Pytorch 学习率衰减 lr_scheduler
torch.optim.lr_scheduler 提供了一些基于 epoch 调整学习率的方法,基本使用方法如下:
optimizer = torch.optim.SGD(model.parameters(), lr=1e-2, momentum=0.9, weight_decay=1e-5)
scheduler = torch.optim.lr_scheduler.xxx()
for epoch in range(epochs):
train(...)
optimizer.step()
scheduler.step()PyTorch 1.1.0 之前,scheduler.step() 应该在 optimizer.step() 之前调用。现在这么做则会跳过学习率更新的第一个值。
torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda, last_epoch=-1)
给每一组参数的学习率分别设置为初始lr乘以给定的函数。当last_epoch=-1时,将初始lr设置为lr。
optimizer = torch.optim.SGD([{'params': weight_p, 'weight_decay':5e-3},
{'params': bias_p, 'weight_decay':0},]
lr=1e-2, momentum=0.9)
lambda1 = lambda epoch: epoch // 30
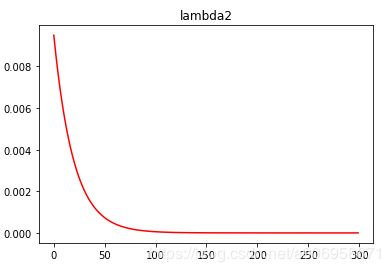
lambda2 = lambda epoch: 0.95 ** epoch
scheduler = LambdaLR(optimizer, lr_lambda=[lambda1, lambda2])
for epoch in range(100):
train(...)
optimizer.step()
scheduler.step() 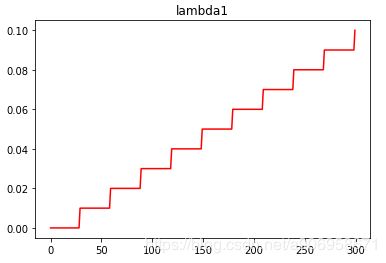
MultiplicativeLR(optimizer, lr_lambda, last_epoch=-1)
每组参数的学习率乘以指定函数中给定的因子。当last_epoch=-1时,将初始lr设置为lr。
optimizer = torch.optim.SGD([{'params': weight_p, 'weight_decay':5e-3},
{'params': bias_p, 'weight_decay':0},]
lr=1e-2, momentum=0.9)
lambda1 = lambda epoch: 0.95
lambda2 = lambda epoch: 0.85
scheduler = MultiplicativeLR(optimizer, lr_lambda=[lambda1, lambda2])
for epoch in range(100):
train(...)
optimizer.step()
scheduler.step()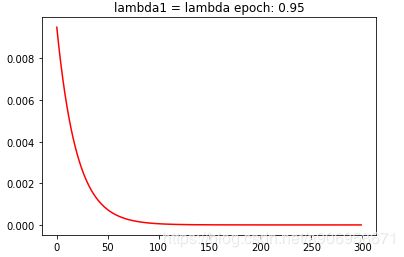
StepLR(optimizer, step_size, gamma=0.1, last_epoch=-1)
在每个 step_size 个epoch,每组参数的学习率都以 gamma 倍衰减。这种衰减可能与此 scheduler 之外的其他对学习率的更改同时发生。当last_epoch=-1时,将初始lr设置为lr。
# Assuming optimizer uses lr = 0.05 for all groups
# lr = 0.05 if epoch < 30
# lr = 0.005 if 30 <= epoch < 60
# lr = 0.0005 if 60 <= epoch < 90
# ...
scheduler = StepLR(optimizer, step_size=30, gamma=0.1)
for epoch in range(100):
train(...)
scheduler.step()

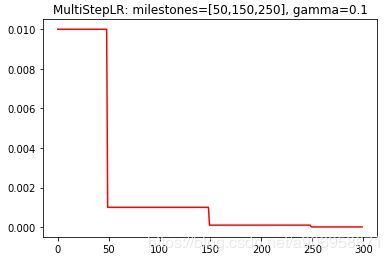
MultiStepLR(optimizer, milestones, gamma=0.1, last_epoch=-1)
当 epoch 达到 milestones 其中一个值时,每组参数的学习率将以 gamma 衰减。这种衰减可能与此 scheduler 之外的其他对学习率的更改同时发生。当last_epoch=-1时,将初始lr设置为lr。milestones 是一个包含 epoch 值的递增列表。
# Assuming optimizer uses lr = 0.05 for all groups
# lr = 0.05 if epoch < 30
# lr = 0.005 if 30 <= epoch < 80
# lr = 0.0005 if epoch >= 80
scheduler = MultiStepLR(optimizer, milestones=[30,80], gamma=0.1)
for epoch in range(100):
train(...)
scheduler.step()
ExponentialLR(optimizer, gamma, last_epoch=-1)
以指数衰减的形式降低每组参数的学习率: lr = lr * (gamma ** epoch), 相当于上面 LambdaLR 中的 lambda2。当last_epoch=-1时,将初始lr设置为lr。

CosineAnnealingLR(optimizer, T_max, eta_min=0, last_epoch=-1)
使用余弦退火策略改变学习率。T_max代表1/2个cos周期所对应的epoch值,eta_min代表最小学习率。简化的版本是根据余弦函数将学习率从初始值降低到0(左图)。
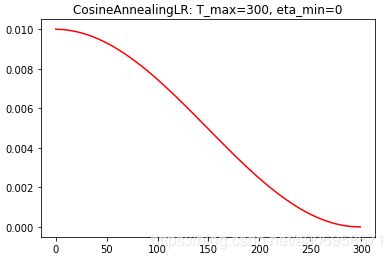
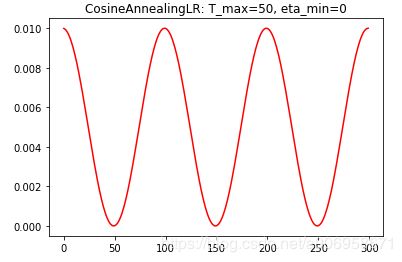
ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=10, verbose=False, threshold=0.0001, threshold_mode='rel', cooldown=0, min_lr=0, eps=1e-08)
当传给函数的指标不再变好时,降低学习率。一旦学习停滞不前,模型通常会受益于将学习率降低2-10倍。这个 scheduler 读取一个指标,如果在 patience 个 epoch 内该指标没有变得更好,学习率就会降低。
- mode:min或者max。在 min 模式下,当检测的指标(loss等)在 patience 个 epoch 内在不再减少时,lr将减小;在 max 模式下,当检测的指标(acc等)在 patience 个 epoch 内不再变大时,lr将减小;
- factor:降低学习率的因子。new_lr = lr * factor,默认值为0.1。
- patience:整数,可以忍受没有改进的epoch的数量,之后学习率将降低。默认值为10。
- verbose :布尔变量,如果为真,则当学习率有更新时向stdout输出一条消息。默认值为False。
- threshold:只关注超过阈值的变化。默认为1e-4。
- threshold_mode:有rel和abs两种阈值计算模式。rel模式:max模式下指标要超过best(1+threshold),min模式下指标要小于best(1-threshold);abs模式:max模式下指标要超过best+threshold,min模式下指标要小于best-threshold。默认为rel模式。
- cooldown:减少lr后,等待指定epoch再进行检测,防止lr下降过快。默认为0。
- min_lr:最小的允许lr,默认为0。
- eps:对lr的衰减最小值,如果新旧lr之间的差异小于eps,则忽略此次更新。默认值为1e-8。
optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9)
scheduler = ReduceLROnPlateau(optimizer, 'min')
for epoch in range(10):
train(...)
val_loss = validate(...)
# Note that step should be called after validate()
scheduler.step(val_loss)