统计学习方法——逻辑斯蒂回归与最大熵模型(一)
逻辑斯蒂回归与最大熵模型
- 逻辑斯蒂回归与最大熵模型
- 逻辑斯蒂回归模型
- 逻辑斯蒂分布
- 二项逻辑斯蒂回归模型
- 模型参数估计
- 多项逻辑斯蒂回归
- 最大熵模型
- 最大熵原理
- 最大熵模型的定义
- 最大熵模型的学习
- 极大似然估计
- 参考文献
逻辑斯蒂回归与最大熵模型
逻辑斯蒂回归是统计学中常用的经典分类方法;
最大熵是概率模型学习的一个准则,扩展到分类问题得到最大熵模型。
都属于对数线性模型
逻辑斯蒂回归模型
逻辑斯蒂分布
设 X X X为连续随机变量, X X X服从逻辑斯蒂分布是指 X X X具有如下的分布函数和密度函数:
F ( x ) = P ( X ≤ x ) = 1 1 + e − ( x − μ ) / γ F\left( x \right) = P\left( {X \le x} \right) = \frac{1}{{1 + {e^{ - \left( {x - \mu } \right)/\gamma }}}} F(x)=P(X≤x)=1+e−(x−μ)/γ1
f ( x ) = F ′ ( x ) = e − ( x − μ ) / γ γ ( 1 + e − ( x − μ ) / γ ) 2 f\left( x \right) = F'\left( x \right) = \frac{{{e^{ - \left( {x - \mu } \right)/\gamma }}}}{{\gamma {{\left( {1 + {e^{ - \left( {x - \mu } \right)/\gamma }}} \right)}^2}}} f(x)=F′(x)=γ(1+e−(x−μ)/γ)2e−(x−μ)/γ
其中 μ \mu μ为位置参数, γ > 0 \gamma>0 γ>0为形状参数。
其图像如下所示:
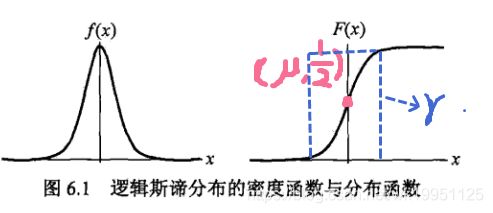
可以发现图形为 S S S形曲线,以点 ( μ , 1 2 ) \left( {\mu ,\frac{1}{2}} \right) (μ,21)中心对称, γ \gamma γ越小,曲线在中心附近增长越快。
二项逻辑斯蒂回归模型
- 逻辑斯蒂回归模型
二项式逻辑斯蒂回归模型的条件概率如下:
P ( Y = 1 ∣ x ) = exp ( w ⋅ x + b ) 1 + exp ( w ⋅ x + b ) P\left( {Y = 1\left| x \right.} \right) = \frac{{\exp \left( {w \cdot x + b} \right)}}{{1 + \exp \left( {w \cdot x + b} \right)}} P(Y=1∣x)=1+exp(w⋅x+b)exp(w⋅x+b)
P ( Y = 0 ∣ x ) = 1 1 + exp ( w ⋅ x + b ) P\left( {Y = 0\left| x \right.} \right) = \frac{1}{{1 + \exp \left( {w \cdot x + b} \right)}} P(Y=0∣x)=1+exp(w⋅x+b)1
这里 x x x为输入, Y ∈ { 0 , 1 } Y\in \left\{0,1\right\} Y∈{0,1}为输出, w w w和 b b b为参数, w ⋅ x w\cdot x w⋅x为内积。 - 特点
- 输出 Y = 1 Y=1 Y=1的对数几率是输入 x x x的线性函数
设事件发生的概率为 p p p,则发生几率为 p 1 − p \frac{p}{1-p} 1−pp,对数几率为:
l o g i t ( p ) = log p 1 − p = log P ( Y = 1 ∣ x ) 1 − P ( Y = 1 ∣ x ) = w ⋅ x + b logit\left( p \right) = \log \frac{p}{{1 - p}} = \log \frac{{P\left( {Y = 1\left| x \right.} \right)}}{{1 - P\left( {Y = 1\left| x \right.} \right)}} = w \cdot x + b logit(p)=log1−pp=log1−P(Y=1∣x)P(Y=1∣x)=w⋅x+b
- 输出 Y = 1 Y=1 Y=1的对数几率是输入 x x x的线性函数
模型参数估计
对于逻辑斯蒂回归模型学习时,可以使用最大似然估计算法估计模型参数。
训练集为 T = { ( x 1 , y 1 ) , ⋯ , ( x N , y N ) } T = \left\{ {\left( {{x_1},{y_1}} \right), \cdots ,\left( {{x_N},{y_N}} \right)} \right\} T={(x1,y1),⋯,(xN,yN)}, x i ∈ R n x_i\in R^n xi∈Rn, y i ∈ { 0 , 1 } y_i\in \left\{0,1\right\} yi∈{0,1}。
设 P ( Y = 1 ∣ x ) = π ( x ) P\left( {Y = 1\left| x \right.} \right) = \pi \left( x \right) P(Y=1∣x)=π(x), P ( Y = 0 ∣ x ) = 1 − π ( x ) P\left( {Y = 0\left| x \right.} \right) = 1-\pi \left( x \right) P(Y=0∣x)=1−π(x),则似然函数为:
∏ i = 1 N [ π ( x i ) ] y i [ 1 − π ( x i ) ] 1 − y i \prod\limits_{i = 1}^N {{{\left[ {\pi \left( {{x_i}} \right)} \right]}^{{y_i}}}{{\left[ {1 - \pi \left( {{x_i}} \right)} \right]}^{1 - {y_i}}}} i=1∏N[π(xi)]yi[1−π(xi)]1−yi
对应的对数似然函数为:
L ( w ) = ∑ i = 1 N [ y i log π ( x i ) + ( 1 − y i ) log ( 1 − π ( x i ) ) ] = ∑ i = 1 N [ y i ( w ⋅ x i ) − log ( 1 + exp ( w ⋅ x i ) ) ] L\left( w \right) = \sum\limits_{i = 1}^N {\left[ {{y_i}\log \pi \left( {{x_i}} \right) + \left( {1 - {y_i}} \right)\log \left( {1 - \pi \left( {{x_i}} \right)} \right)} \right]} = \sum\limits_{i = 1}^N {\left[ {{y_i}\left( {w \cdot {x_i}} \right) - \log \left( {1 + \exp \left( {w \cdot {x_i}} \right)} \right)} \right]} L(w)=i=1∑N[yilogπ(xi)+(1−yi)log(1−π(xi))]=i=1∑N[yi(w⋅xi)−log(1+exp(w⋅xi))]
求取 L ( w ) L\left( w \right) L(w)的极大值就可以得到 w w w的估计值。
多项逻辑斯蒂回归
假设离散型随机变量 Y Y Y的取值集合为 { 1 , 2 , ⋯ , K } \left\{ {1,2, \cdots ,K} \right\} {1,2,⋯,K},则多项逻辑斯蒂回归模型为:
P ( Y = k ∣ x ) = exp ( w k ⋅ x ) 1 + ∑ i = 1 K − 1 exp ( w i ⋅ x ) k = 1 , 2 , ⋯ , K − 1 P\left( {Y = k\left| x \right.} \right) = \frac{{\exp \left( {{w_k} \cdot x} \right)}}{{1 + \sum\limits_{i = 1}^{K - 1} {\exp \left( {{w_i} \cdot x} \right)} }}\quad k = 1,2, \cdots ,K - 1 P(Y=k∣x)=1+i=1∑K−1exp(wi⋅x)exp(wk⋅x)k=1,2,⋯,K−1
P ( Y = K ∣ x ) = 1 1 + ∑ i = 1 K − 1 exp ( w i ⋅ x ) P\left( {Y = K\left| x \right.} \right) = \frac{1}{{1 + \sum\limits_{i = 1}^{K - 1} {\exp \left( {{w_i} \cdot x} \right)} }} P(Y=K∣x)=1+i=1∑K−1exp(wi⋅x)1
二项逻辑斯蒂回归的参数估计可以类似推至多项逻辑斯蒂回归。
最大熵模型
最大熵原理
- 最大熵原理:学习概率模型时,在所有可能的概率模型(分布)中,熵最大的模型是最好的模型。
- 解释来说:选择的模型首先要满足已有事实(约束条件),剩下不确定的部分都是“等可能的”,最大熵原理则是通过熵的最大化来表示等可能性。
最大熵模型的定义
- 学习目标:用最大熵原理选择最好的分类模型。
- 最大熵模型
假设满足所有约束条件的模型集合为
C = { P ∈ P ∣ E p ( f i ) = E p ~ ( f i ) , i = 1 , 2 , ⋯ , n } \mathcal{C} = \left\{ {P \in \mathcal{P}\left| {{E_p}\left( {{f_i}} \right) = {E_{\tilde p}}\left( {{f_i}} \right),i = 1,2, \cdots ,n} \right.} \right\} C={P∈P∣Ep(fi)=Ep~(fi),i=1,2,⋯,n}
其中 E P ~ ( f ) = ∑ x , y P ~ ( x , y ) f ( x , y ) {E_{\tilde P}}\left( f \right) = \sum\limits_{x,y} {\tilde P\left( {x,y} \right)f\left( {x,y} \right)} EP~(f)=x,y∑P~(x,y)f(x,y), E P ( f ) = ∑ x , y P ~ ( x ) P ( y ∣ x ) f ( x , y ) {E_P}\left( f \right) = \sum\limits_{x,y} {\tilde P\left( x \right)P\left( {y\left| x \right.} \right)f\left( {x,y} \right)} EP(f)=x,y∑P~(x)P(y∣x)f(x,y), f ( x , y ) = { 1 x 与 y 满 足 某 一 事 实 0 不 满 足 f\left( {x,y} \right) = \left\{ \begin{array}{l} 1\quad \;x与y满足某一事实\\ 0\quad 不满足 \end{array} \right. f(x,y)={1x与y满足某一事实0不满足。定义在条件概率分布 P ( y ∣ x ) {P\left( {y\left| x \right.} \right)} P(y∣x)上的条件熵为:
H ( P ) = − ∑ x , y P ~ ( x ) P ( y ∣ x ) log P ( y ∣ x ) H\left( P \right) = - \sum\limits_{x,y} {\tilde P\left( x \right)P\left( {y\left| x \right.} \right)\log P\left( {y\left| x \right.} \right)} H(P)=−x,y∑P~(x)P(y∣x)logP(y∣x)
则模型集合 C \mathcal{C} C中条件熵 H ( P ) H\left( P \right) H(P)最大的模型称为最大熵模型。
最大熵模型的学习
- 最大熵学习可以形式化为约束最优化问题。
对于给定的训练集 T = { ( x 1 , y 1 ) , ⋯ , ( x N , y N ) } T = \left\{ {\left( {{x_1},{y_1}} \right), \cdots ,\left( {{x_N},{y_N}} \right)} \right\} T={(x1,y1),⋯,(xN,yN)}以及特征函数 f i ( x , y ) , i = 1 , 2 , ⋯ , n {f_i}\left( {x,y} \right),i = 1,2, \cdots ,n fi(x,y),i=1,2,⋯,n,最大熵模型的学习等价于约束最优化问题:
max P ∈ C H ( P ) = − ∑ x , y P ~ ( x ) P ( y ∣ x ) log P ( y ∣ x ) \mathop {\max }\limits_{P \in \mathcal{C}} H\left( P \right) = - \sum\limits_{x,y} {\tilde P\left( x \right)P\left( {y\left| x \right.} \right)\log P\left( {y\left| x \right.} \right)} P∈CmaxH(P)=−x,y∑P~(x)P(y∣x)logP(y∣x)
s . t . E P ( f i ) = E P ~ ( f i ) , i = 1 , 2 , ⋯ , n s.t.\quad {E_P}\left( {{f_i}} \right) = {E_{\tilde P}}\left( {{f_i}} \right),\;i = 1,2, \cdots ,n s.t.EP(fi)=EP~(fi),i=1,2,⋯,n
∑ y P ( y ∣ x ) = 1 \sum\limits_y {P\left( {y\left| x \right.} \right) = 1} y∑P(y∣x)=1
极大似然估计
- 最大熵模型的学习问题可以转化为求解对数似然函数极大化或对偶函数极大化的问题。
- 最大熵模型的一般形式
P w ( y ∣ x ) = 1 Z w ( x ) exp ( ∑ i = 1 n w i f i ( x , y ) ) {P_w}\left( {y\left| x \right.} \right) = \frac{1}{{{Z_w}\left( x \right)}}\exp \left( {\sum\limits_{i = 1}^n {{w_i}{f_i}\left( {x,y} \right)} } \right) Pw(y∣x)=Zw(x)1exp(i=1∑nwifi(x,y))
其中 Z w ( x ) = ∑ y exp ( ∑ i = 1 n w i f i ( x , y ) ) {Z_w}\left( x \right) = \sum\limits_y {\exp \left( {\sum\limits_{i = 1}^n {{w_i}{f_i}\left( {x,y} \right)} } \right)} Zw(x)=y∑exp(i=1∑nwifi(x,y))
x ∈ R n x\in R^n x∈Rn为输入, y ∈ { 1 , 2 , ⋯ , K } y\in \left\{ {1,2, \cdots ,K} \right\} y∈{1,2,⋯,K}为输出, w ∈ R n w\in R^n w∈Rn为权值向量, f i ( x , y ) , i = 1 , 2 , ⋯ , n {f_i}\left( {x,y} \right),i = 1,2, \cdots ,n fi(x,y),i=1,2,⋯,n为任意实值特征函数。
参考文献
《统计学习方法》