目标检测综述20年(1999~2019)
参考:《Object Detection in 20 Years: A Survey》
链接:https://arxiv.org/abs/1905.05055?context=cs
-
对错误检测的微调
模型的偏差:准确度
模型方差:拟合度
弱分类器偏差高,方差小
强分类器偏差低,方差大
Boosting:多个弱分类器串联,降低偏差
Bagging:多个强分类器并联,降低方差
- 可利用特征信息:
上下文信息(对象间信息、目标邻域信息、空间位置等信息、局部位置)、纹理特征、边缘特征
- 存在难点&挑战:
(1)观测:观测点和光线变化
(2)目标:尺度、姿态、形变 、遮挡、外观不一
(3)背景:杂乱、background clutter, occlusions, changes in appearance,
(5)图像质量:模糊、分辨率低、噪声
- 目标检测算法发展历程的两个图:

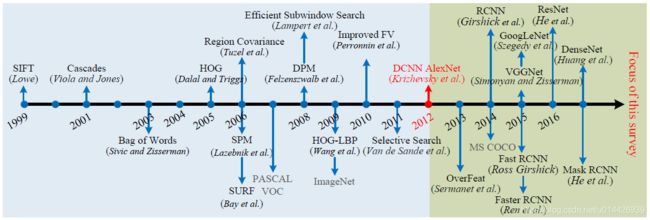
1.传统方法:
特点:(handcrafted features)
1.Viola Jones Detectors
论文:
Rapid object detection using a boosted cascade of simple features, 2001
Robust real-time face detection, 2004
人脸检测
Sliding windows
1).integral image
2).feature selection
3).detection cascades
2.HOG Detector
论文:
Histograms of oriented gradients for human detection,2005
行人检测
1)scale-invariant feature transform,尺度不变的特征变换
2)shape contexts ,形状上下文
3.Deformable Part-based Model (DPM)
论文:
Object detection with discriminatively trained part-based models,2010
VOC07,08,09,通用目标检测
1)as an extension of the HOG detector
2)目标部分模型
3)“hard negative mining”, “bounding box regression”, and “context priming”
4.An HOG-LBP Human Detector with Partial Occlusion Handling
论文:
An HOG-LBP Human Detector with Partial Occlusion Handling
2.基于卷积神经网络的两阶段检测
特点:神经网络,数据驱动的特征提取,GPU加速
1.R-CNN
论文:
Rich feature hierarchies for accurate object detection and semantic segmentation,2014
Region-based convolutional networks for accurate object detection and segmentation,2015
目标检测
1)selective search
2)卷积网络
3)线性SVM
4)检测-分类,固定尺寸输入分类网络
5)14s 一张图 with GPU
2.SPPnet
论文:
Spatial pyramid pooling in deep convolutional networks for visual recognition,2015
目标检测
1)一次计算特征图,避免重复计算卷积特征
2)生成固定长度特征向量
3)比R-CNN快20倍
4)仍然是多阶段
5)微调全连接层
3.fast r-cnn
论文:
Fast r-cnn,2015
目标检测
1)检测与回归在同一网络下进行
2)比R-CNN快200倍
3)集成R-CNN和SPPnet的优势
4)Proposal成为瓶颈
4.ZF-Net
论文:
Visualizing and understanding convolutional networks,2014
神经网络可视化
5.Faster r-cnn(https://github.com/dBeker/Faster-RCNN-TensorFlow-Python3.5)
论文:
Faster r-cnn: Towards real-time object detection with region proposal networks,2015
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks,PAMI,2017
目标检测
1)RPN,region proposal networks
2)proposal detection,feature extraction, bounding-box regression集成在统一的端到端学习框架
3)仍然存在计算冗余
6.FPN
论文:
Feature pyramid networks for object detection,2017
目标检测
1)基于Faster RCNN
2)横向连接,在各尺度里建立更高层次的语义特征
7.RFCN
论文:
R-fcn: Object detection via region-based fully convolutional networks,2016
8.Light head RCNN
论文:
Light-head r-cnn: In defense of two-stage object,2017
3.基于卷积神经网络的一阶段检测
特点:没有region proposal,但依然有anchor
1.You Only Look Once (YOLO)
论文:
You only look once: Unified, real-time object detection,2016
YOLO9000: better, faster, stronger,2017
Yolov3: An incremental improvement,2018
(45fps)
1)预先划定anchor,对每个anchor区域预测目标可能性
2)图片输入,全局预测,时间快
3)训练正负样本不平衡
4)由于全局特征预测,对负样本抑制较好
5)定位精度,小目标(后两个版本改进方向)
2.Single Shot MultiBox Detector (SSD)
论文:
Ssd: Single shot multibox detector,2016
fast version:59fps
1)multi-resolution detection 跨层连接
2)multi-reference detection 预先定义多种尺度和尺寸的boxes
3)提高对小目标检测的性能
4)在各个网络层进行多尺度检测
5)各层网络特征没有有效结合
论文:
Dssd: Deconvolutional single shot detector,2017
1)对多层网络特征利用Deconvolution进行特征融合
3.RetinaNet
论文:
Focal Loss for Dense Object Detection,2018
1)改进交叉熵损失函数:focal loss,解决样本不平衡问题
4.数据集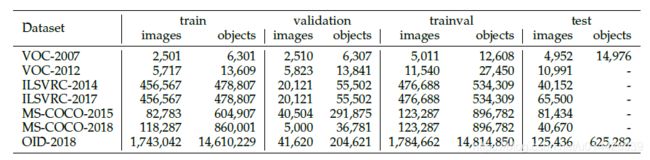
1.Pascal VOC,2005~2012
http://host.robots.ox.ac.uk/pascal/VOC/
图像分类,目标检测,语义分割,行为检测
2.ILSVRC 2010~2017
http://image-net.org/challenges/LSVRC/
ImageNet Large Scale Visual Recognition Challenge
3.MS-COCO
http://cocodataset.org/
Closer to those of the real world.
4.Open Images
https://storage.googleapis.com/openimages/web/index.html
At an unprecedented scale.
1.目标检测技术路线
1.组件,形状和边缘
1)距离变换
2)匹配
3)edgelet特征
缺点:更复杂的检测场景下效果不好
2.基于机器学习
1)外观的统计模型(1998):从数据中学习外观的整体描述,eg:特征脸
2)小波特征表征(1998-2005):图像像素转为小波系数,高效计算,eg:Haar wavelet
3)基于梯度表征(2005-2012)
3.基于卷积神经网络
回溯到1990s,LeCun
2.多尺度检测技术路线
(different sizes and different aspect ratios)
multiple historical periods:
1)“feature pyramids and sliding windows (before 2014)”, 缩放image
2)“detection with object proposals (2010-2015)”, proposals
3)“deep regression (2013-2016)”, yolo
4)“multi-reference detection (after 2015)”, 多anchor
5)“multi-resolution detection (after 2016)”, 多层连结
3.Bounding Box Regression技术路线
1.Without BB regression (~2008)
Build very dense pyramid and slide the detector densely on each location.
2.BB to BB (2008-2013)
Yields noticeable improvements of the detection under PASCAL criteria.
3.Features to BB (2013~)
BB no longer serves as an individual post-processing block but has been integrated with the detector and trained in an end-to-end fashion.
Directly based on CNN features.
4.上下文启动技术路线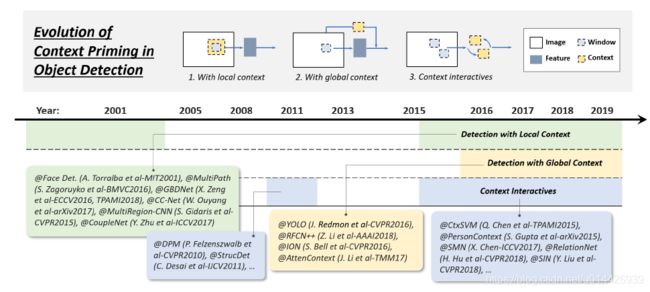
视觉目标存在于环境中,我们的大脑利用物体和环境之间的联系来促进视觉感知和认知。
1)detection with local context
加入背景信息,目标轮廓边界,提高检测精度。
基于深度学习的目标检测,增加感受野
2)detection with global context
利用场景关系作为额外信息源。First: 利用大图像,second :rnn
3)context interactives(上下文互动)
通过视觉元素传达信息
不同目标的关系,目标与场景的关系。
5. Non-Maximum Suppression技术路线
 后处理步骤:
后处理步骤:
1)Greedy selection
最高的分数,nms阈值一般0.5
2)BB aggregation
多个框通过一定原则聚合,如加权
3)Learning to NMS
对密集目标和部分遮挡的检测效果
6.难负样本挖掘技术发展(Hard Negative Mining)
对象检测器的训练本质上是不平衡的数据学习问题。
1)Bootstrap
逐步添加负样本,减少训练计算
2)HNM in deep learning based detectors
正负样本权重无法完全解决不平衡数据学习问题
3)New loss functions
Eg. Focal loss
检测加速方法
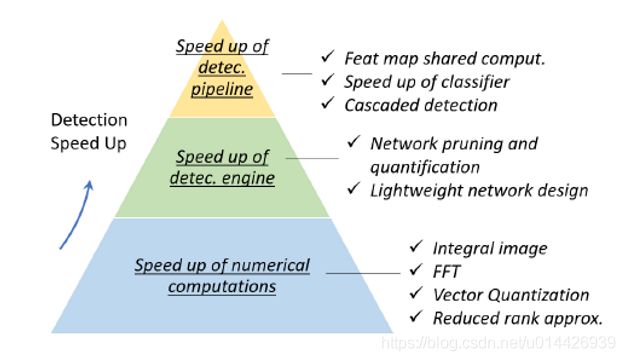
1.speed up of detection pipeline
2.speed up of detection engine
3.speed up of numerical computation
1)特征共享
设置cell size,分辨率限制
2)尺度计算
直接缩放特征(eg.积分图)
3)分类器加速
Prefer using linear classifiers than nonlinear.
4)串级检测
5)网络修剪和量化
6)轻量网络设计:更少通道、更多层数,factorizing convolutions,group convolution,depth-wise separable convolution,bottle-neck design,neural architecture search
卷积核分解,减少通道,1×1卷积核分离卷积,通道分组卷积,跨层连接(Bottle-neck Design)
Neural Architecture Search:自动设计网络结构,函数集拟合。
积分图加速、矢量化、降秩近似(eg.SVD)。
目标检测最新发展:
1.更好的引擎(网络结构)
2.更好的特征
a.不变性(尺度不变,光照不变尺度不变,光照不变,视角不变
b.等价性(相同的类别,特征等价、映射不变)
3.学习具有大型感受野的高分辨率特征
具有较大感知字段的网络能够捕获更大规模的上下文信息,而具有较小感知字段的网络可以更多地关注本地细节。
Eg.3×3跨步2跟5×5有相同的感受野。
Beyond sliding window
- 子区域搜索(G-CNN)
- 关键点定位(人脸关键点,姿态估计,Cornernet)
Improvements of Localization
- Bounding box refinement
- Designing new loss functions for accurate localization
Learning with Segmentation
分割提高检测性能,但会引起额外计算
旋转和尺度变化的鲁棒检测
数据旋转增广、对每个旋转训练检测器、rotation invariant loss functions、旋转配准、
尺度自适应训练:裁剪,rescale
尺度自适应检测:(carefully define the size of anchors:无法自适应尺寸)
从头训练
Pre-training:数据集的分布、领域等,不一定需要预训练。
Dense connection and batch normalization。
Weakly Supervised Object Detection (WSOD)
弱监督对象检测(WSOD)训练仅具有图像级注释而不是边界框的检测器来解决目标检测。
或以边界框注释来解决像素级注释的分割问题
主动学习(active learning)
半监督学习(semi-supervised)
迁移学习(transfer learning)
生成对抗网络(Generative Adversarial Network)
-
应用
1.行人检测
《HOG,ICF-》neural network
挑战:小目标、hard negatives(相似背景,may caused by 低像素)、密集(dense)、遮挡(occluded)、实时性
2.人脸检测
VJ检测器
挑战:类内差异、遮挡、多尺度、实时性
3.文本检测
挑战:不同字体语言、文本旋转、透视变换、密集、残缺模糊
4.交通信号及交通灯检测
挑战:光线变换、天气、实时性
5.遥感目标检测
挑战:数据量大、遮挡(云)、不同传感器捕获