机器学习笔记——logistic回归和最大熵
@[TOC]开始机器学习第二遍的整理和总结
这次笔记主要是用来总结logistic回归和最大熵
以后的总结都是对照机器学习, 机器学习实战和统计学习方法3本书来展开的, logistic算法在机器学习里面并没有单独的介绍, 在机器学习实战里面最了单独的介绍,但是在统计学习方法这里是和最大熵放一起的,因此我的总结也是把这两个部分放在一起进行。
logistic 算法介绍
logistic回归由Cox在1958年提出[1],它的名字虽然叫回归,但这是一种二分类算法,并且是一种线性模型。由于是线性模型,因此在预测时计算简单,在某些大规模分类问题,如广告点击率预估(CTR)上得到了成功的应用。如果你的数据规模巨大,而且要求预测速度非常快,则非线性核的SVM、神经网络等非线性模型已经无法使用,此时logistic回归是你为数不多的选择。
- 这是一个线性模型 ,这是需要确定的,后面会介绍这个为什么是线性的模型;
- 模型最后的输出结果是一个P(Y|X)值 即Y在X 的取值条件下,为正样本的概率,理解这个很重要;
- 优点计算代价不高,易于理解和实现(机器学习实战);
- 缺点容易欠拟合,分类精度不高(机器学习实战)但是这里不得提一句,大部分的算法都是在担心过拟合,唯独这个是担心欠拟合的;
- 主要针对二分类问题也可以进行多分类问题
算法推导
1:假设数据集:T = {(x1,y1),(x2,y2)…}
其中X是包含n 个特征的 数据样本,Y为最后的结果(1或者0)
假设他们是线性关系,那么就可以通过线性回归方程的形式来表达
y = w.T*x + b (w 为系数向量,T为矩阵置换)
这个方程在空间中(假设在2纬里面),相当于行程一条直线来怼样本进行区分
疑问—这时候有小伙伴可能会问,既然有回归直线了,那么为什么不知道用回归直线进行预测,然后再进行判别呢??
答案—这也是我刚开始看的时候所遇到的问题,这里需要理清楚的是,当我们用线性回归方程预测值的时候,它是基于一定概率的,这就是在统计学里面,在得到模型之后,要进行置信度检验并求出置信区间的原因。但是当X 取指很大的时候,我们可能没办法更加直观的知道X 的分类,因为需要作图然后和分类直线或者分类超平面进行对比才能知道这个问题在多个特征的的情况下更加严重。 所以我们把问题转移到求出它能成为正类或者负类的可能性大小。
2:sigmoid函数 在经过上面的想法之后,我们就找到了这个sigmoid 函数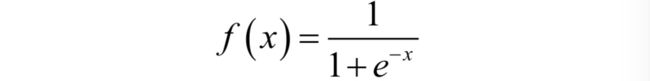
这个函数的特点是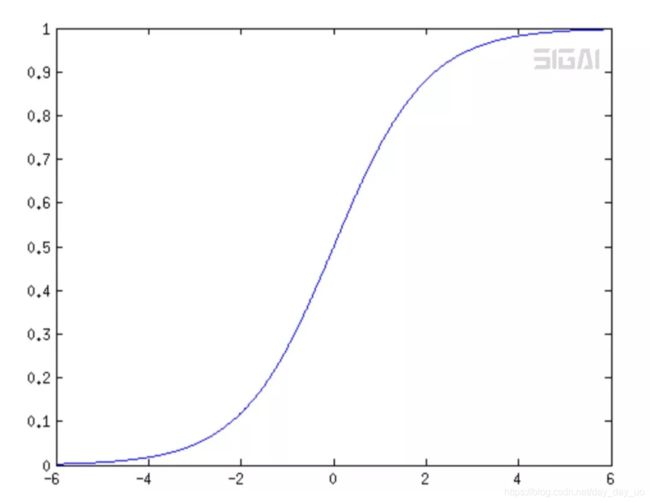
如图所示,图像在X=0的时候斜率很大,如果把横坐标的取指范围扩大,整体上看就会向一个跃进函数,从y=0 跳跃到y = 1 ,
提问这时候可能会童鞋问,为什么不知道用跃进函数, 即当X大于0的时候Y取指为1 小于0 的时候 取指为0 这样也可以啊 而且还简单。
答案 这个好是好 初中就学了,但是问题是 这个函数不连续, 而且对于所有的 正类 或者负类 没有概率上的表示
3:有了工具函数之后,我们就开始正式开始进行推导环节,即将原来的线性回归方程放到sigmoid 函数中
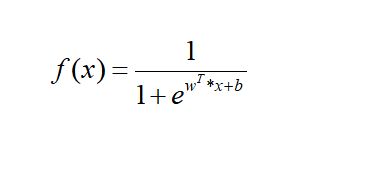
这个函数的意义是,当x 取一定的值的时候, y 为正样本的概率。
即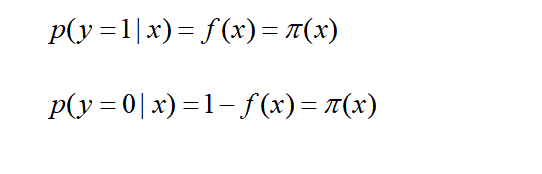
分别表示在X的取指下,正样本的概率,和负样本的概率。
并且每一个样本都可以通过这个形式进行表达
这里要始终记住我们的目标是什么 ,求出系数W 的值和常数b的值
我们在概率论里面都学过 在概率问题中的求参数,可以用极大似然法 考过研并且考过数三的同学一定知道。我们就要用这个方法进行求解。
先进行整理一下

然后极大似然求法的表达:

可能提问 为什么一定要求L的最大值呢??我在写这个之前确实也没有想过这个问题,现在也想到了。
答案 这个需要我们从极大似然的原理入手,
先看一下这个小题目:
有甲乙两个袋子,各装10个球,甲中有8个白2个黑,乙中有8个黑2个白,现在从中抽取4次,结果为3个黑 一个白,那么推测是从哪个袋子中抽取的-------《概率论与数理统计》
也可以自己算一下 ,答案是从乙中抽出的概率大于甲, 那么就认为是从乙中抽出来的。
这个就是极大似然估计法的直观想法,即选择一个参数p 的值使抽得的样本值出现的概率最大,并且用这个值作为未知参数P的估计值,这个就是他的基本思想。
在我们实际算法问题中,可以从两个方向来理解
第一个方向是:从建模的角度看, 求其最大值,是让我们手上的样本就好像上面抽出的4个球 , 甲乙两个袋子 是广义上的正负,这个角度看,即让求出的回归 可以尽可能正确的分对样本
那么从求得样本之后,用于测试集,就是尽可能的让测试集的样本分类正确。
4:优化算法 在机器学习实战中,对w 参数的求解用到了梯度上升法和 随机梯度上升法。
那什么是梯度上升法呢???
简单的理解,就是按照上升或者下降最快的方向,即导数方向,快速的达到最大值和最小值的位子。即每次移动一点 位置,然后在新的位置上面再找到最快的方向,然后再移动。
刚自己也一直在梯度的上升和下降为什么就能求出w的问题
答案 我们通过似然函数求得该函数对w 的求导之后, 其实这个函数就是关于w 的函数, 其求出L(w)的最小值,所以用梯度上升或者下架。
这里主要是搞清楚,是谁的函数。
至于梯度算法的详解, 可以知乎查看
https://www.zhihu.com/question/305638940/answer/606831354
再来了解随机梯度算法
根据机器学习实战中的代码,随机梯度算法 会对每次循环设置不同的步长的值,然后在内循环中,每个样本只用一次, 这样做的好吃是第一:可以加快计算的速度,因为整体样本被循环的次数减少,第二:可以减少异常样本对最后结果的影响,第三:可以加快参数的收敛。 (这里要插一句,一个算法的好坏 是看最后的结果是否收敛,如果不收敛就说明不稳定。)
具体代码看机器学习实战 下一次再增加最大熵的事情