吴恩达深度学习笔记(33)-带你进一步了解Dropout
理解 dropout(Understanding Dropout)
Dropout可以随机删除网络中的神经单元,他为什么可以通过正则化发挥如此大的作用呢?
直观上理解:不要依赖于任何一个特征,因为该单元的输入可能随时被清除,因此该单元通过这种方式传播下去,并为单元的四个输入增加一点权重,通过传播所有权重,dropout将产生收缩权重的平方范数的效果,和之前讲的L2正则化类似;
实施dropout的结果实它会压缩权重,并完成一些预防过拟合的外层正则化;L2对不同权重的衰减是不同的,它取决于激活函数倍增的大小。
总结一下,dropout的功能类似于L2正则化,与L2正则化不同的是应用方式不同会带来一点点小变化,甚至更适用于不同的输入范围。

第二个直观认识是,我们从单个神经元入手,如图,这个单元的工作就是输入并生成一些有意义的输出。
通过dropout,该单元的输入几乎被消除,有时这两个单元会被删除,有时会删除其它单元,就是说,用紫色圈起来的这个单元,它不能依靠任何特征,因为特征都有可能被随机清除,或者说该单元的输入也都可能被随机清除。
但我不愿意把所有赌注都放在一个节点上,不愿意给任何一个输入加上太多权重,因为它可能会被删除,因此该单元将通过这种方式积极地传播开,并为单元的四个输入增加一点权重,通过传播所有权重,dropout将产生收缩权重的平方范数的效果,和我们之前讲过的L2正则化类似,实施dropout的结果是它会压缩权重,并完成一些预防过拟合的外层正则化。
事实证明,dropout被正式地作为一种正则化的替代形式,L2对不同权重的衰减是不同的,它取决于倍增的激活函数的大小。
总结一下,dropout的功能类似于L2正则化,与L2正则化不同的是,被应用的方式不同,dropout也会有所不同,甚至更适用于不同的输入范围。
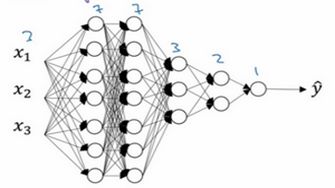
实施dropout的另一个细节是,这是一个拥有三个输入特征的网络,其中一个要选择的参数是keep-prob,它代表每一层上保留单元的概率。
所以不同层的keep-prob也可以变化。第一层,矩阵W([1])是7×3,第二个权重矩阵W([2])是7×7,第三个权重矩阵W([3])是3×7,以此类推,W([2])是最大的权重矩阵,因为W^([2])拥有最大参数集,即7×7,为了预防矩阵的过拟合,对于这一层,我认为这是第二层,它的keep-prob值应该相对较低,假设是0.5。对于其它层,过拟合的程度可能没那么严重,它们的keep-prob值可能高一些,可能是0.7,这里是0.7。如果在某一层,我们不必担心其过拟合的问题,那么keep-prob可以为1,为了表达清除,我用紫色线笔把它们圈出来,每层keep-prob的值可能不同。
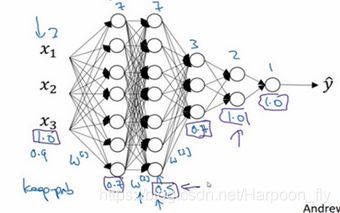
注意keep-prob的值是1,意味着保留所有单元,并且不在这一层使用dropout,对于有可能出现过拟合,且含有诸多参数的层,我们可以把keep-prob设置成比较小的值,以便应用更强大的dropout,有点像在处理L2正则化的正则化参数λ,我们尝试对某些层施行更多正则化,从技术上讲,我们也可以对输入层应用dropout,我们有机会删除一个或多个输入特征,虽然现实中我们通常不这么做,keep-prob的值为1,是非常常用的输入值,也可以用更大的值,或许是0.9。但是消除一半的输入特征是不太可能的,如果我们遵守这个准则,keep-prob会接近于1,即使你对输入层应用dropout。
总结一下,如果你担心某些层比其它层更容易发生过拟合,可以把某些层的keep-prob值设置得比其它层更低,缺点是为了使用交叉验证,你要搜索更多的超级参数,
另一种方案是在一些层上应用dropout,而有些层不用dropout,应用dropout的层只含有一个超级参数,就是keep-prob。
结束前分享两个实施过程中的技巧,实施dropout,在计算机视觉领域有很多成功的第一次。计算视觉中的输入量非常大,输入太多像素,以至于没有足够的数据,所以dropout在计算机视觉中应用得比较频繁,有些计算机视觉研究人员非常喜欢用它,几乎成了默认的选择,但要牢记一点,dropout是一种正则化方法,它有助于预防过拟合,因此除非算法过拟合,不然我是不会使用dropout的,所以它在其它领域应用得比较少,主要存在于计算机视觉领域,因为我们通常没有足够的数据,所以一直存在过拟合,这就是有些计算机视觉研究人员如此钟情于dropout函数的原因。直观上我认为不能概括其它学科。

dropout一大缺点就是代价函数J不再被明确定义,每次迭代,都会随机移除一些节点,
如果再三检查梯度下降的性能,实际上是很难进行复查的。定义明确的代价函数J每次迭代后都会下降,因为我们所优化的代价函数J实际上并没有明确定义,或者说在某种程度上很难计算,所以我们失去了调试工具来绘制这样的图片。
我通常会关闭dropout函数,将keep-prob的值设为1,运行代码,确保J函数单调递减。然后打开dropout函数,希望在dropout过程中,代码并未引入bug。我觉得你也可以尝试其它方法,虽然我们并没有关于这些方法性能的数据统计,但你可以把它们与dropout方法一起使用。