《Hadoop.The.Definitive.Guide.4th.Edition.2015.3》学习笔记

一.读后感
最近读完了《Hadoop.The.Definitive.Guide.4th.Edition.2015.3》英文第4版,个人感觉这本书是hadoop目前最权威、最全面、最靠谱的书籍,强烈建议大家好好研读。不建议大家去读hadoop权威指南第1版、第2版和第3版,第3版我也看完了,但是里面的知识已经与当前Apache hadoop 2.X严重脱节,比如第3版还在大篇幅的讲解hadoop1.X的jobtracker和tasktracker,这早就被抛弃。
《Hadoop.The.Definitive.Guide.4th.Edition.2015.3》全书从五个部分向读者诠释了hadoop相关知识,第一部分讲解了hadoop的基础知识(mapreduce、HDFS、YARN),第二部分详细讲解了mapreduce,第三部分讲解了hadoop集群的搭建管理和监控,第四部分讲解了hadoop生态圈一系列相关的子项目(Avro Parquet Flume Sqoop Pig Hive Crunch Spark Hbase Zookeeper),第五部分讲解了实战案例。给我感触最深的是第一部分中的YARN,从这里我学习到了FIFO CAPACITY FAIR3种调度器的详细知识,第二部分的mapreduce使我在对mapreduce进行优化时候有了明确的思路不至于那么迷茫,第三部分使我学会了如何站在公司的角度去思考搭建公司级hadoop要考虑的硬件和软件要求,hadoop管理和监控要求,总之,这本书值得购买,值得花时间去读,值得推荐给想了解hadoop又不知选啥资料的国人。
国人也在出hadoop相关书籍,和《Hadoop.The.Definitive.Guide.4th.Edition.2015.3》比起来,大部分可以说是一本文字垃圾,要么片面,要么不够深入,比如一本书就只讲一点YARN解析,另一本书讲mapreduce解析,不免让人觉得这在浪费广大读者的money,读者被动的接受着作者在金钱利益驱动下写下的垃圾,强烈建议这些作者好好学习下《Hadoop.The.Definitive.Guide.4th.Edition.2015.3》,建议出书的作者知识积累丰富点,所讲解的内容尽量囊括在一本书中(不要分成那么多子系列),建议作者要有持续更新版本的忍耐力,建议出书的作者资质再老点,不要是个人弄了几下hadoop就出书,国人很多技术书甚至作者的年龄都在20-35岁,不免让人觉得这些书籍是否可靠,也很少看到这些数据在随着时间的推移过程中持续更新,出第1版,第2版,第3版......可以说很多作者的书籍在第一版本发布后,就永远没了下文,随着时间推移,只会被淘汰。
看了很多hadoop相关的书籍,收获最大的就是《Hadoop.The.Definitive.Guide.4th.Edition.2015.3》,有感而发,在使用hadoop这条路上走过很多弯路,踩过很多坑,对于参考资料,只希望少一点垃圾,多一点经典。
二.HDFS相关问题
1.【HDFS】为何blocksize=128MB?是否需要调大?
答:读取HDFS的block需要做两件事,一是找到block在哪里,也就是寻址,这里消耗的时间为寻址时间,比如需要10毫秒;二是将这个block对应的数据传输到客户端,这里消耗的时间为磁盘传输时间,比如磁盘数据传输速度为128MB/秒,那么128MB数据需要1秒,也即1000毫秒。现在来做个试验,如下表:
| 文件大小 | blocksize | 寻址时间(10ms/block) | 传输时间(128MB/s) | 总计耗时 |
| 128MB | 128MB | 10ms/block*1block | (128MB*1block/(128MB/s))*1block | 1010毫秒 |
| 128MB | 1.28MB | 10ms/block*100block | (1.28MB*1block/(128MB/s))*100block | 2000毫秒 |
上面试验表明:在blocksize比较小的时候,频繁的在进行block的寻址操作,寻址操作越多,所消耗的时间就越多,最终总计耗时越大。试验充分说明了一个问题,要调大blocksize,设置多大好呢?hadoop目前推荐的设置是,寻址时间/传输时间=1%,所以官网上推荐的默认值为128MB,第一个问题回答完毕。
随着磁盘硬件性能的提升,你可以更改这个blocksize,让它大于128MB,比如256MB,不过不建议?这里说下我的理由,目前hadoop中很多地方都是据blocksize=128MB值之上对其他参数进行了默认设置,比如mapreduce.task.io.sort.mb=100MB,splitsize=128MB,hbase中memstore=128MB,这些与blocksize=128MB是有关的,当你变动了blocksize,这些参数你也要相应调整,除非你是hadoop高级掌握者,否则不要轻易的去改动。
2.【HDFS】HDFS中namenode维护什么数据?数据是固定的么?
答:namenode维护两类数据:(1)namespace image(2)edit log
来看下hdfs-site.xml中配置的dfs.namenode.name.dir目录的文件结构:
${dfs.namenode.name.dir}/
├── current
│ ├── VERSION
│ ├── edits_0000000000033667872-0000000000033668028
│ ├── ...
│ ├── edits_0000000000034678717-0000000000034678900
│ ├── edits_0000000000034678901-0000000000034679140
│ ├── edits_0000000000034679141-0000000000034679336
│ ├── edits_inprogress_0000000000034679337
│ ├── fsimage_0000000000034668015
│ ├── fsimage_0000000000034668015.md5
│ ├── fsimage_0000000000034675376
│ ├── fsimage_0000000000034675376.md5
│ └── seen_txid
└── in_use.lock
- edit log文件名为edits_${start_transaction_ID}-${end_transaction_ID}
- 正在进行中的edit log文件名为edits_inprogress_${inprogress_transaction_ID}
- 上面记录的是start_transaction_ID=0000000000034678717,end_transaction_ID=0000000000034678900之间的edit log
- edits_inprogress_0000000000034679337记录的是inprogress_transaction_ID=0000000000034679337的正在进行中的edit log。
- namespace image文件名为fsimage_${merged_transaction_ID}
- fsimage_0000000000034675376说明当前已经完成对于transaction_ID=0000000000034675376的edit log合并后的fsimage
开始第二个问题,namenode维护的逻辑文件系统及其block分布信息不是固定不变的,信息是在变化的,也不会写死,里面的block分布信息在各个datanode启动时候会主动向namenode上报,随着datanode的关闭也会动态更新。
3.【HDFS】HDFS中dfs.namenode.name.dir、dfs.datanode.data.dir、dfs.namenode.checkpoint.dir、dfs.journalnode.edits.dir哪些需要设置多个?各自作用?
| 配置项 | 使用者 | 单节点是否设置多个目录 | 作用 |
| dfs.namenode.name.dir | namenode | 可以多个 | 每个目录是一份独立完整数据, 多个目录就是多份完整独立数据COPY |
| dfs.datanode.data.dir | datanode | 可以多个 | 每个目录中只会存储所有文件数据中的某一部分,所有节点所有目录中才构成一份完成数据的默认3份COPY |
| dfs.namenode.checkpoint.dir | secondary namenode | 可以多个 | 每个目录是一份独立完整数据, 多个目录就是多份完整独立数据COPY |
| dfs.journalnode.edits.dir | journalnode | 只能一个 | 存储的是此journalnode的状态和一部分edit log信息,这份edit log 在大多数其他journalnode上也有备份 |
4.【HDFS】HDFS中namenode+secondarynamenode的冷切换加载过程?HDFS中HA(Active namenode+Standby namenode)热切换和冷切换过程?
答:HDFS中namenode+secondarynamenode的冷切换加载过程:
- (1)namenode宕机
- (2)重新启动namenode或者通过secondarynamenode修复namenode然后启动namenode
- (3)将fsimage加载到内存
- (4)读取未合并的edit log,进行整合合并到fsimage
- (5)接收尽可能多的datanode上报block信息,最终退出safemode,完成namenode冷启动
HDFS中HA(Active namenode+Standby namenode)热切换过程:
- (1)active namenode停止
- (2)ZKFC发现namenode停止,将standby namenode切换为active namenode,完成热切换
HDFS中HA(Active namenode+Standby namenode)冷切换过程(效果比namenode+sencondarynamenode冷切换要好,因为journalnode上edit log不需加载):
- (1)active namenode和standby namenode都停止了
- (2)手动启动active namenode和standby namenode
- (3)将fsimage加载到内存
- (4)读取journalnode未合并的edit log,进行整合合并到fsimage
- (5)接收尽可能多的datanode上报block信息,最终退出safemode,完成namenode冷启动
5.【HDFS】实现HDFS HA的QJM和NFS方式对比?
答:
| HDFS HA方式 | 启动 | 配置 | edit log |
| QJM | 无差别 | 用journalnode存储edit log | 只有一个namenode可写edit log,容易控制 |
| NFS | 无差别 | 用NFS共享edit log | 比较难控制只有一个namenode写edit log |
6.【HDFS】HDFS HA方实现客户端如何实现namenode故障切换的透明化?
答:HDFS HA方式下,服务端配置的hadoop集群名字是个虚拟名称,目前客户端需要配置上这个虚拟名称以及这个名称后面对应的多个namenode节点,从而客户端自己通过检测来实现连接处于active状态的namenode,一定要配置给客户端的必要参数如下:
dfs.nameservices=mycluster dfs.client.failover.proxy.provider.mycluster=org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider dfs.ha.namenodes.mycluster=nn1,nn2 dfs.namenode.rpc-address.mycluster.nn1=192.168.77.38:9000 dfs.namenode.rpc-address.mycluster.nn2=192.168.77.39:9000
7.【HDFS】HDFS中网络距离计算原则?
答:网络距离依次递增,规则如下:
- 同节点上的进程,距离为0
- 同一机架上的不同节点,距离为2
- 同一数据中心中不同机架上的节点,距离为4
- 不同数据中心中的节点,距离为6

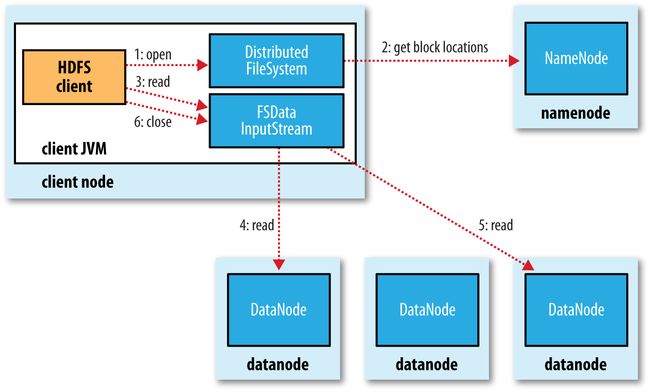
8.【HDFS】HDFS读数据和写数据剖析
答:(1)读数据剖析:
- client从namenode获取block信息;
- client按照顺序一个个先后读取block数据,读取block数据时候,根据上面7中网络距离计算最优block位置进行读取
(2)写数据剖析
- client从namenode获取创建的outputstream
- client只负责写主block,主block负责写第一个备份block,第一个备份block负责写第二个备份block
- 第二个备份block写完毕后ACK到第一个备份block,第一个备份block然后ACK到主block,主block返回ACK给client

9.【HDFS】HDFS中远程拷贝数据distcp如何调优?
答:distcp本质是个mapreduce,使用时候最好指定map和reduce个数,这样效率才会高。
10.【HDFS】HDFS中如何实现数据均衡?
答:
- HDFS默认提供了脚本start-balance.sh启动一个后台进程来均衡各个节点数据
- 节点之间数据传递的带宽默认dfs.data,balance=1MB/s太小,建议设置为10MB/s~50MB/s之间,太大会占有网络资源,太小balance执行的时间会很长
- 判断数据是否均衡的依据是各个节点上的磁盘使用空间/该节点上总的HDFS磁盘空间都不能超过默认值10%,这个比例值可以修改
11.【HDFS】Hadoop支持哪些文件系统?
答:
| 文件系统 | URI前缀 | hadoop的具体实现类 |
| Local | file:// | fs.LocalFileSystem |
| HDFS | hdfs:// | hdfs.DistributedFileSystem |
| WebHDFS | webhdfs:// | hdfs.web.WebHdfsFileSystem |
| Secure WebHDFS | swebhdfs:// | hdfs.web.SWebHdfsFileSystem |
| HAR | har:// | fs.HarFileSystem |
| View | viewfs:// | viewfs.ViewFileSystem |
| FTP | ftp:// | fs.ftp.FTPFileSystem |
| S3 | s3a:// | fs.s3a.S3AFileSystem |
| Azure | wasb:// | fs.azure.NativeAzureFileSystem |
| Swift | swift:// | fs.swift.snative.SwiftNativeFileSystem |
hadoop是提供了对于以上各种文件系统的默认实现,稍作配置即可使用上述文件系统,比如S3 Support in Apache Hadoop 基于Amazon S3的文件系统
HDFS只是hadoop实现的文件系统之一,默认dfs.webhdfs.enabled=true,是开启了WebHDFS,如果觉得不安全,可以设置dfs.webhdfs.enabled=false来禁止WebHDFS。
12.【HDFS】hadoop的文件压缩有啥好处?选择文件压缩格式要考虑哪些因素?支持的文件压缩格式有哪些?不同后缀的文件HDFS是如何编解码读取的?为什么Apache hadoop默认不支持LZO和SNAPPY?LZO对应的文件后缀就是.lzo吗?
答:(1)hadoop的文件压缩好处:
- 减少了存储文件所需的空间;
- 加速了网络、磁盘或磁盘的数据传输
(2)选择文件压缩格式考虑三个因素:
- 文件压缩比例
- 文件解压缩效率
- 该压缩格式的文件是否可被切分,不能切分直接影响mapreduce的map的个数,从而导致mapreduce效率低下
(3)支持的文件压缩格式有哪些:
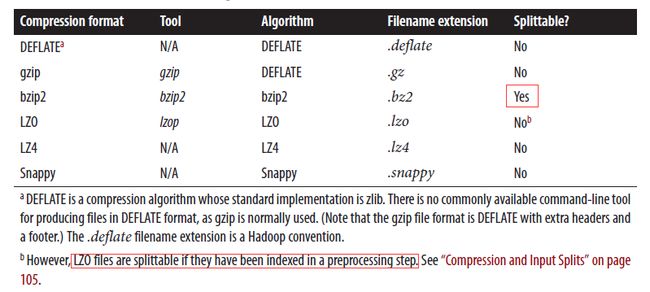
默认Apache hadoop的安装文件提供了Bzip2、Gzip、DEFLATE的支持,只需配置mapreduce.map.output.compress和mapreduce.map.output.compress.codec即可使用,但是在Apache hadoop安装文件里并没有提供对于snappy和LZO的支持,这两个需要自己去安装整合,关于snappy和LZO的安装整合参见如下地址参见我的另外一篇博客hadoop 压缩 gzip biz2 lzo snappy
(4)不同后缀的文件HDFS是如何编解码读取的?
答:HDFS是通过文件后缀名来找编解码的,所以只要你的文件的后缀和相应的编码格式里的文件后缀匹配上了,那么HDFS就能知道用何种编解码,不过前提是对应的编码你首先都集成到hadoop中了,默认Apache hadoop能处理.deflate、.gz、.bz2后缀的文件,因为默认Apache hadoop就不支持LZO和SNAPPY,所以无法读取.snappy、.lzo和.lzo_deflate为后缀的文件,关于LZO和SNAPPY怎么集成到hadoop请参见我的另外一篇博客hadoop 压缩 gzip biz2 lzo snappy
(5)为什么Apache hadoop默认不支持LZO和SNAPPY?
答:Apache hadoop官网提供的hadoop版本本身就支持Bzip2、Gzip、DEFLATE3种压缩格式,不支持Snappy和LZO格式,原因是Snappy和LZO的代码库拥有GPL开源协议许可,而不是Apache开源协议许可,关于Snappy和LZO需要hadoop运维或者hadoop提供商自己集成。关于开源代码协议GPL、BSD、MIT、Mozilla、Apache和LGPL的区别详见下图:

(6)LZO对应的文件后缀就是.lzo吗?
答:hadoop是根据文件的后缀去寻找编解码用哪个,之前认为com.hadoop.compression.lzo.LzoCodec对应的后缀为".lzo"是错误的,查看了hadoop-lzo源代码发现".lzo"对应的编解码为com.hadoop.compression.lzo.LzopCodec,查看了源代码发现".lzo_deflate"对应的编解码为com.hadoop.compression.lzo.LzoCodec
13.【HDFS】hadoop支持的结构化文件类型有哪些?
答:hadoop支持的结构化文件类型有如下:
- SequenceFile,是一个由二进制序列化过的key/value的字节流组成的文本存储文件;
- MapFile,是排序后的SequenceFile两部分组成,分别是data和index;
- Apache Avro,是一个基于二进制数据传输高性能的中间件,是一个数据序列化的系统,可以将数据结构或对象转化成便于存储或传输的格式,用来支持数据密集型应用,适合于远程或本地大规模数据的存储和交换;
- Apache ORC,(OptimizedRC File)存储源自于RC(RecordColumnar File)这种存储格式,RC是一种列式存储引擎,对schema演化(修改schema需要重新生成数据)支持较差,而ORC是对RC改进,但它仍对schema演化支持较差,主要是在压缩编码,查询性能方面做了优化。RC/ORC最初是在Hive中得到使用,最后发展势头不错,独立成一个单独的项目。Hive 1.x版本对事务和update操作的支持,便是基于ORC实现的(其他存储格式暂不支持)。ORC发展到今天,已经具备一些非常高级的feature,比如支持update操作,支持ACID,支持struct,array复杂类型。你可以使用复杂类型构建一个类似于parquet的嵌套式数据架构,但当层数非常多时,写起来非常麻烦和复杂,而parquet提供的schema表达方式更容易表示出多级嵌套的数据类型;
- Apache Parquet, 最初的设计动机是存储嵌套式数据,比如Protocolbuffer,thrift,json等,将这类数据存储成列式格式,以方便对其高效压缩和编码,且使用更少的IO操作取出需要的数据,这也是Parquet相比于ORC的优势,它能够透明地将Protobuf和thrift类型的数据进行列式存储,在Protobuf和thrift被广泛使用的今天,与parquet进行集成,是一件非容易和自然的事情。 除了上述优势外,相比于ORC, Parquet没有太多其他可圈可点的地方,比如它不支持update操作(数据写成后不可修改),不支持ACID等
三.YARN相关问题
1.【YARN】YARN运行application的流程?
答:
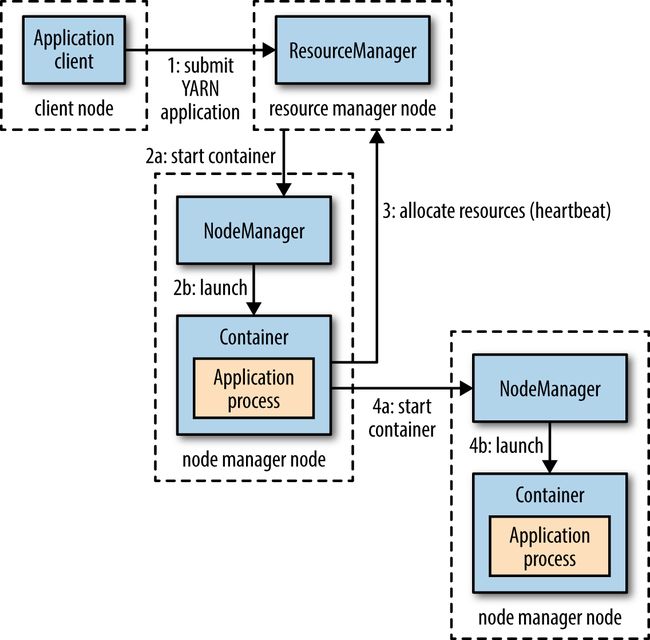


(1)ResourceManager进行资源分配时,采用了和HDFS相同的网络距离计算算法,尽量把block所在节点让NodeManager启动containner;
(2)执行的具体流程如下:
- client请求执行application
- ResourceManager分配一个节点NodeManager启动containner,这个containner执行一个Application Master;
- Application Master判定当前client提交的application为小任务,无需请求ResourceManager去分派NodeManager启动额外的containner来并发处理,只在当前Application Master所在containner里执行整个application;
- Application Master判定当前client提交的application不是小任务,就请求ResourceManager去分派NodeManager启动额外的containner来并发处理
(3)判定client提交的application为小任务的依据:
- application对应的job的map的个数<10,mapreduce.job.ubertask.maxmaps可以更改默认值;
- application对应的job的reduce个数为1,mapreduce.job.ubertask.maxreduces可以更改默认值;
- application对应的文件数据大小
- 默认mapreduce.job.ubertask.enable=false,默认没有开启小任务,要开启必须设置为true
2.【YARN】基于YARN简化YARN的其他框架
答:
(1)Apache Slider 是一个 Yarn 应用,它可以用来在 Yarn 上部署并监控分布式应用。Slider 可以在应用运行期随意扩展或者收缩应用。目前它是 Apache 的孵化项目。参见董西城的Apache Slider—将已有服务或者应用运行在YARN上

(2)Apache Twill(官方首页:Apache Twill)这个项目则是为简化YARN上应用程序开发而成立的项目,该项目把与YARN相关的重复性的工作封装成库,使得用户可以专注于自己的应用程序逻辑。参见董西城的Apache Twill—YARN上应用程序开发包

3.【YARN】YARN与MapReduce1的比较
答:

(1)hadoop version<=2.5.1,使用job historyserver,默认MapReduce Application Master将Job history存储在HDFS上,保留的期限是7天,存储的路径通过mapreduce.jobhistory.done-dir设置;
(2)hadoop version> 2.5.1,使用timelineserver,historyserver仍然保留。application history server支持MapReduce作业,引入timeline server之后,Application History Server变成了Timeline Server的一个应用,history服务基于timeline store建立,history可以存储在内存中或者采用leveldb数据库存储,采用leveldb数据库存储可以保证history在timeline server 重启后仍会保留。
4.【YARN】YARN提供的三种调度?
答:
|
|
FIFO |
CAPACITY |
FAIR |
| 描述 | 每一个job占有所有资源,第二个job等第一个job执行完毕才开始执行 |
预先按照设定的queue资源比例为每个queue预留资源,一个job在queue对应的资源下执行,这个job所在queue不会占有所有资源,同一queue里面不同job仍然按照FIFO执行 |
各个queue按照预设的比重获得资源,当只有一个job时候,独占所有资源,不过也可以设置最大资源来限制独占所有资源,此时如果有第二个queue里启动了job,那么会通过延迟调度等待资源或者通过资源抢占来让第一个job腾出资源 |
| 特点 | 先进先出, 资源独占 |
不同组按比例分配资源, 不同组的比例之和为100%, 同组内按照FIFO处理, 只有一个组时也不会独占资源,存在资源浪费 |
不同组按照权重对应比例分配总资源, 只有一个组时可以独占资源, 多个组运行时,会腾出资源, 同组内可设置FAIR、FIFO、DRF |
| Apache hadoop | 默认调度策略 | ||
| Cloudera hadoop | 默认调度策略 | ||
| 指定queue | 通过mapreduce.job.queuename指定使用哪个queue | 默认通过规则来自己判定用哪个queue。 1)specified意思是按照mapreduce.job.queuename值判断用哪个queue 2)primaryGroup意思是按照client所在用户组去找queue 3)user意思是按照client所在用户去找queue |
|
| 配置文件 | capacity-scheludel.xml |
fair-scheduler.xml 可修改yarn.scheduler.fair.allocation.file修改配置文件名字 |
|
| 资源抢占 | FAIR支持资源抢占: 1)minum.share.preemption.timeout时间未获得最小资源要求,进行资源抢占; 通过defaultMinSharePreemptionTimeout设置所有queue超时; 通过minSharePreemptionTimeout设置单个queue超时 2)fair.share.preemption.timeout未获得资源要求的50%,进行资源抢占; 通过defaultFairSharePreemptionTimeout设置所有queue超时; 通过fairSharePreemptionTimeout设置单个queue超时; 通过defaultFairSharePreemptionThreshold设置所有queue最低资源要求比例(默认0.5); 通过fairSharePreemptionThreshold设置单个queue最低资源要求比例(默认0.5) |
||
| 延迟调度 | 可以设置延迟等待,以便等待最优的资源被分配来执行job(比如尽量离block最近)
yarn.scheduler.capacity.node-locality-delay设置一个正整数N,代表错过N次调度机会后放弃延迟等待 |
可以设置延迟等待,以便等待最优的资源被分配来执行job(比如尽量离block最近)
yarn.scheduler.fair.locality.threshold.node设置一个浮点数,代表等待直到这个比例的节点资源处于空闲就开始执行job
yarn.scheduler.fair.locality.threshold.rack设置正整数,代表当应用程序请求某个机架上资源时,它可以接受的可跳过的最大资源调度机会 |
|
| DRF(Dominant Resource Fairness) | 同时考虑CPU和MEMORY两个资源,默认DRF为开启,默认只考虑MEMORE不考虑CPU
通过设置yarn.scheduler.capacity.resource-calculator=org.apache.hadoop.yarn.util.resource.DominantResourceCalculator来在容量调度开启DRF |
同时考虑CPU和MEMORY两个资源,默认DRF为开启,默认只考虑MEMORE不考虑CPU
通过设置fair-scheduler.xml中的defaultQueueSchedulingPolicy=drf来在公平调度里开启DRF |

四.MapReduce相关问题
1.【MapReduce】MapReduce的配置Configuration的加载规则?
答:(1)后加载的配置信息会覆盖之前加载的信息;
(2)加了Final的配置项不可被覆盖;
(3)配置文件中定义在前的属性可通过${属性name}在后面进行引用;
(4)可以使用System设置配置属性;
(5)可以使用JDK的-Dproterty=value设置配置属性。
2.【MapReduce】MapReduce的maven开发环境如何设置?MapReduce默认提供了哪些工具类方便开发调试?
答:(1)maven中添加hadoop-client依赖jar,该jar包含所有客户端与HDFS和MAPREDUCE相关的所有类;maven中添加hadoop-minicluster依赖jar,该jar支持在单个JVM中模拟hadoop集群进行测试
(2)ToolRunner是hadoop提供的工具类以减轻shell脚本的工作,它里面的使用的是工具类GernericOptionsParser作用是与hadoop命令行配置信息交互并将这行配置设置到Configuration对象上;
MRUnit可以用来在本地用断言的方式测试mapreduce程序,比如MRUnit.MapDriver可以构造map的输入信息。
4.0.0 com.hadoopbook hadoop-book-mr-dev 4.0 UTF-8 2.5.1 org.apache.hadoop hadoop-client ${hadoop.version} junit junit 4.11 test org.apache.mrunit mrunit 1.1.0 hadoop2 test org.apache.hadoop hadoop-minicluster ${hadoop.version} test hadoop-examples org.apache.maven.plugins maven-compiler-plugin 3.1 1.6 1.6 org.apache.maven.plugins maven-jar-plugin 2.5 ${basedir}
3.【MapReduce】MapReduce程序提交被运行时候的用户身份信息是什么?
答:
(1)默认hadoop是没有开启提交mapreduce程序的用户身份认证,因为hadoop.security.authorization=false
(2)默认hadoop的client所在用户组和用户信息会被作为参数传入到服务端与HDFS文件权限进行匹配
(3)如果client所在用户组和用户于HDFS权限体系不同,可通过HADOOP_USER_NAME或者hadoop.user.group.static.mapping.overides设置
(4)WebHdfs交互的用户权限可通过hadoop.http.staticuser.user设置
4.【MapReduce】MapReduce默认加载的配置文件的路径是啥?开发者如何知道哪些配置属性可被设置?开发者如何设置让hadoop优先加载自己使用的第三方jar
答:
(1)默认通过环境变量HADOOP_HOME和HADOOP_CONF_DIR寻找配置文件,另外一种方法是可以通过-conf指定配置文件;
(2)开发者可以通过工具类GernericOptionsParser类加载Configuration配置文件后,将所有配置信息打印出来,这是方法一;第二种方法是去hadoop官网进行查询
(3)开发者可以设置HADOOP_USER_CLASSPATH_FIRST=true和mapreduce.job.user.classpath.first=true来让hadoop优先加载用户自己的jar。
5.【MapReduce】MapReduce中Job、Task和AttemptTask的命名规则?
答:
(1)首先,所有在YARN resource manager上运行的application的命名规则是:application_${时间戳}_${第几个application程序},比如application_1410450250506_0003代表是在时间戳1410450250506经YARN resource manager运行的第0003个application程序;
(2)Job的命名规则是继承了部分application的信息,规则是:job_${时间戳}_${第几个application程序},比如job_1410450250506_0003代表是在时间戳1410450250506经YARN resource manager运行的第0003个application程序的job;
(3)Task的命令规则有继承了Job的信息,规则是:task_${时间戳}_${第几个application程序}_${m代表map,r代表reduce}_${第几个map程序或者第几个reduce程序},比如task_1410450250506_0003_m_000003代表是在时间戳1410450250506经YARN resource manager运行的第0003个application程序job里对应的第000003个map程序,task_1410450250506_0003_r_000001代表是在时间戳1410450250506经YARN resource manager运行的第0003个application程序job里对应的第000001个reduce程序;
(4)AttemptTask是在Task失败后尝试执行的任务,它的命名规则:attempt_${时间戳}_${第几个application程序}_${m代表map,r代表reduce}_${第几个map程序或者第几个reduce程序}_${尝试次数},比如attempt_1410450250506_0003_m_000003_0代表是在时间戳1410450250506经YARN resource manager运行的第0003个application程序job里对应的第000003个map程序失败后又被执行了一次
6.【MapReduce】hadoop提供哪些日志,这些日志放置在哪里?
| 日志类型 | 归属 | 描述 |
| System daemon logs | Administrators | (1)后台进程namenode、datanode、journalnode、zkfc、nodemanager、resoucemanager等产生的日志默认存放在HADOOP_HOME/logs,可以设置HADOOP_LOG_DIR改变日志目录位置,如果目录不存在hadoop会主动创建但必须要给权限; (2).log结尾的日志按天存储,所有日志不会主动删除,会永久保留; (3).out结尾的日志默认保留最近的5个,会自动清理过期的日志 |
| HDFS audit logs | Administrators | 记录所有的HDFS的请求的日志,写入后台进程namenode的.log日志文件,默认是关闭的可以配置开启 |
| MapReduce job history logs | Users | MapReduce Application Master将Job history存储在HDFS上,保留的期限是7天,存储的路径通过mapreduce.jobhistory.done-dir设置 |
| MapReduce task logs | Users | (1)记录每个Task相关程序产生的日志,日志有syslog stdout stderr3类 (2)存放的目录通过环境变量YARN_LOG_DIR设置,默认在linux机器的YARN_LOG_DIR/userlogs目录下面 |
7.【MapReduce】MapReduce的执行有哪些可供使用的工作流框架?
答:
(1)Apache oozie
(2)Apache Azkaban
8.【MapReduce】MapReduce Job如何进行优化?
答:通常的优化检查列表如下:
| 优化项 | 优化建议 |
| map个数 | (1)关注map个数以及每个map执行消耗的平均时间,使得每个map执行平均时间在一个合理范围(合理建议:map平均耗时在1分钟左右) (2)处理的数据文件的格式直接影响到map,不可分割的文件压缩格式比如SNAPPY使得大的数据文件无法被切分从而导致有些map消耗过多时间;合理的结构化文件比如Apache ORC可以提升hive的效率; (3)大量的小文件不仅增加寻址总耗时,也会加剧map任务量大小,建议是添加CombineFileInputFormat将小文件进行整合 |
| reduce个数 | (1)确保reduce个数大于1(合理建议:reduce平均耗时5分钟左右,每个reduce写的数据大小刚好一个blocksize=128MB大小) (2)reduce个数不能多不能少,个数的依据是尽量使得每个reduce刚好写一个blocksize=128MB大小的文件。 |
| Combiners | (1)确保数据从map出来到达reduce之间使用了combiners来较少这之间shuffle传递的数据 |
| Intermediate Compression | (1)设置mapreduce中间值的压缩,减少了存储文件所需的空间,加速了网络、磁盘或磁盘的数据传输; (2)设置mapreduce.map.output.compress=true,默认mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.DefaoultCodec,可以设置其它压缩格式比如LZO LZ4 Snappy |
| Custom serialization | (1)自定义序列必须保证实现了RawComparator |
| Shuffle tweaks | (1)MapRduce的shuffle过程可以对一些内存管理的参数进行调整,以弥补性能的不足 (2)深入了解map端的shuffle过程,然后对其内存进行优化; (3)深入了解reduce端的shuffle过程,然后对其内存进行优化。 |
9.【MapReduce】MapReduce job参与实体有哪些?MapReduce job是如何运作的?
答:
(1)MapReduce job的参与实体有:
- Client 提交MapReduce job
- YARN resource manager 协调集群上计算资源的分配
- YARN node managers 负责集群中计算容器的启动和监视
- MapReduce application master 用于协调运行Map-Reduce job的MapReduce tasks。MapReduce application master和MapReduce tasks都运行在由resource manager分配由node managers管理的容器中。
- HDFS 用于job之间共享数据
(2)MapReduce job运作流程:
1)MapReduce job提交:client调用Job.submit()方法会产生一个JobSubmitter对象,然后调用JobSubmitter.submitJobInternal()提交Job,最后通过Job.waitForCompletion()每秒中获取Job的运行状态同时通知console状态变化,否则通知console错误日志信息。详细过程如下:
- 向YARN resource manager申请一个新的application ID,比如application_1410450250506_0003代表是在时间戳1410450250506经YARN resource manager运行的第0003个application程序,也即下图的“步骤2”
- 如果输出目录已经存在或者没有设置,MapReduce job不会被提交,直接产生一个错误通知client
- 如果输入数据不存在,那就无法计算输入数据切分信息,MapReduce job不会被提交,直接产生一个错误通知client
- 将MapReduce job相关的jar(默认在HDFS中的备份数mapreduce.client.submit.file.replication=10,以便nodemanager上的task共享MapReduce job的jar信息)、MapReduce job相关配置文件、输入数据切分信息拷贝到分布式文件系统HDFS上进行共享,也即下图的“步骤3”
- 调用submitApplicatioon()发送请求到YARN resource manager,也即下图中的“步骤4”
2)MapReduce job初始化
- YARN resource manager收到submitApplicatioon请求,传递给YARN scheduler获取一个YARN node manager下的container容器,然后YARN resource manager在这个容器containner里启动MapReduce application master,也即下图的“步骤5a和步骤5b”
- MapReduce application master对应的java主函数所在类class为MRAppMaster,MRAppMaster创建一系列跟踪对象来跟踪MapReduce job的工作进度,也即下图的“步骤6”
- MRAppMaster从分布式文件系统HDFS上获取输入数据切分信息,也即下图的“步骤7”,根据输入数据切分信息针对每个切分的block创建一个对应的map task(输入数据切分信息个数决定map task个数),根据方法setMumReduceTasks()设置的值或者mapreduce.job.reduces设置的值,创建对应个数的reduce task
- MRAppMaster判定MapReduce job是否为小任务【map的个数
3)TASK分配
- 如果未开启小任务判断或者判定为非小任务,那么就行后续task分配,MapReduce application master向YARN resource manager请求执行map task或者reduce task任务所需分布在YARN node manager下的containner,也即下图的“步骤8”
- map task的优先级高于reduce task,map task最先被分配执行,sort task和shuffletask必须等待所有map task执行完毕后才可以开始,reduce task默认在5%的map task执行完毕后便开始启动执行。reduce task可以运行于任意节点之上,而map task则会尽量安排在block所在节点运行或者block所在rack 上运行,最后也有可能安排在其他rack运行。
- 上面的map task、sort task、shuffle task、reduce task的请求里也包含这对于CPU 和 MEMORY的特殊配置请求(默认mapreduce.map.memory.mb=1G,mapreduce.map.cpu.vcores=1 默认mapreduce.reduce.memory.mb=1G,mapreduce.reduce.cpu.vcores=1)
4)TASK运行
- 一旦TASK被YARN resource manager分配在某个YARN node manager下的containner执行,MapReduce application master便和这个YARN node manager取得联系并启动一个containner运行一个主类class为YarnChild(YarnChild运行在独立的JVM,并不是和TASK运行在同一个JVM,这样TASK的运行不会影响到YarnChild)的主程序,也即下图的“步骤9a和9b”
- YarnChild在运行TASK之前,先从分布式文件系统HDFS获取client提交的MapReduce job相关jar同步到本地、获取client提交的配置信息,也即下图中的“步骤10”
- 最后YarnChild开始运行TASK,也即下图中的“步骤11”

5)进度和状态更新
- map task通过输入数据已经处理的比例来定期更新其状态;
- reduce task比较复杂,reduce task首先将数据的处理分为三个阶段(COPY阶段占比1/3,SORT阶段占比1/3,REDUCE阶段占比1/3),完成了COPY阶段进度就是1/3,完成了SORT阶段进度就是2/3,完成了一半的REDUCE阶段进度就是1/3+1/3+1/3*1/2=5/6
- TASK还有一系列的计数器用来跟踪处理进度
- TASK运行的过程中,YarnChild时刻保持与MapReduce application master的联系,每隔3秒向MapReduce application master汇报该MapReduce job的TASK的进度和状态,YARN resource manager的WEB管理端通过链接到各个运行的MapReduce application master来展现它们负责的目前正在运行的MapReduce job的进度和状态。
- 在MapReduce job运行期间,client每秒(可设置mapreduce.client.progressmonitor.pollinterval来调整时间间隔)向MapReduce application master轮询MapReduce job的状态,client可以主动调用getStatus()来获取MapReduce job的状态信息,获取流程如下图所示:

6)MapReduce job完成
- 当MapReduce application master收到最后一个TASK完成的通知后,MapReduce application master负责将MapReduce job的status调整为successful,这样当client每秒向MapReduce application master轮询MapReduce job的状态就可以知道job已经完成,就会主动退出waitForCompletion(),然后在控制台console打印job统计信息和相关计数器信息
- 如果设置了mapreduce.job.end-notification.url,那么MapReduce application master在得知MapReduce job完成后,会将MapReduce job的信息(统计信息、计数器信息)通知到这个地址,这给了我们一个提示,我们是不是可以设置一个汇聚MapReduce job处理完成的管理中心
- MapReduce application master和相关容器containner清理各自状态(中间临时数据目录此刻会被删除)
- OutputCommitter.commitJob()会被调用,运行完成的MapReduce job信息会被存档到historyserver上一遍client所在用户进行信息查询追溯
10.【MapReduce】MapReduce job对于失败是如何处理的?如何进行重试?哪些参数与失败尝试相关?
答:
(1)MapReduce job失败相关处理:
- 第一种失败是由于MapReduce job里MapReduce tasks的用户代码导致的失败,MapReduce task所在JVM上报错误信息给MapReduce application master,错误信息会写入用户日志,MapReduce application master获知错误信息后尝试启动MapReduce AttemptTask重试,同时释放之前失败JVM所在containner资源以便可以执行其它MapReduce task
- 第二种失败是由于MapReduce tasks所在JVM的BUG导致的失败,此时YARN node manager发现该JVM进程退出后会通知MapReduce application master,MapReduce application master获知错误信息后尝试启动MapReduce AttemptTask重试
- 第三种失败是由于MapReduce task一直处于假死状态,MapReduce application master在有效的时间(mapreduce.task.timeout=6000000毫秒,也即10分钟,实际中不建议设置为0,0代表永远不过期,那么最终假死的MapReduce task会越来越多,最终使得集群被撑死)未收到进度更新,便标记该MapReduce task为失败
- 当MapReduce application master获知MapReduce task失败后,会启动MapReduce AttemptTask重试,并且尽量不安排在之前出问题的YARN node manager上执行MapReduce AttemptTask。总之,任何MapReduce task的最大重试次数为4次(可设置mapreduce.map.maxattempts更改默认的最大的map task尝试次数4次,可设置mapreduce.reduce.maxattempts更改默认的最大reduce task尝试次数4次),超过4次,不会再次尝试执行MapReduce AttemptTask,任何MapReduce job的MapReduce tasks尝试总次数不能大于4次,否则视MapReduce job失败
- 对于MapReduce job,在某些场合只要MapReduce tasks失败的比例控制在一定范围,仍然认为该MapReduce job是可信可用的,这时候可以通过参数mapreduce.map.failures.maxpercent和mapreduce.reduce.failures.maxpercent分别设置最大的允许map task和reduce task失败的比例
- MapReduce AttemptTask也可能存在失败的情况,比如在推测任务Speculative Execution(MapReduce job的MapReduce tasks有快有慢,针对那些假死或者耗时的task,会启动一个和该TASK一样的另外一个推测任务MapReduce task并行执行,当推测TASK在原TASK执行完之前完成那么原TASK被中止,当推测TASK在原TASK执行完之后完成那么推测TASK被中止;推测TASK只会在MapReduce job的所有MapReduce tasks都启动后才会开始被启动)被中止或者由于YARN node manager错误导致该YARN node manager上所有MapReduce tasks被标记为失败,此时的MapReduce AttemptTask失败不会导致之前map task或者reduce task的最大尝试次数计数器的累加,毕竟不是MapReduce AttemptTask的过错导致的问题。
(2)MapReduce application master的失败相关处理:
- MapReduce application master的最大失败尝试次数通过mapreduce.am.max-attempts(默认值为2)进行设置,大于2次则MapReduce job失败。YARN通过yarn.resourcemanager.am.max-attempts(默认值为2)设置了一个阈值对所有的MapReduce application master有效,而mapreduce.am.max-attempts的值必须小于此值,所以如果想增大mapreduce.am.max-attempts的值,必须先增大yarn.resourcemanager.am.max-attempts的值
- YARN resource manager未收到未收到MapReduce application master的定期心跳包判定MapReduce application master出错,YARN resource manager会在一个新的containner容器中启动新的MapReduce application master,通过job history来恢复(默认yarn.app.mapreduce.am.job.recovery.enable=true开启了恢复)在旧的MapReduce application master上运行的MapReduce tasks的状态
- client在MapReduce job初始化的时候将YARN resource manager反馈的MapReduce application master地址缓存在了本地,当MapReduce application master出错后,client发现一定期限内没有状态更新,就会向YARN resource manager请求新的MapReduce application master的地址
(3)YARN node manager的失败相关处理:
- YARN resource manager在有效的时间(yarn.resourcemanager.nm.liveness-monitor.expiry-interval-ms=600000毫秒)未收到YARN node manager的心跳包则视YARN node manager出错,此时运行于此YARN node manager上的MapReduce application master和MapReduce tasks按照之前的流程进行恢复或者重试。
- YARN node manager出错导致的不完整MapReduce job(所有map task已经执行完毕,但是map task的中间结果已经不可被reduce task读取),那么该MapReduce job对应的所有map task会被重新执行。
- 不管YARN node manager是否出错,只要YARN node manager上MapReduce application master出错的次数如果大于mapreduce.job.maxtaskfailures.per.tracker(默认值为3),则YARN node manager会被MapReduce application master列入黑名单,被列入黑名单后,MapReduce application master会尽可能让MapReduce tasks在其它YARN node manager上运行
(4)YARN resource manager的失败相关处理:
- YARN resource manager的失败是当前最严重的威胁,解决的最好办法是启动多个YARN resource manager,其中只有一个处于active状态,其他都处于standby状态;
- MapReduce job的运行信息都被存储在高可用的状态存储器(比如HDFS ZOOKEEPER).1)处于standby状态的YARN resource manager可以在active的YARN resource manager出错后马上从高可用的状态存储器(比如HDFS ZOOKEEPER)进行恢复。2)YARN node manager的信息并没有存储到高可用的状态存储器(比如HDFS ZOOKEEPER),因为新的active YARN resource manager可以从YARN node manager的心跳包中重新建立联系.3)MapReduce job的MapReduce tasks的状态只被对应的MapReduce application master管理,虽然没存储在高可用的状态存储器(比如HDFS ZOOKEEPER),但也不会丢失,先对mapreduce1是一大进步。
- 当新的YARN resource manager被active后,会从高可用的状态存储器(比如HDFS ZOOKEEPER)读取信息并重新启动所有的MapReduce application master,但是不会把计数器yarn.resourcemanager.am.max-attempts(默认为2)的值进行增1,因为毕竟不是MapReduce application master自己出问题。
- 我们知道HDFS的HA的高可用切换是有一个后台进程ZKFC进行控制,而这里YARN resource manager的HA的控制则并不是一个单独的后台进程控制,而是被嵌入到每一个YARN resource manager,用zookeeper的选举来维持永远只有一个YARN resource manager处于active状态。
- 默认yarn.resourcemanager.recovery.enabled=false并未启用YARN resource manager失败后的恢复功能
- 默认yarn.resourcemanager.store.class=org.apache.hadoop.yarn.server.resourcemanager.recovery.FileSystemRMStateStore意思是YARN resource manager将状态信息存储到${hadoop.tmp.dir}/yarn/system/rmstore中,而这个目录是linux本地,在YARN resource manager恢复时候肯定是不可取的,一定要设置到HDFS打头的目录,比如:hdfs://localhost:9000/rmstore,这样才可以从HDFS高可用恢复数据
- 设置yarn.resourcemanager.store.class=org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore可将状态信息存储到zookeeper,此时通过yarn.resourcemanager.zk-state-store.parent-path=/rmstore设置zookeeper中数据存储目录,这样才可以从zookeeper中高可用恢复数据
11.【MapReduce】MapReduce中shuffle是什么?shuffle和sort的具体流程?从map task端shuffle和sort流程?reduce task端shuffle和sort流程?如何优化MapReduce job?
答:MapReduce会确保从map task产生的结果传输到reduce task时候数据都已经进行了排序处理,从map task到reduce task中间对于数据的排序处理和传输处理就是MapReduce的shuffle;
map task和reduce task是的执行可能在不同的机器节点上YARN node manager写下的containner,所以要了解shuffle和sort的具体流程需要分别站在map task和reduce task的角度去看待;
(1)map task端的shuffle处理

1)每个map task持有一个环形的内存缓冲区buffer用于存储map task输出。缓冲区默认大小为100M(可以通过mapreduce.task.io.sort.mb设置)。一旦缓冲的内容达到阈值(mapre
duce.map.sort.spill.percent,默认0.80),会开启一个后台线程,将buffer内容spill(溢出)到本地linux磁盘。map task的输出继续写到缓冲区buffer,但如果在此期间缓冲区buffer被填满,map task会被阻塞直到写磁盘过程完成。溢出写过程按轮询方式将缓冲区内容写到mapreduce.cluster.local.dir属性指定的linux目录中
2)map task的buffer数据在写入linux磁盘前,那个开启的后台线程首先根据最终要输出的reducer将数据分区。在每个分区中,后台线程会在内存中按key执行排序,如果client设置了combiner,它就在排序后的输出上运行。运行combine函数会使map输出更加紧凑,减少写到磁盘的数据和传递给reducer的数据
3)map task的buffer每次达到阈值后,都会新建一个spill文件。因此在map写完其最后一个输出记录后,会有几个溢出文件。在task完成之前,spil文件被合并成一个已分区且已排序的输出文件。mapreduce.task.io.sort.factor属性控制着一次最多能合并多少流,默认值为10
4)如果至少存在3个spill文件(mapreduce.map.combine.minspills可以配置),这output写入到磁盘之前会再次运行combiner。反复调用combiner不会对最终结果产生影响。如果只有一个或者两个spill 文件,那么就不值得再对map输出调用combiner,所以不会再运行combiner。
5)建议将map输出结果压缩后再写到磁盘,这样写入磁盘会更快,节约磁盘空间,并且减少传给reducer的数据量。在默认情况下,输出是不压缩的,需要将mapreduce.map.output.compress设置未true。使用的压缩库由mapreduce.map.output.compress.codec属性指定
6)reduce task通过HTTP方式得到map task输出文件的分区,文件分区的工作线程的数量是由属性mapre
duce.shuffle.max.threads(默认值为0,此时默认是处理器数量的2倍,这个应该是继承自netty的reactor线程池设置)控制的,此设置是针对每一个YARN nodemanager,不是针对每个map task
(2)reduce task端的shuffle处理
1)map task的输出文件都存储在linux上mapreduce.cluster.local.dir目录中,一个reduce task需要的是来自多个map task输出文件中的特殊parttion数据。每个map task的完成时间可能不同,因此只要有一个map task完成,reduce task就开始复制map task输出,reduce task有少量的copier线程来并行的取得map task的输出,默认为5个线程,并且可以通过mapreduce.reduce.shuffle.parallelcopies属性设置
2)reduce task如何知道要从哪台机器取得map输出的呢? map task成功完成后,它会通过heartbeat机制通知MapReduce application master。因此,对于一个MapReduce job,MapReduce application master知道 map output和hosts之间的映射。reduce task会有一个线程轮询MapReduce application master获取map task输出的位置,直至获取所有输出的位置
3)如果map task的输出足够小,会被拷贝到reduce task的JVM内存中(mapreduce.reduce.shuffle.input.buffer.percent设置用于此用途的内存占有堆空间JVM的百分比,默认为0.70,意思是JVM*0.70),否则,将会被复制到磁盘。一旦达到缓冲区大小的阈值时(mapreduce.reduce.shuffle.merge.percent,默认值0.66,此时阈值为JVM*0.70*0.66)或者达到map task输出的阈值(mapreduce.reduce.merge.inmem.threshold,意思是拷贝来自map task的输出文件个数大于1000则合并写到磁盘),则合并后spill到磁盘。如果指定combiner,则在合并期间运行它,降低写入硬盘的数据量
4)当从map task复制而来的副本在reduce task的本地linux上累积时,一个后台线程被启动来合并这些文件,如果之前map task的输出被压缩过此时会被解压然后在内存中进行合并。
5)复制完所有的map task输出后,reduce task进入sort阶段(准确的说是merge阶段,sort是在map端发生的),这个阶段维持map输出的顺序,合并map task输出,最后直接将结果写入HDFS,HDFS的第一个block一般会优先写入nodemanager所在机器上的datanode。举个例子:如果有50个map outputs,merge factor是10(mapreduce.task.io.sort.factor可以设置大小),合并将进行5次,每10个文件合并成一个文件,最后有5个中间文件。 最后将这个5个文件合并未一个文件是调用的reduce函数。
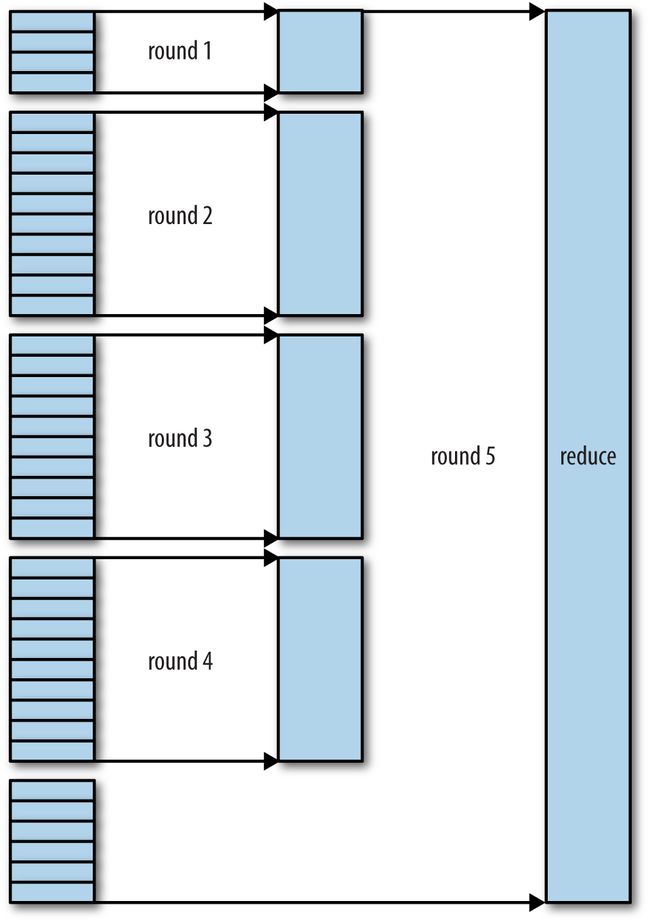
(3)熟悉了MapReduce job的map task和reduce task各自的shuffle之后,如何优化MapReduce job?
1)优化建议如下:
- 总的原则:尽可能多的分配内存给shuffle;
- 第二点是优化MapReduce task所在JVM内存,默认不管map task和reduce task,它们的JVM内存都是通过mapred.child.java.opts设置;
- 在map task里面,尽可能的优化mapreduce.task.io.sort.*属性来避免map task端spill数据到linux磁盘,比如增大mapreduce.task.io.sort.mb的设置,实战中可以通过观察hadoop的计数器SPILLED_RECORDS来调整,这个也用于reduce task;
- 在reduce task里面,尽可能的让reduce task的中间结果数据存储于内存中。比如对于内存需求低的reduce task,可以设置mapreduce.reduce.input.buffer.percent=1.0来尽可能让数据处于内存中,设置mapreduce.reduce.merge.inmem.threshold=0避免从map task输出文件个数大于1000时写磁盘文件。2008年4月,hadoop的基准测试在900个节点上运行1TB排序测试集仅需209秒,成为当时世界最快,其中一项优化就是尽可能的使得reduce task的中间结果数据存储于内存中;
- 默认hadoop访问文件的IO缓存大小io.file.buffer.size=4K,这个建议增大到128K。
2)从map task端优化MapReduce job
| 属性 | 类型 | 默认值 | 描述 |
| mapreduce.task.io.sort.mb | int | 100 | 每个map task持有的一个环形内存缓冲区大小 |
| mapreduce.map.sort.spill.percent | float | 0.80 | 当每个map task持有的一个环形内存缓冲区使用比例大于此值就spill写linux磁盘文件 |
| mapreduce.task.io.sort.factor | int | 10 | 10个spill的linux本地文件会进行一次合并 |
| mapreduce.map.combine.minspills | int | 3 | map task最后的输出文件个数必须小于此值,不然就触发合并 |
| mapreduce.map.output.compress | boolean | false | map task的输出的压缩是否开启 |
| mapreduce.map.output.compress.codec | Classname | org.apache.hadoop.io.compress.DefaultCodec | map task输出的压缩格式设置 |
| mapreduce.shuffle.max.threads | int | 0 | 每一个nodemanager上开启多少个线程来将map task输出数据传输给reduce task,0表示处理器数量的2倍,此属性继承自netty设置 |
3)从reduce task端优化MapReduce job
| 属性 | 类型 | 默认值 | 描述 |
| mapreduce.reduce.shuffle.parallelcopies | int | 5 | reduce task的COPY阶段,用来复制map task数据的线程数 |
| mapreduce.reduce.shuffle.maxfetchfailures | int | 10 | reduce task尝试从map task获取数据失败后的最大尝试次数,尝试次数大于此值后直接跑错 |
| mapreduce.task.io.sort.factor | int | 10 | 10个spill的linux本地文件会进行一次合并 |
| mapreduce.reduce.shuffle.input.buffer.percent | float | 0.70 | 拷贝到reduce task的数据存储到内存缓冲区,该内存缓冲区大小为reduce task的JVM * 0.70 |
| mapreduce.reduce.shuffle.merge.percent | float | 0.66 | 拷贝到reduce task的数据存储到内存缓冲区,该缓冲区数据达到一定比例就写文件到linux磁盘,该比例对应内存阈值为为reduce task的JVM * 0.70 *0.66 |
12.【MapReduce】MapReduce job的推测任务(speculative execution)?
答:(1)MapReduce job的MapReduce tasks有快有慢,针对那些假死或挂起或者耗时的task,会启动一个和该TASK一样的另外一个推测任务MapReduce task并行执行,当推测TASK在原TASK执行完之前完成那么原TASK被中止,当推测TASK在原TASK执行完之后完成那么推测TASK被中止;推测TASK只会在MapReduce job的所有MapReduce tasks都启动后才会开始被启动,这种任务就是推测任务(speculative execution);
(2)推测任务的相关设置属性如下:
| 属性 | 类型 | 默认值 | 描述 |
| mapreduce.map.speculative | boolean | true | 是否开启针对map task的推测任务 |
| mapreduce.reduce.speculative | boolean | true | 是否开启针对reduce task的推测任务 |
| yarn.app.mapreduce.am.job.speculator.class | Class | org.apache.hadoop.mapreduce.v2.app.speculate.DefaultSpeculator | 推测任务执行策略 |
| yarn.app.mapreduce.am.job.task.estimator.class | Class | org.apache.hadoop.mapreduce.v2.app.speculate.LegacyTaskRuntimeEstimator | 推测任务使用的评估策略 |
(3)建议关闭推测任务(speculative execution),理由如下:
- 推测任务(speculative execution)好处是减少MapReduce job执行时间,但是会带来性能开销,特别是在一个本来就非常忙的集群上;
- 对于reduce task推测任务(speculative execution)会让更多的reduce task去获取map task的输出,增加网络开销;
- 对于non-idempotent task更应该关闭推测任务(speculative execution)
13.【MapReduce】MapReduce job的FileInputFormat默认的InputPathFilter排除了哪些文件?如何设置自己的InputPathFilter过滤文件?如何设置级联读取所给目录子目录下文件数据?
答:FileInputFormat默认自己有InputPathFilter,这个InputPathFilter会将所给输入数据目录下所有以(点号.和下划线_打头的隐藏文件进行排除,放置参与数据处理计算);
client通过setInputPathFilter()添加自己的InputPathFilter,这个InputPathFilter不会覆盖默认的InputPathFilter,只会基于其上做叠加;
默认hadoop MapReduce job的FileInputFormat不会级联读取所给目录下子目录中的数据文件,相反会把子目录当作数据文件进行读取,此时会直接向外抛出error;如果想让其级联读取目录下子目录的数据文件需要设置mapreduce.input.fileinputformat.input.dir.recursive=true
14.【MapReduce】MapReduce的一些其他有用特性
答:(1)计数器:计数器可以辅助MapReduce job的相关统计信息;计数器可以用来诊断MapReduce job出现的问题;计数器相对于通过日志去排查MapReduce job更容易。
计数器分类:
- hadoop自带的计数器
| 计数器类型 | 计数器实现类 |
| MapReduce task counters | org.apache.hadoop.mapreduce.TaskCounter |
| Filesystem counters | org.apache.hadoop.mapreduce.FileSystemCounter |
| FileInputFormat counters | org.apache.hadoop.mapreduce.lib.input.FileInputFormatCounter |
| FileOutputFormat counters | org.apache.hadoop.mapreduce.lib.output.FileOutputFormatCounter |
| Job counters | org.apache.hadoop.mapreduce.JobCounter |
- 用户定义的java计数器
- 用户定义的非java计数器(Streaming计数器)
(2)排序sort
- 部分排序:MapReduce Job使用输入数据的key的数据进行排序,排序的规则是:1)首先采用mapreduce.job.output.key.comparator.class设置的类;2)如果mapreduce.job.output.key.comparator.class没设置,则输入数据的key类型必须是WritableComparable的子类,找该子类对应的comparator;3)如果找不到comparator,就使用RawComparator
- 全排序:第一种实现是设置只产生一个结果文件,第二种是分别产生多个分区parrtion排序文件然后串联起来
- 分组排序(次要排序或者第二排序):默认MapReduce Job已经按照key排序,如果需要多个条件排序,一般流程如下:1)定义包括自然键和自然值的组合键2)根据组合键对记录进行排序,即同时用自然键和自然值进行排序3)针对组合键进行分区和分组时均只考虑自然键
(3)链接join
- map task端的连接join:两个大规模输入数据集之间的map端连接会在数据达到map函数之前就执行链接join操作,此时要求各个map的输入数据必须已经按照相同的key先分区并且以该key特定方式排序。适用于多个Mapreduce job的输出进行连接join,只要这些Mapreduce job的reduce数量相同和key相同并且输出文件是不可切分的。
- reduce task端的链接join:reduce端join比map端join常用,但是毕竟reduce端的join数据都要经过shuffle,效率比map端join低。
(4)分布式缓存(类似于spark的广播变量)
- Mapreduce job配置Configuration共享:通过Configuration以key-value形式共享数据
- 分布式缓存:使用辅助类GenericOptionsParser通过-files将文件在HDFS进行共享

五.hadoop cluster相关问题
1.【hadoop cluster】hadoop的版本有哪些?各自优缺点?
答:
| 版本 | 安装包 | 优点 | 缺点 |
| Apache hadoop | Tar | 扩展性好,更灵活,开源免费 | 工作量大, 没有完整的管理和监控功能 |
| Apache Bigtop | RPM | Debian提供各种子项目的整合和测试, 比如整合hive |
扩展不灵活受制于人 |
| Cloudera hadoop | Tar、RPM | 具备安装、管理和监控功能, 有开源版本和商用版本, 目前开源版本有使用限制 |
扩展不灵活受制于人, 需要root或者sudo权限, 一家独大时商业纠纷问题 |
| Hortonworks hadoop | Tar、RPM | 具备安装、管理和监控功能, 有开源版本和商用版本, 目前开源版本有使用限制 |
扩展不灵活受制于人, 需要root或者sudo权限, 一家独大时商业纠纷问题 |
| Ambari hadoop | Tar、RPM | 具备安装、管理和监控功能, 开源免费 |
扩展不灵活受制于人, 需要root或者sudo权限 |
2.【hadoop cluster】企业hadoop cluster集群配置要求?企业如何去评估集群硬件需求?
答:(1)hadoop被设计用来在商业硬件上运行,企业可以选择普通硬件供应商生产的标准化的、广泛有效的硬件来搭建集群,这里的商业硬件注意两个原则:一是商业硬件不等同于低端硬件,低端硬件故障概率高;二是商业硬件也不推荐使用大型的数据库级别的机器,因为这类机器性价比太低。
对于商业硬件的配置推荐如下(基于2014年的硬件市场和配置推荐):
- 处理器:2 * 6/8核CPU,主频3GHZ
- 内存 :64-512G
- 磁盘 :12-24 * 1-4TB SATA磁盘,不建议RAID(只会降低速度,备份对hadoop毫无意义)
- 网络 :具有链路聚合的千兆以太网
推荐的hadoop cluster网络拓扑结构如下:
- 使用之前的HDFS网络距离算法计算最优距离;
- 默认hadoop是没有机架感知能力,需要设置net.topology.node.switch.mapping.impl和net.topology.script.file.name来启用机架感知

(2)企业如何估算hadoop cluster硬件服务器需求量:

3.【hadoop cluster】hadoop cluster安装步骤和建议?
答:详见hadoop2.7.1安装准备 和 1.x和2.x都支持的集群安装
(1)安装JDK(详查官网每个版本对于JDK的要求)
(2)创建用于管理的linux用户(建议分别创建linux用户hdfs mapred yarn)
(3)安装hadoop(下载tar.gz文件直接解压,安装目录建议为/usr/local,其次可以安装在/opt)
(4)配置SSH(方便从一个节点SSH登录其他节点从而实现集群启动和停止)
(5)修改hadoop配置文件

![]()
(6)格式化HDFS文件系统
(7)启动和关闭hadoop(可以设置hadoop-env.sh中HADOOP_SLAVES来改变默认slaves文件位置)
(8)在HDFS上创建用户目录
#在HDFS上创建文件目录/user/username并授权给username:username hadoop fs -mkdir /user/username hadoop fs -chown username:username /user/username #设置HDFS文件目录/user/username的最大使用磁盘空间 hdfs dfsadmin -setSpaceQuota 1t /user/username
4.【hadoop cluster】hadoop cluster有哪些配置文件?如何使用工具同步配置?hadoop的环境初始化配置?其它配置信息?
答:(1)hadoop的配置文件列表如下:
![]()
(2)在CDH和Ambari中,默认使用dsh和pdsh来管理进群配置;集群节点个性化或者差异化配置工具参考Chef, Puppet, CFEngine, and Bcfg2
(3)hadoop的环境变量初始化脚本主要为hadoop-env.sh和yarn-env.sh,一些特别的设置建议如下:
- java:请设置JAVA_HOME,因为在hadoop-env.sh和yarn-env.sh都需要此值,也可设置在hadoop-env.sh和yarn-env.sh里面;
- 堆内存:默认hadoop-env.sh里HADOOP_HEAPSIZE=1G来设置后台进程namenode datanode journalnode resourcemanager nodemanager进程各自内存,也可单独设置,比如设置yarn-env.sh里的YARN_RESOURCEMANAGER_HEAPSIZE来单独设置resourcemanager内存,其它以此类推;namenode内存计算公式:datanode节点个数*单datanode上最大磁盘空间/(block大小*副本replication数),比如在一个200个datanode集群上,单datanode磁盘空间为24TB,block=128MB上需要配置的namenode堆内存为200 ×24*1024*1024⁄ (128 MB × 3)=12.5G
- 系统日志:默认日志目录为$HADOOP_HOME/logs,该日志目录不存在的话hadoop在启动时会主动创建,如果创建linux文件目录权限不够直接跑错;$HADOOP_HOME/logs/*.log的日志文件默认永久保留不会自动删除清理,$HADOOP_HOME/logs/*.out的日志文件只保留最近的5个会自动删除清理过期日志文件;默认在hadoop-env.sh里设置了export HADOOP_IDENT_STRING=$USER,使得日志文件名字里包含了该节点启动的用户的名字,可以修改HADOOP_IDENT_STRING来做个性化设置。
- ssh:可以在hadoop-env.sh里设置HADOOP_SSH_OPTS将ssh信息传入hadoop
(4)后台进程相关重要设置

fs.defaultFS hdfs://namenode/
dfs.namenode.name.dir /disk1/hdfs/name,/remote/hdfs/name dfs.datanode.data.dir /disk1/hdfs/data,/disk2/hdfs/data dfs.namenode.checkpoint.dir /disk1/hdfs/namesecondary,/disk2/hdfs/namesecondary
yarn.resourcemanager.hostname resourcemanager yarn.nodemanager.local-dirs /disk1/nm-local-dir,/disk2/nm-local-dir yarn.nodemanager.aux-services mapreduce.shuffle yarn.nodemanager.resource.memory-mb 16384 yarn.nodemanager.resource.cpu-vcores 16
在mapreduce1中,map个数和reduce的个数是固定的,默认2个map2个reduce,所以计算tasktracker节点上内存为:1G(datanode内存)+1G(tasktracker内存)+2(map个数)*200MB(map task JVM)+2(reduce个数)*200MB(reduce task JVM)
在mapreduce2也即YARN中,map和reduce个数不再固定,只默认设置了map和reduce能申请的总的资源(8G内存,8CPU CORE),所以一般在nodemanager节点上,内存开销为:1G(datanode内存)+1G(nodemanager内存)+x(map个数)*1Gmap task JVM)+y(reduce个数)*1G(reduce task JVM),但总量x(map个数)*1Gmap task JVM)+y(reduce个数)*1G(reduce task JVM)不会超过默认的8G;YARN支持JVM虚拟内存设置,设置的虚拟内存不超过2.1倍JVM内存,默认yarn.nodemanager.vmem-pmem-ratio=2.1;YARN通过yarn.nodemanager.resource.cpuvcores、mapreduce.map.cpu.vcores、mapreduce.reduce.cpu.vcores来控制对于CPU的使用;可以设置yarn.nodemanager.containerexecutor.class和yarn.nodemanager.linux-container-executor来让YARN启用linux的cgroups资源隔离。

hadoop默认使用了一批端口号,这里详见官网。
(5)其他设置
通过dfs.hosts、dfs.hosts.exclude、yarn.resourcemanager.nodes.include-path和yarn.resourcemanager.nodes.exclude-path来上线和下线节点
默认hadoop访问文件的IO缓存大小io.file.buffer.size=4K,这个建议增大到128K
blocksize=128MB,不建议修改,很多地方依赖次配置
设置dfs.datanode.du.reserved预留磁盘空间供非HDFS程序或进程使用
设置fs.trash.interval启用回收站以免HDFS文件误删除后可以恢复
YARN调度器在Apache hadoop中默认为容量调度,而在CDH默认为公平调度,对于Apache hadoop建议优化为公平调度
默认reduce task在5%的map task完成后即开始启动,对于数据量大的任务建议设置mapreduce.job.reduce.slowstart.completedmaps进行优化
建议如果client和数据block在同一节点,建议开启short-circuit,通过设置dfs.client.read.shortcircuit=true和dfs.domain.socket.path开启
5.【hadoop cluster】hadoop cluster如何开启安全控制?
答:2009年,雅虎把Kerberos组件运用到了Hadoop之中,在RPC连接等多个组件上进行认证。时至今日,Kerberos依然是hadoop使用比较广泛的安全机制之一。

kerberos认证的过程:
- 认证:client向authentication服务器发送一条报文,或获取一个含时间戳的票据(Ticket-Granting Ticket ,TGT,默认有效期10小时)
- 授权:client使用TGT向ticket granting服务器请求一个服务票据
- 服务请求:client向最终的服务提供服务器(HDFS等)初十服务票据,以证实自己的合法性,然后最终的服务提供服务器(HDFS等)想client提供服务
hadoop中开启kerberos认证:
- hadoop.security.authentication=kerberos,默认值为simple,simple表示hadoop只通过linux组和用户进行权限判断,kerberos表示启用kerberos权限控制;
- hadoop.security.authorization=true来启用服务级别的授权,通过hadoop-policy.xml设置的linux组和用户来进行ACL的控制
hadoop的委托令牌:
- hadoop使用委托令牌来支持后续认证访问,避免了多次请求KDC(kerbers key distribution center)
- HDFS的委托令牌认证是通过设置dfs.block.access.token.enable=true来开启;
- mapreduce的委托令牌认证因为其提交的mapreduce job的jar和配置都存储在HDFS上进行共享,所以也是设置dfs.block.access.token.enable=true来开启;
其它的安全加强机制:
- 设置yarn.nodemanager.containerexecutor.class=org.apache.hadoop.yarn.server.nodemanager.LinuxContainerExecutor和yarn.nodemanager.linux-container-executor来启用轻量级目录访问(Lightweight Directory Access Protocol,LDAP)和基于linux cgroups的资源隔离;
- 任务有提交作业的用户启动时,建议把所有用户均可读的文件放到共享缓存中,把私有文件放在私有缓存中;
- 设置mapreduce.cluster.acls.enabled=true,mapreduce.job.acl-view-job=逗号分隔用户名, mapreduce.job.acl-modify-job=逗号分隔用户名来控制用户只能查看和修改自己的作业;
- shuffle默认阻止恶意用户请求获取其他用户的map输出;
- 为了防止恶意的辅助namenode datanode resourcemanager nodemanager加入集群跑环集群数据,建议设置master节点对视图与之连接的守护进程进行认证。比如一个datanode要加入集群,那么步骤是:1)通过ktutil生成keytab;2)设置dfs.datanode.keytab.file指向生成的keytab,设置dfs.datanode.kerberos.principal=usernname来指定使用的datanode账户;3)最后datanode与namenode交互的linux账户必须已经在hadoop-policy.xml中已经设置;
- datanode最好运行在特定端口(端口号小于24),使客户端确信它是安全的;
- mapreduce task只与其对应的mapreduce application master通信;
- 所有的网络数据传输采用加密,针对RPC设置hadoop.rpc.protection,针对HDFS设置dfs.encrypt.data.transfer,针对mapreduce shuffle设置mapreduce.shuffle.ssl.enabled,针对WEB UI接口设置hadokop.ssl.enabled
6.【hadoop cluster】hadoop cluster提供的基准测试工具有哪些?
答:啊红斗篷自带若干基准测试工具,这些工具放置在hadoop-*-test.jar的文件中,安装开销小,运行方便。基准测试工具很多无需传递额外参数,基准测试工具有利于快速检查搭建的hadoop cluster的性能状况,以供下一步的性能调优或者集群扩容甚至问题发现。
| 基准测试工具 | 用途 | 特点 |
| TeraSort | 测试数据排序能力 | 1TB排序通常用于衡量分布式数据处 理框架的数据处理能力。Terasort是 Hadoop中的的一个排序作业,在2008年, Hadoop在1TB排序基准评估中赢得 第一名,耗时209秒。 |
| TestDFSIO | 测试HDFS的I/0性能 | 本质为MapReduce |
| MRBench | 测试小型作业是否快速响应 | 多次运行一个小型作业 |
| NNBench | 测试namenode的加载过程 | |
| Gridmix | 测试集群负载情况 | 是一个基准测试程序集合, 通过模拟真实场景数据来 逼真的为一个集群负载建模。 |
| SWIM (Statistical Workload Injector for MapReduce) |
测试mapreduce负载情况 | 是一个针对mapreduce 负载的测试程序 |
| TPCx-HS | 基于TeraSort和事务处理TPPC (Transaction Processing Performance Council) |