XiyouLinuxgroup 2015 2017 2018面试题
三年考点总结
数组类问题
分析一下代码段,并解释输出结果和原因
#include这个题的关键是理解数据在数组中是如何存储的
。 0 1 2
0:1 2 3
1:4 5 6
3:7 8 9
第一个可以换成如此格式,*( *(nums + 1)-2)//由此可见指针和多维数组的关系不言而瑜
ps:(-1)[nums][5]) 和 nums[-1][5] 是一样的
-1[nums][5]和 -nums[1][5](这个-1没括号)
nums是二维数组,它的的单个元素是一维数组,所以它+1是+一个一维数组的字节。现在我们把这个二维数组抽象为二维指针,*(nums+1) 则是一级指针,它的单个元素为一个 int,所以它-2是 减2个int字节,所以最终就是+1个int也就是答案2。
对于这道题,还有一个问题是关于数组名具体代表的是什么的问题
int a[3][4]
- sizeof(a),a的类型: int [3][4],所以它返回整个数组的长度
- fun(int *a),作为函数形参,a的类型为int *
- &a,它的类型为int (*)[3][4],是一个数组指针
- 在表达式中,它的类型为int (const*)[4],即指向数组首元素a[0]的常量指针,a[0]它是一个int[4]。
- c语言中严格来说没有什么二维数组,它只有那种普通的一维数组,二维数组可以看做数组的数组,即对于a来说,它有3个元素,每个元素都是一个具有4个整形元素的一维数组(int[4])。我们可以把a[0]看做第一个元素的数组名,其他类推。
- 显然*a = *(a + 0) = (0 + a) = a[0] = 0[a],加法具有交换律嘛。那么,a = &a[0],这时就验证了我们上面的说法,此时(在表达式中),a是一个int()[4]
- a + 1 <==> &a[0] + 1,就是跨过第一行,即一个int[4]。a[0] + 1就是跨过第一行的第一个元素,即&a[0][1]。&a + 1自然就跨过整个数组喽。
然后我们在看一下指针和多维数组的关系
我的理解简单的说,就是一层数组等于一个 *
例如:*( *(a+x)+y) 所指向的值就是 a[x][y]
看下题
#include结果如下
a = 0x7fff19a496f0, a + 1 = 0x7fff19a496f8
a[0] = 0x7fff19a496f0, a[0] + 1 = 0x7fff19a496f4
*a = 0x7fff19a496f0, * a+1 = 0x7fff19a496f4
a[0][0] = 2
*a[0] = 2
**a = 2
a[2][1] = 3
*(*(a+2)+1) = 3
紧接着我们看一下sizeof于strlen的区别
sizeof是求数组或指针的最大容量
strlen计算的是一个对象或者类型的实际有效的内存长度。
ps:和上面做比较,strlen是c的库函数返回值是在运行时计算出来的,sizeof是一个关键字,结果类型为size_t
由此下面这个题基本就解决了
#includeps:%zu 是size_t输出类型,可以当它为整形变量
用%zu的原因:sizeof()不是函数,是一个关键字,不可扩展。sizeof()的结果类型为size_t,用int也行。
第一行的输出是24,计算的是a数组内存的长度。
第二行的第一个输出,a数组是一个int类型的数组,输出为4。
对str的内存计算
指针变量的大小在32位机和64位是不同
32位为4字节,64位为8字节。
再来解释下一道题
分析一下代码段,并解释输出结果和原因
#include第一个24,int形二维数组a,sizeof求容量,324 = 24
第二个4,是求单个a[1][1]的容量,所以是4,在sizeof括号中进行的语句,不会实现,所以后面的8就没有被赋新值,还是8。
附
unsigned int 0~4294967295
int 2147483648~2147483647
unsigned long 0~4294967295
long 2147483648~2147483647
long long的最大值:9223372036854775807
long long的最小值:-9223372036854775808
unsigned long long的最大值:1844674407370955161
__int64的最大值:9223372036854775807
__int64的最小值:-9223372036854775808
unsigned __int64的最大值:1844674407370955161
程序关于编译实现的问题
1.对于main()函数的理解
一个什么也不做的main函数如下:
void main() {} //早期C语言写法,如今使用下一种写法
我们可以让main函数返回一个状态值,表示最终执行的状态。
int main() { return 0; }
main函数可以有两个输入参数:
**argc:**指明参数的个数(即argv数组元素的个数)
**argv:**字符串数组表示的具体参数(一个包含多个字符串的数组)
我暂时只在文件操作用过这两个参数,我太菜了
2.下面是一个c语言程序从源代码到形成可执行文件的过程,请解释图中的ABCD分别表示什么,在每个阶段分别完成了什么工作?
暂时对这些不是非常理解,等我以后学习多了再来认真解释
此题答案详细解释

字节对齐问题
计算机是非常聪明的(不想看我的戳一下),他对数据存储有自己的方式,通过将内存“对齐”这一方式让变量的地址拥有一定的特性,使CPU对内存的访问效率得到了提高。以下题结构体为例
类型对齐方式(变量存放的起始地址相对于结构的起始地址的偏移量)
Char 偏移量必须为sizeof(char)即1的倍数
int 偏移量必须为sizeof(int)即4的倍数
float 偏移量必须为sizeof(float)即4的倍数
double 偏移量必须为sizeof(double)即8的倍数
Short 偏移量必须为sizeof(short)即2的倍数
#include第一个的图形解释
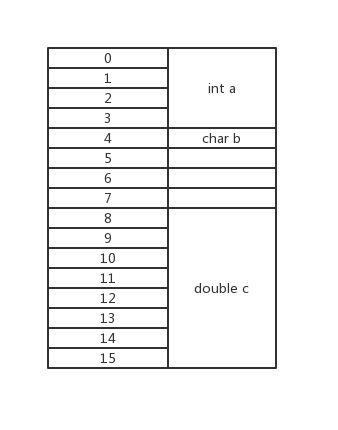
第二个的图形解释

所以为了节省内存,结构体中数据顺序也是十分重要的,另外,共用体的字节对齐就更简单了,我在此不做过多赘述。
既然都说到这里了,那就在来说一下大端和小端
现在的个人pc一般都是小端序,低地址存低字节,高地址存高字节,大端序则相反。
那什么又是高地址低地址呢?
我们设一个数组buf[4];
Big-Endian: 低地址存放高位,如下:
栈底 (高地址)
buf[3] (0x78) – 低位
buf[2] (0x56)
buf[1] (0x34)
buf[0] (0x12) – 高位
栈顶 (低地址)
Little-Endian: 低地址存放低位,如下:
栈底 (高地址)
buf[3] (0x12) – 高位
buf[2] (0x34)
buf[1] (0x56)
buf[0] (0x78) 低位
栈顶 (低地址)
这里还有一个思考问题是关于,如何编写一个程序来证明大小端序。
tip:可以用union
stdout, stdin, stderr问题
stdout, stdin, stderr的中文名字分别是标准输出,标准输入和标准错误。
在Linux下,当一个用户进程被创建的时候,系统会自动为该进程创建三个数据流,也就是题目中所提到的这三个。那么什么是数据流呢(stream)?我们知道,一个程序要运行,需要有输入、输出,如果出错,还要能表现出自身的错误。这是就要从某个地方读入数据、将数据输出到某个地方,这就够成了数据流。
例:fprintf(stdout,“hello world!\n”);
屏幕上将打印出"hello world!"
对于这一方面的学习,我推荐去这个网站,内容比较丰富各种函数快查
问题:下面程序的输出是什么?
int main(){
fprintf(stdout,"xiyou");
fprintf(stderr,"linux!");
return0;
}
解答:这段代码的输出是什么呢?在linux环境下和windows环境下有何异同?
在linux下的结果是
linux!xiyou
在windows下是
xiyoulinux!
这是为什么呢?在默认情况下,stdout是行缓冲的,他的输出会放在一个buffer里面,只有到换行的时候,才会输出到屏幕。而stderr是无缓冲的,会直接输出,举例来说就是printf(stdout, “xxxx”) 和 printf(stdout, “xxxx\n”),前者会憋住,直到遇到新行才会一起输出。而printf(stderr, “xxxxx”),不管有么有\n,都输出。
但是这种情况是出现在linux系统之下的,而对于windows系统来说,stderr和stdout是都没有行缓冲的
所以输出结果是xiyoulinux!
通过自己写的函数写出一个交换操作,可实现任何数据类型
方法1:宏函数
#define swap(a,b){a=a+b; b=a-b; a=a-b;}
方法2:通过void指针,增加一个参变量来判断他的数据类型实现
void swap(int f, void* x, void* y){
if(f == 1) {
int *p1;
int *p2;
int tmp;
p1 = (int *) x;
p2 = (int *) y;
temp = *p1;
*p1 = *p2;
*p2 = temp;
}
else if (f == 2) {
double *p1;
double *p2;
double tmp;
p1 = (double *) x;
p2 = (double *) y;
temp = *p1;
*p1 = *p2;
*p2 = temp;
}
else if(f == 3) {
char *p1;
char *p2;
char temp;
p1 = (char *) x;
p2 = (char *) y;
temp = *p1;
*p1 = *p2;
*p2 = temp;
}
else if(f == 4) {
short *p1;
short *p2;
short tmp;
p1 = (short *) x;
p2 = (short *) y;
temp = *p1;
*p1 = *p2;
*p2 = temp;
}
else if(f == 5) {
float *p1;
float *p2;
float tmp;
p1 = (float *) x;
p2 = (float *) y;
temp = *p1;
*p1 = *p2;
*p2 = temp;
}
//等等等
}
是不是感觉很难受
当然只要学了c++,可以直接用swap函数,STL大法好
const指针用法
const是一个C语言(ANSI C)的关键字,具有着举足轻重的地位。它限定一个变量不允许被改变,产生静态作用。使用const在一定程度上可以提高程序的安全性和可靠性。另外,在观看别人代码的时候,清晰理解const所起的作用,对理解对方的程序也有一定帮助。另外CONST在其它编程语言中也有出现,例如Pascal、C++、PHP5、B#.net、HC08 C、C#等
ps:定义某一个数值是多大时,个人感觉用const更好,感觉值不能改变,更安全,而且在算法比赛中,你如果要多次对某个数取余,不如定义一个固定的const形变量在去对他取余,程序运行速度会大大提高,玄学我不懂,但是的确是。
扯远了
对面试题来说
#include简单的来看const后面紧跟的是不能改变,记住这一点
所以第一个p1指向不可以改变
第二个*p2指的变量不能改变
宏定义的坑点
无参宏定义 //最常见用法
无参数宏定义的格式为:#define 标识符 替换列表
例:
#define PI 3.1416
由于宏定义仅是做简单的文本替换,故替换列表中如有表达式,必须把该表达式用括号括起来,否则可能会出现逻辑上的“错误”
比如面试题中的坑点
#define A 2+3
int z = A*A;
事实上z = 2+3*3+2
并不是你所需的结果,所以宏函数慎用,用就都加括号,括号大法好
带参数宏定义
带参数的宏定义格式为:#define 标识符(参数1,参数2,…,参数n) 替换列表
#define MAX(a,b) ((a)>(b)?(a) : (b))
括号必须加,不然肯定会出岔子的
宏展开
我这里的理解也非常浅薄,不是很懂
只能说
(1) 当宏中有#运算符时,参数不再被展开;
(2) 当宏中有##运算符时,则先展开函数,再展开里面的参数;##运算符用于把参数连接到一起。
最近抽时间在看看这方面的东西,算法比赛花费时间有点多
#define YEAR 2018
#define LEVELONE(x) "xiyoulinux"#x"\n"
#define LEVELTWO(x) LEVELONE(x)
#define MULTIPLY(x,y) x*y
int main(int argc, char *argv[])
{
int x = MULTIPLY(1+2,3);
printf("%d\n",x);
printf(LEVELONE(YEAR));
printf(LEVETWO(YEAR));
}
输出结果 : 7
xiyoulinuxYEAR
xiyoulinux2018
答案7同上
后面两个第一个因为在LEVELONE(x) “xiyoulinux”#x"\n"中含有#,所以不展开宏参数,直接输出的YEAR
但是第二个就是正常的宏替换,所以就输出 xiyoulinux2018
#include宏h(a) 是g(a),没有#,所以需要进行宏展开,两个##连接1和2,所以输出12
宏g(a) 有#,所以不展开直接输出f(1,2)
解释以下语句
#ifdef_linux_
int a = 1;
#elif _WIN32
int a = 2;
#elif _APPLE_
int a = 3;
#else
int a = 4;
#endif
我在网上查了这几个宏的意思,有一篇博客是这样说的
这几个宏是为了进行条件编译。一般情况下,源程序中所有的行都参加编译。但是有时希望对其中一部分内容只在满足一定条件才进行编译,也就是对一部分内容指定编译的条件,这就是“条件编译”。有时,希望当满足某条件时对一组语句进行编译,而当条件不满足时则编译另一组语句。
所以这三句在不同系统的电脑下运行的结果也是不同的
在linux下a=1
在win32下a=2
在Apple下a=3
在其他a=4
注意:宏定义不是语句,是预处理指令,故结尾不加分号。
补码反码原码问题
小组这几年的面试题都出到了原码反码补码,连2019西工大acm邀请赛的热身赛c题也考察到了这个点(现在网上可能题还没出来)。
我在这里贴一篇帖子点一哈
对于这一类的运算题,先来一道面试题
#includeC语言中有符号数和无符号数进行运算(包括逻辑运算和算术运算)默认会将有符号数看成无符号数进行运算,其中算术运算默认返回无符号数,逻辑运算返回0或1。
这道题,因为a是无符号的,无符号数a和有符号b进行加法运算,计算机将b看做无符号数,b的符号位也计数了,所以这两个数相加肯定大于6,所以答案也肯定大于6
我以后补充其他难的呜呜呜呜呜呜呜