CRNN序列图像识别过程(一)
CRNN是一种卷积循环神经网络结构,用于解决基于图像的序列识别问题,特别是场景文字识别问题。
文章认为文字识别是对序列的预测方法,所以采用了对序列预测的RNN网络。通过CNN将图片的特征提取出来后采用RNN对序列进行预测,最后通过一个CTC的翻译层得到最终结果。 说白了就是CNN+RNN+CTC的结构。
CRNN 全称为 Convolutional Recurrent Neural Network,主要用于端到端地对不定长的文本序列进行识别,不用先对单个文字进行切割,而是将文本识别转化为时序依赖的序列学习问题,就是基于图像的序列识别。
流程图如下图所示:
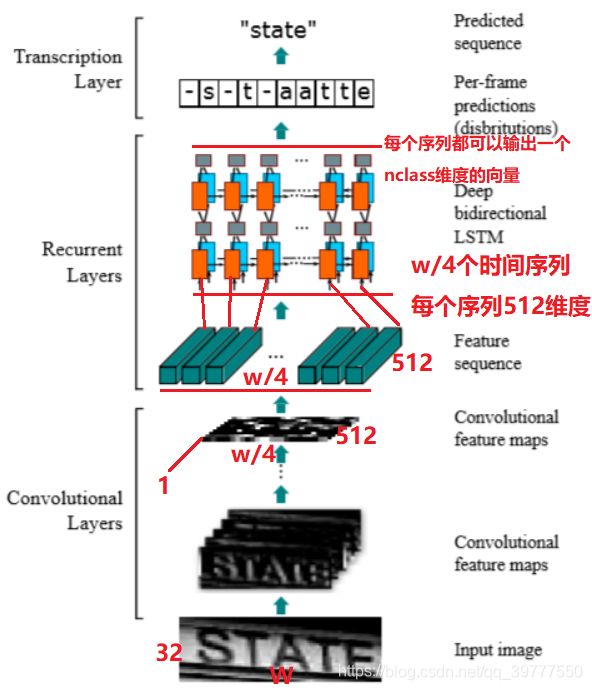
具体流程举例说明:
现在输入一个图像,为了将特征输入到Recurrent Layers,做如下处理:
首先会将图像缩放到 32×W×1 大小 (高度统一为32,宽度可以为任意W,通道数为1)
然后经过CNN后变为 1×(W/4)× 512 (高度变为1,宽度变为W/4,通道数变为512)
接着针对LSTM,设置 T=(W/4) , D=512 ,即可将特征输入LSTM (T为时间序数,D为一个时间序数输入的维度,即每个向量的长度)
LSTM有256个隐藏节点,经过LSTM后变为T个 长度为 nclass的向量,再经过softmax处理,得到的列向量(nclass长度)的每个元素代表对应字符的预测概率,最后再将这个T的预测结果去冗余合并成一个完整识别结果即可。
整体的网络结构图,如下图所示:

【Convolution中#maps:64,K:3x3,s:1,p:1表示该卷积层的输出通道数为64,卷积核的大小为3x3,步长为1x1,padding为1x1
Maxpooling中Window:2x2,s:2表示池化窗口大小为2x2,步长为2x2】
图片高度初始值为:32
32–MaxPooling s:2–>16–MaxPooling s:2–>8–MaxPooling s:2–>4–MaxPooling s:2–>2–>Conv p:0–>1
最终高度变为1
具体代码流程:
CRNN(
(cnn): Sequential(
(conv0): Conv2d(1, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(relu0): ReLU(inplace=True)
(pooling0): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(relu1): ReLU(inplace=True)
(pooling1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv2): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(batchnorm2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2): ReLU(inplace=True)
(conv3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(relu3): ReLU(inplace=True)
(pooling2): MaxPool2d(kernel_size=(2, 2), stride=(2, 1), padding=(0, 1), dilation=1, ceil_mode=False)
(conv4): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(batchnorm4): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu4): ReLU(inplace=True)
(conv5): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(relu5): ReLU(inplace=True)
(pooling3): MaxPool2d(kernel_size=(2, 2), stride=(2, 1), padding=(0, 1), dilation=1, ceil_mode=False)
(conv6): Conv2d(512, 512, kernel_size=(2, 2), stride=(1, 1))
(batchnorm6): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu6): ReLU(inplace=True)
)
(rnn): Sequential(
(0): BidirectionalLSTM(
(rnn): LSTM(512, 256, bidirectional=True)
(embedding): Linear(in_features=512, out_features=256, bias=True)
)
(1): BidirectionalLSTM(
(rnn): LSTM(256, 256, bidirectional=True)
(embedding): Linear(in_features=512, out_features=37, bias=True)
)
)
)
这里有一个很精彩的改动,一共有四个最大池化层,但是最后两个池化层的窗口尺寸由 2x2 改为 1x2,也就是图片的高度减半了四次(除以2^4),而宽度则只减半了两次(除以 2^2),这是因为文本图像多数都是高较小而宽较长,所以其feature map也是这种高小宽长的矩形形状,如果使用1×2的池化窗口可以尽量保证不丢失在宽度方向的信息,更适合英文字母识别(比如区分i和l)。
CRNN 还引入了BatchNormalization模块,加速模型收敛,缩短训练过程。
输入图像为灰度图像(单通道);高度为32,这是固定的,图片通过 CNN 后,高度就变为1,这点很重要;宽度为160,宽度也可以为其他的值,但需要统一,所以输入CNN的数据尺寸为 (channel, height, width)=(1, 32, 160)。
CNN的输出尺寸为 (512, 1, 40)。即 CNN 最后得到512个特征图,每个特征图的高度为1,宽度为40。
不能直接把 CNN 得到的特征图送入 RNN 进行训练的,需要进行一些调整,根据特征图提取 RNN 需要的特征向量序列。
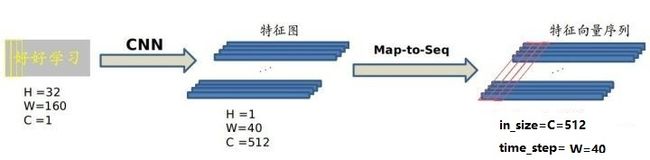
现在需要从 CNN 模型产生的特征图中提取特征向量序列,每一个特征向量(如上图中的一个红色框)在特征图上按列从左到右生成,每一列包含512维特征,这意味着第 i 个特征向量是所有的特征图第 i 列像素的连接,这些特征向量就构成一个序列。
由于卷积层,最大池化层和激活函数在局部区域上执行,因此它们是平移不变的。因此,特征图的每列(即一个特征向量)对应于原始图像的一个矩形区域(称为感受野),并且这些矩形区域与特征图上从左到右的相应列具有相同的顺序。特征序列中的每个向量关联一个感受野。

这些特征向量序列就作为循环层的输入,每个特征向量作为 RNN 在一个时间步(time step)的输入。
【如果对LSTM网络不熟悉,可以参考:https://blog.csdn.net/qq_39777550/article/details/106659150】
其实对于LSTM,看懂这一张图就好了!

因为 RNN 有梯度消失的问题,且不能对历史信息进行有效的筛选遗忘,所以 CRNN 中使用的是 LSTM,LSTM 的特殊设计允许它对历史信息有效的筛选遗忘,且解决了梯度消失的问题。
LSTM 是单向的,它只使用过去的信息。然而,在基于图像的序列中,两个方向的上下文是相互有用且互补的。将两个LSTM,一个向前和一个向后组合到一个双向LSTM中。此外,可以堆叠多层双向LSTM,深层结构允许比浅层抽象更高层次的抽象。
通过上面一步,我们得到了40个特征向量,每个特征向量长度为512,在 LSTM 中一个时间步就传入一个特征向量进行分类,这里一共有40个时间步。
一个特征向量就相当于原图中的一个小矩形区域,RNN 的目标就是预测这个矩形区域为哪个字符,即根据输入的特征向量,进行预测,得到所有字符的softmax概率分布,这是一个长度为字符类别数的向量,作为CTC层的输入。

然后将这个后验概率矩阵传入转录层。
对于得到的后验概率矩阵,把每一列得到的数值进行softmax处理,得到概率,选取概率大的位置对应的字符。比如最终得到的结果为:wwo-rrrr-l-dd!
进行处理的方式,是相邻位置相同的字符合并为一个字符,把空字符-删除,得到的结果为:
world!