查询:
(1)where子句
select name from 表名 where 表达式
select name from 表名 where name like 'Nokia%‘; //再次强调like 模糊匹配只有%和_,分别表示多个个一个,所以正则表达式更强大!
(2)group子句
一般用在统计场合。和聚合函数一起用。
select max(shop_price) from goods; //查出shop_price最大的那个
group命令:
select cat_id,max(shop_price) from goods group by cat_id; //按cat_id分组,把每一组价格最大的拿出来,并且查询显示的形式为cat_id。如图:

select min(shop_price) from goods; 最小
select avg(shop_price) from goods; 平均
select sum(shop_price) from goods; 商品价格
select count(*) from goods; 统计一共多少行
select cat_id,count(*) from goods group by cat_id; 统计每个cat_id下面有多少商品 COUNT是统计行数用的
select goods_id,goods_name, market_price-shop_price from goods; 每个market_price-shop_price的结果
select cat_id,sum(shop_price*goods_number) from goods group by cat_id; 以cat_id分栏目,计算每个栏目的乘积
可以给列或计算结果取别名,用as:

取别名注意AS要位于FROM之前,否则不起作用。
(3)having子句
由于where在select时对表文件查询产生一个中间结果,如果要对结果进行进一步的筛选,就用到了having。
所以
如果写一个select语句where在前having在后。
select goods_id,cat_id,market_price-shop_price from goods where cat_id > 5 having goods_id > 10; //简单用法
select goods_id,cat_id,market_price-shop_price as sheng from goods where cat_id > 5 having sheng > 100; //和as结合
出一道题,查询两门及两门以上不及格者的平均成绩。 (查的是这类人的平均成绩,不用子查询,不用左连接)
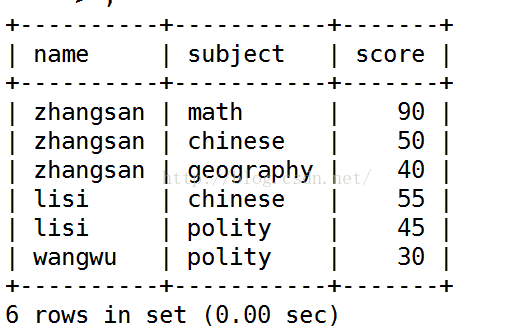
表如图:
步骤:1.先查询每个人挂科情况,利用(score<60)做相当于布尔值判定:
2.计算每个人挂科数目的累加数目,以及所有成绩的平均值
3.使用having筛选出结果:
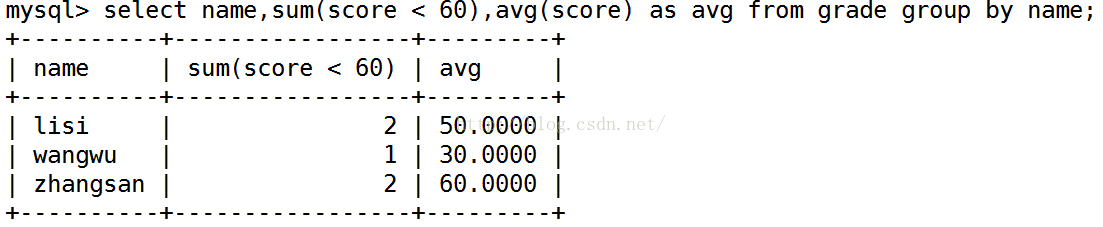
所以其实只有一句就可以了:
select name,sum(score < 60) as guake, avg(score) as avg from grade group by name having guake >= 2;
(4)order by子句
功能:俺一个或多个字段对查询结果进行排序。
按照价格排序:
select goods_id,cat_id,goods_name,shop_price from goods order by shop_price;
升序也可以显示声明,可以用asc,不过一般不用。
排序默认是升序的,需要降序排列必须显示声明:
select goods_id,cat_id,goods_name,shop_price from goods order by shop_price desc;
多重排序:
select goods_id,cat_id,goods_name,shop_price from goods order by cat_id, shop_price; 先按栏目号cat_id排列,同栏目号的按价格排列
也可混合升序或者降序。
(5)limit 子句
limit子句的格式是:limiit [offset] N,如果不写相当于limit N,此时offset=0
select goods_id,goods_name from goods limit 1; 限制查询数目为1
5个子句是有顺序要求的,先后是:WHERE,GROUP BY, HAVING, ORDER BY,LIMIT