逻辑斯蒂回归2 -- 最大熵模型概念
声明:
1,本篇为个人对《2012.李航.统计学习方法.pdf》的学习总结,不得用作商用,欢迎转载,但请注明出处(即:本帖地址)。
2,由于本人在学习初始时有很多数学知识都已忘记,所以为了弄懂其中的内容查阅了很多资料,所以里面应该会有引用其他帖子的小部分内容,如果原作者看到可以私信我,我会将您的帖子的地址付到下面。
3,如果有内容错误或不准确欢迎大家指正。
4,如果能帮到你,那真是太好了。
虽然之前在决策树的ID3-ID4算法中已经使用过熵,不过那是使用熵来计算信息增益(比)。而这里既然是“最大熵模型”,那就先好好说明下熵吧。
何谓熵?
若只看名字….What the hell is it!! 所以我来解释下其含义吧。
其实熵是对不确定性的一种测量,但为什么熵测量了不确定性?这就要说是其由来了。
熵(entropy)最早起源于物理学,是用于度量一个热力学系统的无序程度,其表达式为:
△S(熵) = Q(能量) / T(温度)
它表示一个系统在不受外部干扰时,其内部最稳定的状态。
后来在翻译时,译者这么想:
首先,△S是求商获得的,那么译名中就有个“商”字吧,然后△S是能量于温度的商,都与温度,即火有关,那就加个“火”字旁吧,你看多形象~
是。对物理学的熵很形象,可对我们要掌握的信息论中的熵….我呵呵!
好了,译名的事清楚了,那为什么熵代表了“系统的无序程度”呢?
我们知道,任何粒子的常态都是随机运动,即“无序运动”。如果让粒子呈现“有序化”,则必须耗费能量。所以温度可以被看做是“有序化”的一种度量,那“熵(=能量/温度)”就可以看做是“无序化”的一种度量了(如果没有外部能量输入(分母越来越小),那封闭系统趋向越来越混乱(熵越来越大),打个比方的话:如果房间无人打扫,那只会越来越乱)。
于是,对物理学,“熵是对不确定性的一种测量”是不是也很形象。可对我们要掌握的信息论中的熵,我呵呵!!!!
算了,这个就这样了,我们也改变不了,总之记住“熵越大,则无序程度越大”后还是继续吧。
熵的定义
如果一个随机变量X的可能取值为X = {x1, x2,…, xk},其概率分布为P(X = xi) = pi(i = 1,2, ..., n),则随机变量X的熵定义为:
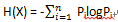
由定义可知,熵只依赖于X中类的分布,与X即样本总数无关,所以也可将H(X)记作H(P),即:
![]()
最大熵原理
最大熵原理就一句话:学习概率模型时,在所有可能的概率模型分布中,熵最大的模型就是最好的模型。
嗯,我不知道大家的情况,反正我在看到书上这句话时我100个不理解。
看了书上这句话之后的说明后。
我知道对于 ![]() 满足不等式 0 <= H(P) <= log|X| (|X|是X的取值个数)
满足不等式 0 <= H(P) <= log|X| (|X|是X的取值个数)
我也知道当且仅当X的分布是均匀分布时右边的等号成立,即:当X服从均匀分布时,熵最大。
可不是“熵越大,则无序程度越大”吗?
为什么“熵最大的模型就是最好的模型”啊!
你说最大熵原理就是通过熵的最大化来表示等可能性。
好吧,通过书上的说明我也明白了最大熵原理就是通过熵的最大化来表示等可能性。
可不是“熵越大,则无序程度越大”吗?
为什么“熵最大的模型或者说“等可能性”的模型就是最好的模型”啊!!!
(请原谅上面这些颇有个人感情色彩的话,实在是被书上N多必须查找其他资料才能搞懂的内容弄的难受,尤其我这种理解记忆的….)
最后查看了其他资料,看到了这么一段说明后终于豁然开朗:
为了准确的估计随机变量的状态,我们一般习惯性最大化熵,认为在所有可能的概率模型(分布)的集合中,熵最大的模型是最好的模型。换言之,在已知部分知识的前提下,关于未知分布最合理的推断就是符合已知知识最不确定或最随机的推断,其原则是承认已知事物(知识),且对未知事物不做任何假设,没有任何偏见。
例如,投掷一个骰子,如果问"每个面朝上的概率分别是多少",你会说是等概率,即各点出现的概率均为1/6。因为对这个"一无所知"的色子,什么都不确定,而假定它每一个朝上概率均等则是最合理的做法。从投资的角度来看,这是风险最小的做法,而从信息论的角度讲,就是保留了最大的不确定性,也就是说让熵达到最大。
到此,“熵最大的模型就是最好的模型”大家应该没问题了吧。
那么我们继续….
在上面的内容中的“投掷骰子”的例子说明了最大熵原理,下面我们再举一个更通用的例子来进一步理解最大熵。
例子:
假设随机变量X有5个取值{A, B, C,D, E},要估计各个值的概率P(A), P(B), P(C), P(D), P(E)
解:
这些概率值满足以下约束条件:
P(A)+ P(B) + P(C) + P(D) + P(E) = 1
在没有其他约束条件的情况下,根据“最大熵原理”,最合理的判断就是所有取值的概率相等,即:
P(A)= P(B) = P(C) = P(D) = P(E) = 1/5
有时,我们能从一些先验知识中得到一些约束条件,如:
P(A)+ P(B) = 3/10
P(A)+ P(B) + P(C) + P(D) + P(E) = 1
那根据“最大熵原理”,最合理的判断就是所有A和B取值的概率相等,C、D、E平分剩下的概率,即:
P(A)= P(B) = 3/20
P(C)= P(D) = P(E) = 7/30
以此类推。
最大熵模型的定义
最大熵的原理清楚了后我们来看最大熵模型的定义。
根据上面的例子我们可以引出最大熵模型的本质,即:它要解决的问题就是已知X时计算Y的概率,且尽可能的让Y的概率最大。(实践中,一定会给你一些条件X(如:P(A) + P(B) = 3/10),然后让你求事件Y(如:A、B、C、D、E)的概率)
即:在已知X的情况下,计算Y最大可能的概率。
咦?“在已知X的情况下,计算Y的概率”不就是“条件熵”定义么:条件熵就是在随机变量X已确定的条件下,随机变量Y的条件概率分布的熵对X的数学期望。
那最大熵是不是求最大条件熵呢?
条件熵的公式是:![]()
书上最大熵模型的公式是:![]()
哦,原来所谓的最大熵模型就是求最大条件熵。
于是定义是:
对于一模型:
在用如下特征函数:
![]()
来描述输入x和输出y之间的某一个事实时
该特征函数关于x和y的联合分布的期望值为:
![]()
该特征函数关于条件分布P(y|x)和边缘分布P(x) 的期望值为:
![]()
如果模型能够获取训练数据中的信息,则我们可以使用概率论的乘法定理:
P(y|x)= p(x) P(y|x)
来假设(这是约束条件):
![]()
在此时令其条件熵最大
![]()
这就是最大熵模型。
最大熵模型的一般形式
最大熵模型的一般形式是在进行“最大熵模型学习”时得到的,于是这里需要总结下最大熵模型的学习过程,而在总结学习过程之前先介绍下拉格朗日乘子法,因为最大熵模型学习时会用到这个。
拉格朗日乘子法:
基本的拉格朗日乘子法就是求函数f(x1, x2, …) 在g(x1, x2, …) = 0 的约束条件下的极值的方法(我们的目标是求最大熵,这就是求极值了)。
其主要思想是引入一个新的参数λ(即拉格朗日乘子),将约束条件函数与原函数联系到一起,使之能配成与变量数量相等的等式方程,从而求出原函数极值的各个变量的解。
假设待求极值的目标函数是f(x,y),约束条件是φ(x,y)=M
那么就假设 g(x,y)=M-φ(x,y) # 要让g(x1, x2, …) = 0
于是原函数f(x, y)就能变成如下函数:
f(x,y,λ) = f(x, y) + λg(x, y) #g(x, y) = 0,所以f(x,y, λ) = f(x, y) + 0 = f(x, y)
然后利用偏导数的方法列出方程:
∂f/∂x=0
∂f/∂y=0
∂f/∂λ=0
就可求出x, y, λ的值,最后将x, y, λ代入即可求解出极值了(如果不理解“为什么代入就可求解出极值”的话,请把导数的定义给弄懂)。
好了,有了上面的基础我们就能继续了(其实最大熵学习的步骤就是上面这些)。
最大熵模型的学习过程:
输入:
训练数据集:T ={(x1, y1), (x2, y2), …, (xn, yn)}
特征函数fi(x, y),i = 1, 2, …,n
输出:
最大熵模型
解:
首先根据题目可知:
1,所有情况的概率之和为1: ![]()
2,目的是求最大熵模型:![]()
3,既然是求最大熵模型,那必须满足最大熵模型的约束:![]()
然后,按照最优化问题的习惯,我们将最大值问题改写为等价的求最小值问题。
于是我们的目的变成了求(其他可知情况没有变化):
![]()
PS:-H(p) 最小,不就是H(P) 最大了吗~
接着,是重要的一步:引进拉格朗日乘子:λ0, λ1, …, λn,来定义拉格朗日函数L(p, λ):

求L(p, λ) 对p(y|x) 的偏导数:

令偏导数等于0,解得:
![]()
这里我们为了描述方便,将p(y|x)转换为:
![]()
根据之前的约束条件:
![]()
得:
![]()
所以:
![]()
到此,pλ(y|x)就是最大熵模型的一般形式。
之后,求解对偶问题外部的极大化问题max屮(λ),将其解记为λ*,即:λ* = argmax屮(λ)。
好了,了解了上面的过程,我们就可以总结出最大熵模型的一般形式了,其公式如下:

这里x∈Rn是输入,y∈{1, 2, …, K}是输出,λ∈Rn是权值向量,fi(x, y),i = 1, 2, …, n是任意实值特征函数。
最大熵模型与逻辑斯蒂回归模型有类似的形势,它们又称为对数线性模型。
模型的学习就是在给定的训练数据条件下对模型进行极大似然估计或正则化的极大似然估计。
最大熵模型的例子
输入:

求解:
最大熵模型
解:
按照最优化问题的习惯,我们将最大值问题改写为等价的求最小值问题,即:
求:![]()
因为只有两个约束条件,所以引进两个拉格朗日乘子λ0,λ1,然后定义拉格朗日函数:
![]()
根据拉格朗日的对偶性,可以通过求解对偶最优化问题得到原始最优化问题的解,所以求解:
maxλminpL(P,λ)
首先求解L(P, λ) 关于P的极小化问题。为此,求偏导数:

另各偏导数等于0,解得:
P(y1)= P(y2) = exp(-λ1 - λ0 - 1)
P(y3)= P(y4) = P(y5) = exp(-λ0 - 1)
将解代入拉格朗日函数得:
![]()
在求解L(Pλ,λ) 关于λ 的极大化问题,即:
![]()
于是对L(Pλ,λ),另其对λ0,λ1的偏导数为0,得到
exp(-λ1- λ0 - 1) = 3/20
exp(-λ0- 1) = 7/30
最后就得到要求的概率分布为:
P(y1)= P(y2) = 3/20
P(y3)= P(y4) = P(y5) = 7/30
参考:
http://blog.csdn.net/v_july_v/article/details/40508465?utm_source=tuicool&utm_medium=referral