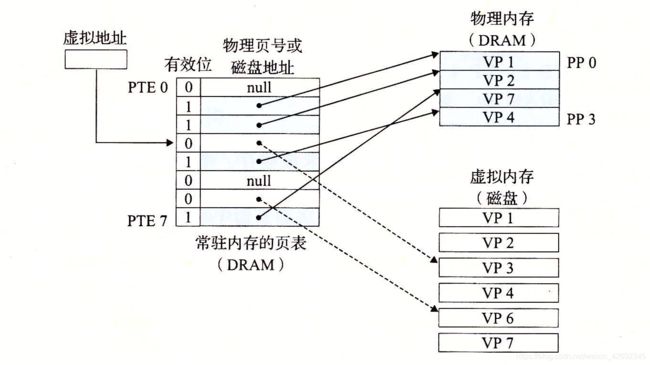
如上图所示,当CPU访问虚拟页VP3时,发现VP3并未缓存在物理内存之中,这称之为缺页,现在需要将VP3从磁盘复制到物理内存中,但在此之前,为了保持原有空间的大小,需要在物理内存中选择一个牺牲页,将其复制到磁盘中,这称之为交换或者页面调度,图中的牺牲页为VP4。把哪个页面调出去可以达到调动尽量少的目的?最好是每次调换出的页面是所有内存页面中最迟将被使用的——这可以最大限度的推迟页面调换,这种算法,被称为理想页面置换算法,但这种算法很难完美达到。
为了尽量减少与理想算法的差距,产生了各种精妙的算法,LRU算法便是其中一个。
LRU算法的设计原则是:如果一个数据在最近一段时间没有被访问到,那么在将来它被访问的可能性也很小。也就是说,当限定的空间已存满数据时,应当把最久没有被访问到的数据淘汰。
几种思路
1.用一个数组来存储数据,给每一个数据项标记一个访问时间戳,每次插入新数据项的时候,先把数组中存在的数据项的时间戳自增,并将新数据项的时间戳置为0并插入到数组中。每次访问数组中的数据项的时候,将被访问的数据项的时间戳置为0。当数组空间已满时,将时间戳最大的数据项淘汰。
2.利用一个链表来实现,每次新插入数据的时候将新数据插到链表的头部;每次缓存命中(即数据被访问),则将数据移到链表头部;那么当链表满的时候,就将链表尾部的数据丢弃。
3.利用链表和hashmap。当需要插入新的数据项的时候,如果新数据项在链表中存在(一般称为命中),则把该节点移到链表头部,如果不存在,则新建一个节点,放到链表头部,若缓存满了,则把链表最后一个节点删除即可。在访问数据的时候,如果数据项在链表中存在,则把该节点移到链表头部,否则返回-1。这样一来在链表尾部的节点就是最近最久未访问的数据项。
对于第一种方法,需要不停地维护数据项的访问时间戳,另外,在插入数据、删除数据以及访问数据时,时间复杂度都是O(n)。对于第二种方法,链表在定位数据的时候时间复杂度为O(n)。所以在一般使用第三种方式来是实现LRU算法。
① LinkedHashMap实现
LinkedHashMap底层就是用的HashMap加双链表实现的,而且本身已经实现了按照访问顺序的存储。此外,LinkedHashMap中本身就实现了一个方法removeEldestEntry用于判断是否需要移除最不常读取的数,方法默认是直接返回false,不会移除元素,所以需要重写该方法。即当缓存满后就移除最不常用的数。
由于LinkedHashMap可以记录下Map中元素的访问顺序,所以可以轻易的实现LRU算法。
- 只需要将
构造方法的accessOrder传入true, - 并且
重写removeEldestEntry方法即可。
import java.util.Map;
import java.util.LinkedHashMap;
public class LRU<K,V> {
private static final float hashLoadFactory = 0.75f;
private LinkedHashMap<K,V> map;
private int cacheSize;
public static void main(String[] args) {
LRU<String, String> lru = new LRU<String, String>(5);
lru.put("1", "1");
lru.put("2", "2");
lru.put("3", "3");
lru.put("4", "4");
lru.put("5", "5");
lru.print();
lru.put("6", "6");
lru.print();
lru.get("3");
lru.print();
lru.put("7", "7");
lru.print();
lru.get("5");
lru.print();
}
public LRU(int cacheSize) {
this.cacheSize = cacheSize;
//ceil, 向上取整; floor 向下取整
//计算map容量
int capacity = (int)Math.ceil(cacheSize / hashLoadFactory) + 1;
System.out.println(capacity);
map = new LinkedHashMap<K,V>(capacity, hashLoadFactory, true){
private static final long serialVersionUID = 1;
@Override
protected boolean removeEldestEntry(Map.Entry eldest) {
//map元素个数 > cacheSize时返回true, 移除元素
return size() > LRU.this.cacheSize;
}
};
}
public synchronized V get(K key) {
return map.get(key);
}
public synchronized void put(K key, V value) {
map.put(key, value);
}
public synchronized void clear() {
map.clear();
}
public synchronized int usedSize() {
return map.size();
}
public void print() {
for (Map.Entry<K, V> entry : map.entrySet()) {
System.out.print("key:" + entry.getKey() + ", value:" + entry.getValue() + ". ");
}
System.out.println("");
}
}
控制台输出:
8
key:1, value:1. key:2, value:2. key:3, value:3. key:4, value:4. key:5, value:5.
key:2, value:2. key:3, value:3. key:4, value:4. key:5, value:5. key:6, value:6.
key:2, value:2. key:4, value:4. key:5, value:5. key:6, value:6. key:3, value:3.
key:4, value:4. key:5, value:5. key:6, value:6. key:3, value:3. key:7, value:7.
key:4, value:4. key:6, value:6. key:3, value:3. key:7, value:7. key:5, value:5.
② 双向链表+哈希表实现
题目描述:LeetCode146,LRU缓存机制
运用你所掌握的数据结构,设计和实现一个 LRU (最近最少使用) 缓存机制。它应该支持以下操作: 获取数据 get 和 写入数据 put 。
获取数据 get(key) - 如果关键字 (key) 存在于缓存中,则获取关键字的值(总是正数),否则返回 -1。
写入数据 put(key, value) - 如果关键字已经存在,则变更其数据值;如果关键字不存在,则插入该组「关键字/值」。当缓存容量达到上限时,它应该在写入新数据之前删除最久未使用的数据值,从而为新的数据值留出空间。
进阶:
你是否可以在 O(1) 时间复杂度内完成这两种操作?
示例:
LRUCache cache = new LRUCache( 2 /* 缓存容量 */ );
cache.put(1, 1); // 1
cache.put(2, 2); // 1 2
cache.get(1); // 2 1 返回 1
cache.put(3, 3); // 1 3 该操作会使得关键字 2 作废
cache.get(2); // 1 3 返回 -1 (未找到)
cache.put(4, 4); // 3 4 该操作会使得关键字 1 作废
cache.get(1); // 3 4 返回 -1 (未找到)
cache.get(3); // 4 3 返回 3
cache.get(4); // 3 4 返回 4
算法设计
摘自@labuladong:LRU 策略详解和实现
分析上面的操作过程,要让 put 和 get 方法的时间复杂度为 O(1),我们可以总结出 cache 这个数据结构必要的条件:查找快,插入快,删除快,有顺序之分。
因为显然 cache 必须有顺序之分,以区分最近使用的和久未使用的数据;而且我们要在 cache 中查找键是否已存在;如果容量满了要删除最后一个数据;每次访问还要把数据插入到队头。
那么,什么数据结构同时符合上述条件呢?哈希表查找快,但是数据无固定顺序;链表有顺序之分,插入删除快,但是查找慢。所以结合一下,形成一种新的数据结构:哈希链表。
LRU 缓存算法的核心数据结构就是哈希链表,双向链表和哈希表的结合体。这个数据结构长这样:
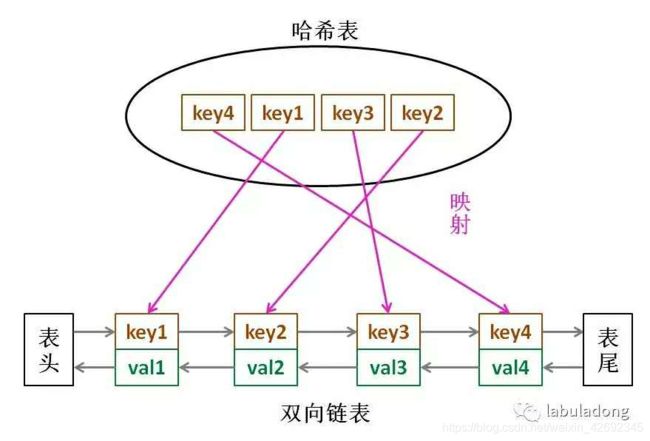
思想很简单,就是借助哈希表赋予了链表快速查找的特性嘛:可以快速查找某个 key 是否存在缓存(链表)中,同时可以快速删除、添加节点。回想刚才的例子,这种数据结构是不是完美解决了 LRU 缓存的需求?
也许读者会问,
- 为什么要是双向链表,单链表行不行?
- 另外,既然哈希表中已经存了 key,为什么链表中还要存键值对呢,只存值不就行了?
【在代码里找答案】
想的时候都是问题,只有做的时候才有答案。这样设计的原因,必须等我们亲自实现 LRU 算法之后才能理解,所以我们开始看代码吧~
代码实现
import java.util.HashMap;
class LRUCache {
// key -> Node(key, val) !!!!!!!! 注意这里键是key, 值是node
private HashMap<Integer, Node> map;
// Node(k1, v1) <-> Node(k2, v2)...
private DoubleList cache;
// 最大容量
private int cap;
public LRUCache(int capacity) {
this.cap = capacity;
map = new HashMap<>();
cache = new DoubleList();
}
public void put(int key, int val) {
// 先把新节点 x 做出来
Node x = new Node(key, val);
if (map.containsKey(key)) {
// 删除旧的节点,新的插到头部
cache.remove(map.get(key));
cache.addFirst(x);
// 更新 map 中对应的数据
map.put(key, x);
} else {
if (cap == cache.size()) {
//删除链表最后一个数据
//注意:
//当缓存容量已满,不仅要删除最后一个 Node 节点,还要把 map 中映射到该节点的 key 同时删除,
//而这个 key 只能由 Node 得到。
//如果 Node 结构中只存储 val,那么我们就无法得知 key 是什么,就无法删除 map 中的键,造成错误。
//所以双向链表不能只存val,必须同时存 key 和 val
Node last = cache.removeLast();
map.remove(last.key);
}
// 直接添加到头部
cache.addFirst(x);
map.put(key, x);
}
}
public int get(int key) {
if (!map.containsKey(key))
return -1;
int val = map.get(key).val;
// 利用 put 方法把该数据提前
put(key, val);
return val;
}
}
//几个需要的 API 操作的时间复杂度均为 O(1)
//为什么必须要用双向链表??
//因为删除一个节点不光要得到该节点本身的指针,也需要操作其前驱节点的指针,
//而双向链表才能支持直接查找前驱,保证操作的时间复杂度 O(1)。
class DoubleList {
private Node head, tail; // 头尾虚节点
private int size; // 链表元素数
public DoubleList() {
head = new Node(0, 0);
tail = new Node(0, 0);
head.next = tail;
tail.prev = head;
size = 0;
}
// 在链表头部添加节点 x
public void addFirst(Node x) {
x.next = head.next;
x.prev = head;
head.next.prev = x;
head.next = x;
size++;
}
// 删除链表中的 x 节点(x 一定存在)
public void remove(Node x) {
x.prev.next = x.next;
x.next.prev = x.prev;
size--;
}
// 删除链表中最后一个节点,并返回该节点
public Node removeLast() {
if (tail.prev == head)
return null;
Node last = tail.prev;
remove(last);
return last;
}
// 返回链表长度
public int size() {
return size;
}
}
//为了简化,key 和 val 都认为是 int 类型
class Node {
public int key, val;
public Node next, prev;
public Node(int k, int v) {
this.key = k;
this.val = v;
}
}
拓展
当存在热点数据时,LRU的效率很好,但偶发性的、周期性的批量操作会导致LRU命中率急剧下降,缓存污染情况比较严重。
1.LRU-K
LRU-K中的K代表最近使用的次数,因此LRU可以认为是LRU-1。LRU-K的主要目的是为了解决LRU算法“缓存污染”的问题,其核心思想是将“最近使用过1次”的判断标准扩展为“最近使用过K次”。
相比LRU,LRU-K需要多维护一个队列,用于记录所有缓存数据被访问的历史。只有当数据的访问次数达到K次的时候,才将数据放入缓存。当需要淘汰数据时,LRU-K会淘汰第K次访问时间距当前时间最大的数据。
数据第一次被访问时,加入到历史访问列表,如果书籍在访问历史列表中没有达到K次访问,则按照一定的规则(FIFO,LRU)淘汰;当访问历史队列中的数据访问次数达到K次后,将数据索引从历史队列中删除,将数据移到缓存队列中,并缓存数据,缓存队列重新按照时间排序;缓存数据队列中被再次访问后,重新排序,需要淘汰数据时,淘汰缓存队列中排在末尾的数据,即“淘汰倒数K次访问离现在最久的数据”。
LRU-K具有LRU的优点,同时还能避免LRU的缺点,实际应用中LRU-2是综合最优的选择。由于LRU-K还需要记录那些被访问过、但还没有放入缓存的对象,因此内存消耗会比LRU要多。
2.two queue
Two queues(以下使用2Q代替)算法类似于LRU-2,不同点在于2Q将LRU-2算法中的访问历史队列(注意这不是缓存数据的)改为一个FIFO缓存队列,即:2Q算法有两个缓存队列,一个是FIFO队列,一个是LRU队列。当数据第一次访问时,2Q算法将数据缓存在FIFO队列里面,当数据第二次被访问时,则将数据从FIFO队列移到LRU队列里面,两个队列各自按照自己的方法淘汰数据。
新访问的数据插入到FIFO队列中,如果数据在FIFO队列中一直没有被再次访问,则最终按照FIFO规则淘汰;如果数据在FIFO队列中再次被访问到,则将数据移到LRU队列头部,如果数据在LRU队列中再次被访问,则将数据移动LRU队列头部,LRU队列淘汰末尾的数据。
3.Multi Queue(MQ)
MQ算法根据访问频率将数据划分为多个队列,不同的队列具有不同的访问优先级,其核心思想是:优先缓存访问次数多的数据。详细的算法结构图如下,Q0,Q1....Qk代表不同的优先级队列,Q-history代表从缓存中淘汰数据,但记录了数据的索引和引用次数的队列:
新插入的数据放入Q0,每个队列按照LRU进行管理,当数据的访问次数达到一定次数,需要提升优先级时,将数据从当前队列中删除,加入到高一级队列的头部;为了防止高优先级数据永远不会被淘汰,当数据在指定的时间里没有被访问时,需要降低优先级,将数据从当前队列删除,加入到低一级的队列头部;需要淘汰数据时,从最低一级队列开始按照LRU淘汰,每个队列淘汰数据时,将数据从缓存中删除,将数据索引加入Q-history头部。如果数据在Q-history中被重新访问,则重新计算其优先级,移到目标队列头部。Q-history按照LRU淘汰数据的索引。
MQ需要维护多个队列,且需要维护每个数据的访问时间,复杂度比LRU高。
LRU算法对比
| 对比点 | 对比 |
|---|---|
| 命中率 | LRU-2 > MQ(2) > 2Q > LRU |
| 复杂度 | LRU-2 > MQ(2) > 2Q > LRU |
| 代价 | LRU-2 > MQ(2) > 2Q > LRU |
参考文章:LRU算法四种实现方式介绍